JIS X 0201
 JIS X 0201 8-bit code page | |
| MIME / IANA |
8-bit: JIS_X02017-bit Roman: JIS_C6220-1969-ro7-bit Kana: JIS_C6220-1969-jp |
|---|---|
| Alias(es) |
JIS C 6220 8-bit: csHalfWidthKatakana Roman: ISO646-JP, iso-ir-14 Kana: iso-ir-13, x0201-7 |
| Language(s) | Japanese (basic support), English |
| Standard | JIS X 0201:1969 |
| Classification | ISO 646, Extended ISO 646 |
| Preceded by | Wabun code |
| Succeeded by | Shift JIS |
JIS X 0201, a Japanese Industrial Standard developed in 1969 (then called JIS C 6220 until the JIS category reform), was the first Japanese electronic character set to become widely used. It is either 7-bit encoding or 8-bit encoding, although 8-bit encoding is dominant for modern use. The full name of this standard is 7-bit and 8-bit coded character sets for information interchange (7ビット及び8ビットの情報交換用符号化文字集合).
The first 96 codes comprise an ISO 646 variant, mostly following ASCII with some differences, while the second 96 character codes represent the phonetic Japanese katakana signs. Since the encoding does not provide any way to express hiragana or kanji, it is only capable of expressing simplified written Japanese. Nevertheless, it is possible to express, at least phonetically, the full range of sounds in the language. In the 1980s, this was acceptable for media such as text mode computer terminals, telegrams, receipts or other electronically handled data.
JIS X 0201 was supplanted by subsequent encodings such as Shift JIS (which combines this standard and JIS X 0208) and later Unicode.
Implementation details
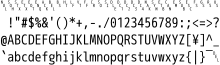

The first 96 codes in JIS comprise a Japanese variant of ISO 646, or ASCII with backslash (\) and tilde (~) replaced by yen (¥) and overline (‾),[1] while the second 96 codes consist mainly of katakana. Control characters are specified in JIS X 0211.
In the 7-bit format, the shift out control character (0x0E) switches to the Kana set and shift in (0x0F) switches to the Roman set.[2][3] In the 8-bit format, given in the chart below, bytes with the most significant bit set (i.e. 0x80–0xFF) are used for the Kana set and bytes with it unset (i.e. 0x00–0x7F) are used otherwise.
The substitution of the yen symbol for backslash can make paths on DOS and Windows-based computers with Japanese support display strangely, like "C:¥Program Files¥", for example.[4] Another similar problem is C programming language's control characters of string literals, like printf("Hello, world.¥n");.
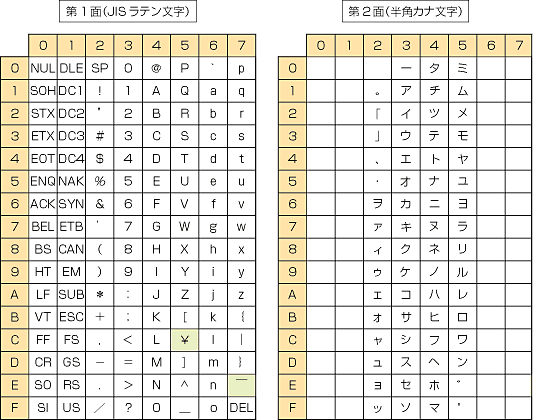
Codepage layout
Letter Number Punctuation Symbol Other undefined
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0_ | ||||||||||||||||
