Negative binomial distribution
| Different texts adopt slightly different definitions for the negative binomial distribution. They can be distinguished by whether the support starts at k = 0 or at k = r, whether p denotes the probability of a success or of a failure, and whether r represents success or failure,[1] so it is crucial to identify the specific parametrization used in any given text. | |
|
Probability mass function 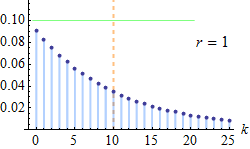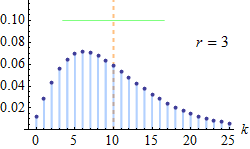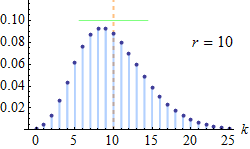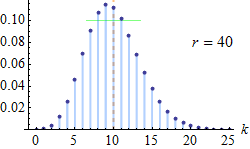 The orange line represents the mean, which is equal to 10 in each of these plots; the green line shows the standard deviation. | |
| Notation | |
|---|---|
| Parameters |
r > 0 — number of failures until the experiment is stopped (integer, but the definition can also be extended to reals) p ∈ (0,1) — success probability in each experiment (real) |
| Support | k ∈ { 0, 1, 2, 3, … } — number of successes |
| pmf | involving a binomial coefficient |
| CDF | the regularized incomplete beta function |
| Mean | |
| Mode | |
| Variance | |
| Skewness | |
| Ex. kurtosis | |
| MGF | |
| CF | |
| PGF | |
| Fisher information | |












In probability theory and statistics, the negative binomial distribution is a discrete probability distribution of the number of successes in a sequence of independent and identically distributed Bernoulli trials before a specified (non-random) number of failures (denoted r) occurs. For example, if we define a 1 as failure, all non-1s as successes, and we throw a die repeatedly until 1 appears the third time (r = three failures), then the probability distribution of the number of non-1s that appeared will be a negative binomial distribution.
The Pascal distribution (after Blaise Pascal) and Polya distribution (for George Pólya) are special cases of the negative binomial distribution. A convention among engineers, climatologists, and others is to use "negative binomial" or "Pascal" for the case of an integer-valued stopping-time parameter r, and use "Polya" for the real-valued case.
For occurrences of "contagious" discrete events, like tornado outbreaks, the Polya distributions can be used to give more accurate models than the Poisson distribution by allowing the mean and variance to be different, unlike the Poisson. "Contagious" events have positively correlated occurrences causing a larger variance than if the occurrences were independent, due to a positive covariance term.
Definition
Suppose there is a sequence of independent Bernoulli trials. Thus, each trial has two potential outcomes called "success" and "failure". In each trial the probability of success is p and of failure is (1 − p). We are observing this sequence until a predefined number r of failures has occurred. Then the random number of successes we have seen, X, will have the negative binomial (or Pascal) distribution:

When applied to real-world problems, outcomes of success and failure may or may not be outcomes we ordinarily view as good and bad, respectively. Suppose we used the negative binomial distribution to model the number of days a certain machine works before it breaks down. In this case "success" would be the result on a day when the machine worked properly, whereas a breakdown would be a "failure". If we used the negative binomial distribution to model the number of goal attempts an athlete makes before scoring r goals, though, then each unsuccessful attempt would be a "success", and scoring a goal would be "failure". If we are tossing a coin, then the negative binomial distribution can give the number of heads ("success") we are likely to encounter before we encounter a certain number of tails ("failure"). In the probability mass function below, p is the probability of success, and (1 − p) is the probability of failure.
Probability mass function
The probability mass function of the negative binomial distribution is

where k is the number of successes, r is the number of failures, and p is the probability of success. Here the quantity in parentheses is the binomial coefficient, and is equal to

This quantity can alternatively be written in the following manner, explaining the name "negative binomial":
![{\displaystyle {\begin{aligned}&{\frac {(k+r-1)\dotsm (r)}{k!}}\\[6pt]={}&(-1)^{k}{\frac {(-r)(-r-1)(-r-2)\dotsm (-r-k+1)}{k!}}=(-1)^{k}{\binom {-r}{k}}.\end{aligned}}}](../I/m/6ffcb8bf581835d46e6607be6a55cc58882ee921.svg)
Note that by the last expression and the binomial series, for every 0 ≤ p < 1,

