Extended Unix Code
Extended Unix Code (EUC) is a multibyte character encoding system used primarily for Japanese, Korean, and simplified Chinese.
The structure of EUC is based on the ISO-2022 standard, which specifies a way to represent character sets containing a maximum of 94 characters, or 8836 (942) characters, or 830584 (943) characters, as sequences of 7-bit codes. Only ISO-2022 compliant character sets can have EUC forms. Up to four coded character sets (referred to as G0, G1, G2, and G3 or as code sets 0, 1, 2, and 3) can be represented with the EUC scheme.
G0 is almost always an ISO-646 compliant coded character set such as US-ASCII, ISO 646:KR (KS X 1003) or ISO 646:JP (the lower half of JIS X 0201) that is invoked on GL (i.e. with the most significant bit cleared). An exception from US-ASCII is that 0x5C (backslash in US-ASCII) is often used to represent a Yen sign in EUC-JP (see below) and a Won sign in EUC-KR.
To get the EUC form of an ISO-2022 character, the most significant bit of each 7-bit byte of the original ISO 2022 codes is set (by adding 128 to each of these original 7-bit codes); this allows software to easily distinguish whether a particular byte in a character string belongs to the ISO-646 code or the ISO-2022 (EUC) code.
The most commonly used EUC codes are variable-width encodings with a character belonging to G0 (ISO-646 compliant coded character set) taking one byte and a character belonging to G1 (taken by a 94x94 coded character set) represented in two bytes. The EUC-CN form of GB2312 and EUC-KR are examples of such two-byte EUC codes. EUC-JP includes characters represented by up to three bytes whereas a single character in EUC-TW can take up to four bytes.
Modern applications are more likely to use UTF-8, which supports all of the glyphs of the EUC codes, and more, and is generally more portable with fewer vendor deviations and errors.
EUC-CN
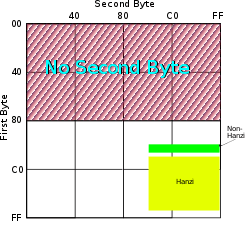 | |
| MIME / IANA | GB2312 |
|---|---|
| Alias(es) | csGB2312 |
| Language(s) | Simplified Chinese, English, Russian |
| Standard | GB 2312 (1980) |
| Classification | Extended ASCII, Variable-width encoding, CJK encoding, EUC |
| Extends | US-ASCII |
| Extensions | 748, GBK, GB18030, x-mac-chinesesimp |
| Transforms / Encodes | GB 2312 |
| Succeeded by | GBK, GB18030 |
EUC-CN[1] is the usual way to use the GB2312 standard for simplified Chinese characters. Unlike the case of Japanese, the ISO-2022 form of GB2312 is not normally used, though a variant form called HZ was sometimes used on USENET. An ASCII character is represented in its usual encoding. A character from GB 2312 is represented by two bytes in the range 0xA1 – 0xFE.
Related encoding systems
748 code
An encoding related to EUC-CN is the "748" code used in the WITS typesetting system developed by Beijing's Founder Technology (now obsoleted by its newer FITS typesetting system). The 748 code contains all of GB2312, but is not ISO 2022–compliant and therefore not a true EUC code. (It uses an 8-bit lead byte but distinguishes between a second byte with its most significant bit set and one with its most significant bit cleared, and is therefore more similar in structure to Big5 and other non–ISO 2022–compliant DBCS encoding systems.) The non-GB2312 portion of the 748 code contains traditional and Hong Kong characters and other glyphs used in newspaper typesetting.
GBK and GB18030
GBK is an extension to GB2312. It defines an extended form of the EUC-CN encoding capable of representing a larger array of CJK characters sourced largely from Unicode 1.1, including traditional Chinese characters and characters used only in Japanese. It is not, however, a true EUC code, because ASCII bytes may appear as trail bytes (and C1 bytes, not limited to the single shifts, may appear as lead or trail bytes), due to a larger encoding space being required.
Variants of GBK are implemented by Windows code page 936 (the Microsoft Windows code page for simplified Chinese), and by IBM's code page 1386.