| 1_ | ||||||||||||||||
| 2_ | SP 0020 32 |
! 0021 33 |
" 0022 34 |
# 0023 35 |
$ 0024 36 |
% 0025 37 |
& 0026 38 |
' 0027 39 |
( 0028 40 |
) 0029 41 |
* 002A 42 |
+ 002B 43 |
, 002C 44 |
- 002D 45 |
. 002E 46 |
/ 002F 47 |
| 3_ | 0 0030 48 |
1 0031 49 |
2 0032 50 |
3 0033 51 |
4 0034 52 |
5 0035 53 |
6 0036 54 |
7 0037 55 |
8 0038 56 |
9 0039 57 |
: 003A 58 |
; 003B 59 |
< 003C 60 |
= 003D 61 |
> 003E 62 |
? 003F 63 |
| 4_ | @ 0040 64 |
A 0041 65 |
B 0042 66 |
C 0043 67 |
D 0044 68 |
E 0045 69 |
F 0046 70 |
G 0047 71 |
H 0048 72 |
I 0049 73 |
J 004A 74 |
K 004B 75 |
L 004C 76 |
M 004D 77 |
N 004E 78 |
O 004F 79 |
| 5_ | P 0050 80 |
Q 0051 81 |
R 0052 82 |
S 0053 83 |
T 0054 84 |
U 0055 85 |
V 0056 86 |
W 0057 87 |
X 0058 88 |
Y 0059 89 |
Z 005A 90 |
[ 005B 91 |
¥ 00A5 92 |
] 005D 93 |
^ 005E 94 |
_ 005F 95 |
| 6_ | ` 0060 96 |
a 0061 97 |
b 0062 98 |
c 0063 99 |
d 0064 100 |
e 0065 101 |
f 0066 102 |
g 0067 103 |
h 0068 104 |
i 0069 105 |
j 006A 106 |
k 006B 107 |
l 006C 108 |
m 006D 109 |
n 006E 110 |
o 006F 111 |
| 7_ | p 0070 112 |
q 0071 113 |
r 0072 114 |
s 0073 115 |
t 0074 116 |
u 0075 117 |
v 0076 118 |
w 0077 119 |
x 0078 120 |
y 0079 121 |
z 007A 122 |
{ 007B 123 |
| 007C 124 |
} 007D 125 |
‾ 203E 126 |
|
| 8_ | ||||||||||||||||
| 9_ | ||||||||||||||||
| A_ | 。 FF61 161 |
「 FF62 162 |
」 FF63 163 |
、 FF64 164 |
・ FF65 165 |
ヲ FF66 166 |
ァ FF67 167 |
ィ FF68 168 |
ゥ FF69 169 |
ェ FF6A 170 |
ォ FF6B 171 |
ャ FF6C 172 |
ュ FF6D 173 |
ョ FF6E 174 |
ッ FF6F 175 | |
| B_ | ー FF70 176 |
ア FF71 177 |
イ FF72 178 |
ウ FF73 179 |
エ FF74 180 |
オ FF75 181 |
カ FF76 182 |
キ FF77 183 |
ク FF78 184 |
ケ FF79 185 |
コ FF7A 186 |
サ FF7B 187 |
シ FF7C 188 |
ス FF7D 189 |
セ FF7E 190 |
ソ FF7F 191 |
| C_ | タ FF80 192 |
チ FF81 193 |
ツ FF82 194 |
テ FF83 195 |
ト FF84 196 |
ナ FF85 197 |
ニ FF86 198 |
ヌ FF87 199 |
ネ FF88 200 |
ノ FF89 201 |
ハ FF8A 202 |
ヒ FF8B 203 |
フ FF8C 204 |
ヘ FF8D 205 |
ホ FF8E 206 |
マ FF8F 207 |
| D_ | ミ FF90 208 |
ム FF91 209 |
メ FF92 210 |
モ FF93 211 |
ヤ FF94 212 |
ユ FF95 213 |
ヨ FF96 214 |
ラ FF97 215 |
リ FF98 216 |
ル FF99 217 |
レ FF9A 218 |
ロ FF9B 219 |
ワ FF9C 220 |
ン FF9D 221 |
゙ FF9E 222 |
゚ FF9F 223 |
| E_ | ||||||||||||||||
| F_ | ||||||||||||||||
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F |
Variants and extensions
Shift JIS
IBM's implementations
Code page 897 is IBM's implementation of the 8-bit form of JIS X 0201. It includes several additional graphical characters in the C0 control characters area, and the code points in question may be used as control characters or graphical characters depending on the context,[5] similarly in concept to OEM-US, but with different graphical characters. The C0 rows are shown below.