hence the terms of the probability mass function indeed add up to one.
To understand the above definition of the probability mass function, note that the probability for every specific sequence of k successes and r failures is (1 − p)rpk, because the outcomes of the k + r trials are supposed to happen independently. Since the rth failure always comes last, it remains to choose the k trials with successes out of the remaining k + r − 1 trials. The above binomial coefficient, due to its combinatorial interpretation, gives precisely the number of all these sequences of length k + r − 1.
Expectation
When counting the number k of successes before r failures, the expected number of successes is rp/(1 − p).
When counting the number k + r of trials before r failures, the expected total number of trials of a negative binomial distribution with parameters (r, p) is r/(1 − p). To see this intuitively, imagine the above experiment is performed many times. That is, a set of trials is performed until r failures are obtained, then another set of trials, and then another etc. Write down the number of trials performed in each experiment: a, b, c, … and set a + b + c + … = N. Now we would expect about N(1 − p) failures in total. Say the experiment was performed n times. Then there are nr failures in total. So we would expect nr = N(1 − p), so N/n = r/(1 − p). See that N/n is just the average number of trials per experiment. That is what we mean by "expectation". The average number of successes per experiment is N/n − r, which must have expected value equal to r/(1 − p) − r = rp/(1 − p). This agrees with the mean given in the box on the right-hand side of this page.
Variance
When counting the number k of successes given the number r of failures, the variance is rp/(1 − p)2.
Alternative formulations
Some sources may define the negative binomial distribution slightly differently from the primary one here. The most common variations are where the random variable X is counting different things. These variations can be seen in the table here:
| X is counting... | Probability mass function | Formula | Alternate formula
(using equivalent binomial) |
Alternate formula
(simplified using: ) |
Support | |
| 1 | k successes, given r failures | |||||
| 2 | n trials, given r failures | |||||
| 3 | r failures, given k successes | [2][3][4] | [5][6][7][8] | |||
| 4 | n trials, given k successes | [3][8][9][10][11] | ||||
| 5 | k successes, given n trials | This is the binomial distribution: | ||||






















Each of these definitions of the negative binomial distribution can be expressed in slightly different but equivalent ways. The first alternative formulation is simply an equivalent form of the binomial coefficient, that is: . The second alternate formulation somewhat simplifies the expression by recognizing that the total number of trials is simply the number of successes and failures, that is: . These second formulations may be more intuitive to understand, however they are perhaps less practical as they have more terms.

- This definition is where X is the number k of successes given a set of r failures, and is the primary way the negative binomial distribution is defined in this article. The second alternative formula clearly shows the relationship of the negative binomial distribution to the binomial distribution. The only difference is that in the binomial coefficient of the negative binomial distribution, there are n − 1 trials to choose from (instead of n) when evaluating the number of ways that k successes can occur. This is because when you are evaluating the number of ways you can obtain k successes before you reach r failures, the last trial must be a failure. As such, the other events have one fewer positions available when counting possible orderings.
- The second definition is where X is the total number of n trials needed to get r failures. Since the total number of trials is equal to the number of successes plus the number of failures, the formulation is the same. The only difference in the distribution is the range is shifted by a factor of r. As such, the mean, the median, and the mode are also shifted by a factor of r.
- The definition where X is the number of r failures that occur for a given number of k successes. This definition is very similar to the primary definition used in this article, only that k successes and r failures are switched when considering what is being counted and what is given. Note however, that p still refers to the probability of "success".
- The definition where X is the number of n trials that occur for a given number of k successes. This definition is very similar to definition #2, only that k successes is given instead of r failures. Note however, that p still refers to the probability of "success".
- The definition of the negative binomial distribution can be extended to the case where the parameter r can take on a positive real value. Although it is impossible to visualize a non-integer number of "failures", we can still formally define the distribution through its probability mass function. The problem of extending the definition to real-valued (positive) r boils down to extending the binomial coefficient to its real-valued counterpart, based on the gamma function:
- Now, after substituting this expression in the original definition, we say that X has a negative binomial (or Pólya) distribution if it has a probability mass function:
- Here r is a real, positive number.


In negative binomial regression,[12] the distribution is specified in terms of its mean, , which is then related to explanatory variables as in linear regression or other generalized linear models. From the expression for the mean m, one can derive and . Then, substituting these expressions in the one for the probability mass function when r is real-valued, yields this parametrization of the probability mass function in terms of m:




The variance can then be written as . Some authors prefer to set , and express the variance as . In this context, and depending on the author, either the parameter r or its reciprocal α is referred to as the "dispersion parameter", "shape parameter" or "clustering coefficient",[13] or the "heterogeneity"[12] or "aggregation" parameter.[7] The term "aggregation" is particularly used in ecology when describing counts of individual organisms. Decrease of the aggregation parameter r towards zero corresponds to increasing aggregation of the organisms; increase of r towards infinity corresponds to absence of aggregation, as can be described by Poisson regression.