The Unicode-based GB18030 character encoding defines an extension of GBK capable of encoding the entirety of Unicode. However, Unicode encoded as GB18030 is a variable-width encoding which may use up to four bytes per character, due to an even larger encoding space being required. Being an extension of GBK, it is a superset of EUC-CN but is not itself a true EUC code. Being a Unicode encoding, its repertoire is identical to that of other Unicode transformation formats such as UTF-8.
Others
Other EUC-CN extensions include the Mac OS Chinese Simplified script[1] (known as Code page 10008 or x-mac-chinesesimp).[2]
EUC-JP
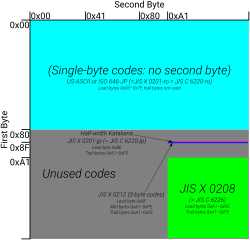 | |
| MIME / IANA | EUC-JP |
|---|---|
| Alias(es) | Unixized JIS (UJIS), csEUCPkdFmtJapanese |
| Language(s) | Japanese, English, Russian |
| Classification | Extended ISO 646, Variable-width encoding, CJK encoding, EUC |
| Extends | US-ASCII or ISO 646:JP |
| Transforms / Encodes | JIS X 0208, JIS X 0212, JIS X 0201 |
| Succeeded by | EUC-JISx0213 |
| Alias(es) | EUC-JISx0213 |
|---|---|
| Language(s) | Japanese, Ainu, English, Russian |
| Standard | JIS X 0213 |
| Classification | Extended ASCII, Variable-width encoding, CJK encoding, EUC |
| Extends | US-ASCII |
| Transforms / Encodes | JIS X 0213, JIS X 0201 (Kana) |
| Preceded by | EUC-JP |
EUC-JP is a variable-width encoding used to represent the elements of three Japanese character set standards, namely JIS X 0208, JIS X 0212, and JIS X 0201. 0.1% of all web pages use EUC-JP since August 2018.[3] Other names for this encoding include Unixized JIS (or UJIS) and AT&T JIS.[4] It is called Code page 954 by IBM.
This encoding scheme allows the easy mixing of 7-bit ASCII and 8-bit Japanese without the need for the escape characters employed by ISO-2022-JP, which is based on the same character set standards, and without ASCII bytes appearing as trail bytes (unlike Shift JIS).
A related and partially compatible encoding, called EUC-JISx0213 or EUC-JIS-2004, encodes JIS X 0201 and JIS X 0213[5] (similarly to Shift_JISx0213, its Shift_JIS-based counterpart).
Compared to EUC-CN or EUC-KR, EUC-JP did not become as widely adopted on PC and Macintosh systems in Japan, which used Shift JIS or its extensions (Windows code page 932 on Microsoft Windows, and MacJapanese on classic Mac OS), although it became heavily used by Unix or Unix-like operating systems (except for HP-UX). Therefore, whether Japanese web sites use EUC-JP or Shift_JIS often depends on what OS the author uses.
Vendor extensions to EUC-JP were usually allocated within the individual code sets,[6] as opposed to using invalid EUC sequences (as in popular extensions of EUC-CN and EUC-KR). Characters are encoded as follows:
- As an EUC/ISO 2022 compliant encoding, the C0 control characters, space and DEL are represented as in ASCII.
- A graphical character from ASCII (code set 0) is represented as its usual one-byte representation, in the range 0x21 – 0x7E. While some variants of EUC-JP encode the lower half of JIS X 0201 here, most encode ASCII,[7] including the W3C/WHATWG Encoding standard used by HTML5,[8] and so does EUC-JIS-2004.[5] While this means that 0x5C is typically mapped to Unicode as U+005C REVERSE SOLIDUS (the ASCII backslash), U+005C may be displayed as a Yen sign by certain Japanese-locale fonts, e.g. on Microsoft Windows, for compatibility with the lower half of JIS X 0201.[9][10]
- A character from JIS X 0208 (code set 1) is represented by two bytes, both in the range 0xA1 – 0xFE. This differs from the ISO-2022-JP representation by having the high bit set. This code set may also contain vendor extensions in some EUC-JP variants. In EUC-JIS-2004, the first plane of JIS X 0213 is encoded here, which is effectively a superset of standard JIS X 0208.[5]
- A character from the upper half of JIS X 0201 (half-width kana, code set 2) is represented by two bytes, the first being 0x8E, the second being the usual JIS X 0201 representation in the range 0xA1 – 0xDF. This set may contain IBM vendor extensions in some variants.