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0_ | NUL 0000 0 |
SOH/╔ 0001/2554 1 |
STX/╗ 0002/2557 2 |
ETX/╚ 0003/255A 3 |
EOT/╝ 0004/255D 4 |
ENQ/║ 0005/2551 5 |
ACK/═ 0006/2550 6 |
BEL/↓ 0007/FFEC 7 |
BS 0008 8 |
HT/○ 0009/FFEE 9 |
LF 000A 10 |
VT/〿 000B/303F 11 |
FF 000C 12 |
CR 000D 13 |
SO/■ 000E/FFED 14 |
SI/☼ 000F/263C 15 |
| 1_ | DLE/╬ 0010/256C 16 |
DC1 0011 17 |
DC2/↕ 0012/2195 18 |
DC3 0013 19 |
DC4/▓ 0014/2593 20 |
NAK/╩ 0015/2569 21 |
SYN/╦ 0016/2566 22 |
ETB/╣ 0017/2563 23 |
CAN 0018 24 |
EM/╠ 0019/2560 25 |
FS/░ 001C/2591 26 |
ESC/↵ 001B/21B5 27 |
DEL/↑ 007F/FFEA 28 |
GS/│ 001D/FFE8 29 |
RS/→ 001E/FFEB 30 |
US/← 001F/FFE9 31 |
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F |
IBM also implements the 7-bit Roman set of JIS X 0201 as Code page 895[11] and the 7-bit Kana set as Code page 896 for use as ISO 2022 or EUC-JP code-sets. Code page 896, in addition to standard JIS X 0201 assignments, defines five additional assignments, shown below.[12] Although use of these extended characters is not permitted by the associated CCSID 896,[13] they are permitted by the alternative CCSID 4992.[14]
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 6_ | ¢ 00A2 96 |
£ 00A3 97 |
¬ 00AC 98 |
\ 005C 99 |
~ 007E 100 |
|||||||||||
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F |
IBM's Code page 1041 is an extended version of Code page 897, encoding these five IBM extended[15] characters in alternative locations which are compatible with Shift JIS (respectively 0x80, 0xA0, 0xFD, 0xFE and 0xFF).[16]
IBM's Code page 903 is encoded for use as the single byte component of certain simplified Chinese character encodings.[17] Despite this, it follows ISO 646-JP / the Roman half of JIS X 0201, in that it replaces the ASCII backslash 0x5C (rather than the ASCII dollar sign 0x24 as in GB 1988 / ISO 646-CN) with the yen/yuan sign. It also uses the same C0 replacement graphics as code page 897.[18] The closely related Code page 904 is encoded for use as the single byte component of certain traditional Chinese character encodings,[19] and differs in following ASCII instead.[20]
Others


References
- ↑ "3.1.1 Details of Problems". Problems and Solutions for Unicode and User/Vendor Defined Characters. The Open Group Japan. Archived from the original on 1999-02-03.
- ↑ ISO-IR 013: The Japanese KATAKANA graphic set of characters (PDF), Information Technology Standards Commission of Japan
- ↑ ISO-IR 014: The Japanese Roman graphic set of characters (PDF), Information Technology Standards Commission of Japan
- ↑ Kaplan, Michael S. (2005-09-17). "When is a backslash not a backslash?".
- ↑ "Code page identifiers - CP 00897". IBM Globalization. IBM.
- ↑ "CP00897.pdf" (PDF). IBM.
- ↑ "CP00897.txt". IBM.
- ↑ "Converter Explorer - ibm-943_P130-1999". ICU Demonstration. International Components for Unicode.
- ↑ "Coded character set identifiers - CCSID 943". IBM Globalization. IBM.
- ↑ Graphics are listed per CP00897.pdf and CP00897.txt provided by IBM.[6][7] Controls are listed per the ibm-943_P130-1999 codec provided by IBM to International Components for Unicode[8] (IBM-943 is a Code page 897 superset).[9] These do not match ASCII control character mappings at every point.
- ↑ "CP00895.pdf" (PDF). IBM. Archived from the original on 2017-12-07.
- 1 2 "CP00896.pdf" (PDF). IBM.
- ↑ "CCSID 896". IBM.
- ↑ "CCSID 4992". IBM.
- ↑ "11.2 - IBM Extended SBCS Set", IBM Japanese Graphic Character Set for Extended UNIX Code (EUC) (PDF), IBM, p. 315
- ↑ "CP01041.pdf" (PDF). IBM.
- ↑ "Code page 903". IBM.
- ↑ "CP00903.pdf" (PDF). IBM.
- ↑ "Code page 904". IBM.
- ↑ "CP00904.pdf" (PDF). IBM.
External links
{kind=link}
| Early telecommunications |
|
|---|---|
| ISO/IEC 8859 | |
| Bibliographic use | |
| National standards | |
| EUC | |
| ISO/IEC 2022 | |
| MacOS code pages ("scripts") |
|
| DOS code pages |
|
| IBM AIX code pages | |
| IBM Apple MacIntosh emulations | |
| IBM Adobe emulations | |
| IBM DEC emulations | |
| IBM HP emulations | |
| Windows code pages | |
| EBCDIC code pages |
|
| Platform specific |
|
| Unicode / ISO/IEC 10646 | |
| TeX typesetting system | |
| Miscellaneous code pages | |
| Related topics | |