- Sometimes the distribution is parameterized in terms of its mean μ and variance σ2:
![{\displaystyle {\begin{aligned}&p={\frac {\sigma ^{2}-\mu }{\sigma ^{2}}},\\[6pt]&r={\frac {\mu ^{2}}{\sigma ^{2}-\mu }},\\[3pt]&\Pr(X=k)={k+{\frac {\mu ^{2}}{\sigma ^{2}-\mu }}-1 \choose k}\left({\frac {\sigma ^{2}-\mu }{\sigma ^{2}}}\right)^{k}\left({\frac {\mu }{\sigma ^{2}}}\right)^{\mu ^{2}/(\sigma ^{2}-\mu )}.\end{aligned}}}](../I/m/87a369577b8ff2620ac63f37c705c9346d8500d0.svg)
Occurrence
Waiting time in a Bernoulli process
For the special case where r is an integer, the negative binomial distribution is known as the Pascal distribution. It is the probability distribution of a certain number of failures and successes in a series of independent and identically distributed Bernoulli trials. For k + r Bernoulli trials with success probability p, the negative binomial gives the probability of k successes and r failures, with a failure on the last trial. In other words, the negative binomial distribution is the probability distribution of the number of successes before the rth failure in a Bernoulli process, with probability p of successes on each trial. A Bernoulli process is a discrete time process, and so the number of trials, failures, and successes are integers.
Consider the following example. Suppose we repeatedly throw a die, and consider a 1 to be a "failure". The probability of success on each trial is 5/6. The number of successes before the third failure belongs to the infinite set { 0, 1, 2, 3, ... }. That number of successes is a negative-binomially distributed random variable.
When r = 1 we get the probability distribution of number of successes before the first failure (i.e. the probability of the first failure occurring on the (k + 1)st trial), which is a geometric distribution:

Overdispersed Poisson
The negative binomial distribution, especially in its alternative parameterization described above, can be used as an alternative to the Poisson distribution. It is especially useful for discrete data over an unbounded positive range whose sample variance exceeds the sample mean. In such cases, the observations are overdispersed with respect to a Poisson distribution, for which the mean is equal to the variance. Hence a Poisson distribution is not an appropriate model. Since the negative binomial distribution has one more parameter than the Poisson, the second parameter can be used to adjust the variance independently of the mean. See Cumulants of some discrete probability distributions.
An application of this is to annual counts of tropical cyclones in the North Atlantic or to monthly to 6-monthly counts of wintertime extratropical cyclones over Europe, for which the variance is greater than the mean.[14][15][16] In the case of modest overdispersion, this may produce substantially similar results to an overdispersed Poisson distribution.[17][18]
The negative binomial distribution is also commonly used to model data in the form of discrete sequence read counts from high-throughput RNA and DNA sequencing experiments.[19][20][21]
Related distributions
- The geometric distribution (on { 0, 1, 2, 3, ... }) is a special case of the negative binomial distribution, with

- The negative binomial distribution is a special case of the discrete phase-type distribution.
- The negative binomial distribution is a special case of discrete Compound Poisson distribution.
Poisson distribution
Consider a sequence of negative binomial random variables where the stopping parameter r goes to infinity, whereas the probability of success in each trial, p, goes to zero in such a way as to keep the mean of the distribution constant. Denoting this mean λ, the parameter p will be p = λ/(λ + r)

Under this parametrization the probability mass function will be

Now if we consider the limit as r → ∞, the second factor will converge to one, and the third to the exponent function:

which is the mass function of a Poisson-distributed random variable with expected value λ.
In other words, the alternatively parameterized negative binomial distribution converges to the Poisson distribution and r controls the deviation from the Poisson. This makes the negative binomial distribution suitable as a robust alternative to the Poisson, which approaches the Poisson for large r, but which has larger variance than the Poisson for small r.