- A character from JIS X 0212 (code set 3) is represented in EUC-JP by three bytes, the first being 0x8F, the following two being in the range 0xA1 – 0xFE, i.e. with the high bit set. In addition to standard JIS X 0212, code set 3 may also contain IBM vendor extensions (in rows 83 and 84) in some EUC-JP variants.[6] In EUC-JIS-2004, the second plane of JIS X 0213 is encoded here,[5] which does not collide with the allocated rows in standard JIS X 0212.[11] Some implementations of EUC-JIS-2004, such as the one used by Python, allow both JIS X 0212 and JIS X 0213 plane 2 characters in this set.[11]
EUC-KR
 EUC-KR code structure | |
| MIME / IANA | EUC-KR |
|---|---|
| Alias(es) | Wansung, IBM-970 |
| Language(s) | Korean, English, Russian |
| Standard | KS X 2901 (KS C 5861) |
| Classification | Extended ISO 646, Variable-width encoding, CJK encoding, EUC |
| Extends | US-ASCII or ISO 646:KR |
| Extensions | Mac OS Korean, IBM-949, Unified Hangul Code (Windows-949) |
| Transforms / Encodes | KS X 1001 |
| Succeeded by | Unified Hangul Code (web standards) |
EUC-KR is a variable-width encoding to represent Korean text using two coded character sets, KS X 1001 (formerly KS C 5601)[12][13] and either ISO 646:KR (KS X 1003, formerly KS C 5636) or US-ASCII, depending on variant. KS X 2901 (formerly KS C 5861) stipulates the encoding and RFC 1557 dubbed it as EUC-KR. When used with ASCII, it is called Code page 970 by IBM.[14][15]
A character drawn from KS X 1001 (G1, code set 1) is encoded as two bytes in GR (0xA1-0xFE) and a character from KS X 1003 or US-ASCII (G0, code set 0) takes one byte in GL (0x21-0x7E).
0.3% of all web pages use EUC-KR in April 2016.[3] Including extensions, it is the most widely used legacy character encoding in Korea on all three major platforms (Unix-like OS, Windows and Mac), but its use has been very slowly decreasing as UTF-8 gains popularity, especially on Linux and Mac OS X. It is usually referred to as Wansung (완성) in Republic of Korea. The default Korean codepage for Windows, code page 949 (IBM's 1363), is a proprietary but upward compatible extension of EUC-KR referred to as Unified Hangeul Code (통합 완성형, Tonghab Wansunghyung). Mac Korean used in classic Mac OS is also compatible with EUC-KR.
As with most other encodings, UTF-8 is now preferred for new use, solving problems with consistency between platforms and vendors.
EUC-TW
EUC-TW is a variable-width encoding that supports US-ASCII and 16 planes of CNS 11643, each of which is 94x94. It is a rarely used encoding for traditional Chinese characters as used in Taiwan. Big5 is much more common.
- As an EUC/ISO 2022 encoding, the C0 control characters, ASCII space and DEL are encoded as in ASCII.
- A graphical character from US-ASCII (G0, code set 0) is encoded in GL as its usual single byte representation (0x21-0x7E).
- A character from CNS 11643 plane 1 (code set 1) is encoded as two bytes in GR (0xA1-0xFE).
- A character in plane 1 through 16 of CNS 11643 (code set 2) is encoded as four bytes:
- The first byte is always 0x8E (Single Shift 2).
- The second byte (0xA1-0xB0) indicates the plane, the number of which is obtained by subtracting 0xA0 from that byte.
- The third and fourth bytes are in GR (0xA1-0xFE).
Note that the plane 1 of CNS 11643 is encoded twice as code set 1 and a part of code set 2.
UTF-8 is becoming more common than EUC-TW, as with most code pages.
Packed versus fixed length form
The encodings described above (using bytes in 0x21-0x7E for code set 0, bytes in 0xA1-0xFE for code set 1, 0x8E followed by bytes in 0xA1-0xFE for code set 2 and 0x8F followed by bytes in 0xA1-0xFE for code set 3) are in a variable-width form referred to as the EUC packed format. This is the form usually labelled as EUC.[4]
Internal processing may make use of a fixed-length alternative form called the EUC complete two-byte format. This represents:[4]
- Code set 0 as two bytes in the range 0x21-0x7E (except that the first may be 0x00).
- Code set 1 as two bytes in the range 0xA0-0xFF (except that the first may be 0x80).
- Code set 2 as a byte in the range 0x20-0x7E (or 0x00) followed by a byte in the range 0xA0-0xFF.
- Code set 3 as a byte in the range 0xA0-0xFF (or 0x80) followed by a byte in the range 0x21-0x7E.
Initial bytes of 0x00 and 0x80 are used in cases where the code set uses only one byte. There is also a four-byte fixed length format.[4] These fixed length forms are suited to internal processing and are not usually encountered in interchange.
EUC-JP is registered with the IANA in both formats, the packed format as "EUC-JP" or "csEUCPkdFmtJapanese" and the fixed width format as "csEUCFixWidJapanese".[16] Only the packed format is included in the WHATWG Encoding Standard used by HTML5.[17]
See also
References
- 1 2 "Map (external version) from Mac OS Chinese Simplified encoding to Unicode 3.0 and later". Apple, Inc.
- ↑ "Encoding.WindowsCodePage Property - .NET Framework (current version)". MSDN. Microsoft.
- 1 2 "Historical trends in the usage of character encodings for websites". W3Techs.
- 1 2 3 4 Lunde, Ken (2008). CJKV Information Processing: Chinese, Japanese, Korean, and Vietnamese Computing. O'Reilly. pp. 242–244. ISBN 9780596800925.
- 1 2 3 4 "JIS X 0213 Code Mapping Tables". x0213.org.
- 1 2 "4.2 Review Process of Rules for Code Set Conversion Between eucJP-open and UCS". Problems and Solutions for Unicode and User/Vendor Defined Characters. The Open Group Japan. Archived from the original on 1999-02-03.
- ↑ "Ambiguities in conversion from Japanese EUC to Unicode (Non-Normative)". XML Japanese Profile. W3C.
- ↑ "EUC-JP decoder". Encoding Standard. WHATWG. "If byte is an ASCII byte, return a code point whose value is byte."
- ↑ "3.1.1 Details of Problems". Problems and Solutions for Unicode and User/Vendor Defined Characters. The Open Group Japan. Archived from the original on 1999-02-03.
- ↑ Kaplan, Michael S. (2005-09-17). "When is a backslash not a backslash?".
- 1 2 Chang, Hyeshik. "Readme for CJKCodecs". cPython. Python Software Foundation.
- ↑ "KS X 1001:1992" (PDF).
- ↑ "KS C 5601:1987" (PDF). 1988-10-01.
- ↑ "CCSID 970". IBM Globalization. IBM.
- ↑ "ibm-970_P110_P110-2006_U2 (alias euc-kr)". Converter Explorer - ICU Demonstration. International Components for Unicode.
- ↑ "Character Sets". IANA.
- ↑ "4.2. Names and labels". Encoding Standard. WHATWG.
External links
- EUC-JP codeset table (minus the ASCII and halfwidth parts)
- GB18030-2000 — The New Chinese National Standard
- The New Generation of Pre-Press Software in China—mentions the 748 code
- Description of the EUC-TW code (in Chinese)
- Manual page of EUC-JISX0213 in Perl Encode module
- International Register of Coded Character Sets to be Used With Escape Sequence— Section 2.4 (p.14f.) with the coded character sets of China, Japan, South Korea, North Korea and Taiwan (ISO/IEC)
- Chinese, Japanese, and Korean character set standards and encoding systems
| Early telecommunications |
|
|---|---|
| ISO/IEC 8859 | |
| Bibliographic use | |
| National standards | |
| EUC | |
| ISO/IEC 2022 | |
| MacOS code pages ("scripts") |
|
| DOS code pages |
|
| IBM AIX code pages | |
| IBM Apple MacIntosh emulations | |
| IBM Adobe emulations | |
| IBM DEC emulations | |
| IBM HP emulations | |
| Windows code pages | |
| EBCDIC code pages |
|
| Platform specific |
|
| Unicode / ISO/IEC 10646 | |
| TeX typesetting system | |
| Miscellaneous code pages | |
| Related topics | |