Gamma–Poisson mixture
The negative binomial distribution also arises as a continuous mixture of Poisson distributions (i.e. a compound probability distribution) where the mixing distribution of the Poisson rate is a gamma distribution. That is, we can view the negative binomial as a Poisson(λ) distribution, where λ is itself a random variable, distributed as a gamma distribution with shape = r and scale θ = p/(1 − p) or correspondingly rate β = (1 − p)/p.
To display the intuition behind this statement, consider two independent Poisson processes, “Success” and “Failure”, with intensities p and 1 − p. Together, the Success and Failure processes are equivalent to a single Poisson process of intensity 1, where an occurrence of the process is a success if a corresponding independent coin toss comes up heads with probability p; otherwise, it is a failure. If r is a counting number, the coin tosses show that the count of successes before the rth failure follows a negative binomial distribution with parameters r and p. The count is also, however, the count of the Success Poisson process at the random time T of the rth occurrence in the Failure Poisson process. The Success count follows a Poisson distribution with mean pT, where T is the waiting time for r occurrences in a Poisson process of intensity 1 − p, i.e., T is gamma-distributed with shape parameter r and intensity 1 − p. Thus, the negative binomial distribution is equivalent to a Poisson distribution with mean pT, where the random variate T is gamma-distributed with shape parameter r and intensity 1 − p. The preceding paragraph follows, because λ = pT is gamma-distributed with shape parameter r and intensity (1 − p)/p.
The following formal derivation (which does not depend on r being a counting number) confirms the intuition.
![{\displaystyle {\begin{aligned}f(k;r,p)&=\int _{0}^{\infty }f_{\operatorname {Poisson} (\lambda )}(k)\cdot f_{\operatorname {Gamma} \left(r,\,{\frac {1-p}{p}}\right)}(\lambda )\;\mathrm {d} \lambda \\[8pt]&=\int _{0}^{\infty }{\frac {\lambda ^{k}}{k!}}e^{-\lambda }\cdot \lambda ^{r-1}{\frac {e^{-\lambda (1-p)/p}}{{\big (}{\frac {p}{1-p}}{\big )}^{r}\,\Gamma (r)}}\;\mathrm {d} \lambda \\[8pt]&={\frac {(1-p)^{r}p^{-r}}{k!\,\Gamma (r)}}\int _{0}^{\infty }\lambda ^{r+k-1}e^{-\lambda /p}\;\mathrm {d} \lambda \\[8pt]&={\frac {(1-p)^{r}p^{-r}}{k!\,\Gamma (r)}}\ p^{r+k}\,\Gamma (r+k)\\[8pt]&={\frac {\Gamma (r+k)}{k!\;\Gamma (r)}}\;p^{k}(1-p)^{r}.\end{aligned}}}](../I/m/9403eb51a79f1572be0606ca48af53fe897c210f.svg)
Because of this, the negative binomial distribution is also known as the gamma–Poisson (mixture) distribution.
Note: The negative binomial distribution was originally derived as a limiting case of the gamma-Poisson distribution.[22]
Sum of geometric distributions
If Yr is a random variable following the negative binomial distribution with parameters r and p, and support {0, 1, 2, ...}, then Yr is a sum of r independent variables following the geometric distribution (on {0, 1, 2, ...}) with parameter 1-p. As a result of the central limit theorem, Yr (properly scaled and shifted) is therefore approximately normal for sufficiently large r.
Furthermore, if Bs+r is a random variable following the binomial distribution with parameters s + r and 1 − p, then

In this sense, the negative binomial distribution is the "inverse" of the binomial distribution.
The sum of independent negative-binomially distributed random variables r1 and r2 with the same value for parameter p is negative-binomially distributed with the same p but with r-value r1 + r2.
The negative binomial distribution is infinitely divisible, i.e., if Y has a negative binomial distribution, then for any positive integer n, there exist independent identically distributed random variables Y1, ..., Yn whose sum has the same distribution that Y has.
Representation as compound Poisson distribution
The negative binomial distribution NB(r,p) can be represented as a compound Poisson distribution: Let {Yn, n ∈ ℕ0} denote a sequence of independent and identically distributed random variables, each one having the logarithmic distribution Log(p), with probability mass function

Let N be a random variable, independent of the sequence, and suppose that N has a Poisson distribution with mean λ = −r ln(1 − p). Then the random sum

is NB(r,p)-distributed. To prove this, we calculate the probability generating function GX of X, which is the composition of the probability generating functions GN and GY1. Using

and

we obtain
![{\displaystyle {\begin{aligned}G_{X}(z)&=G_{N}(G_{Y_{1}}(z))\\[4pt]&=\exp {\biggl (}\lambda {\biggl (}{\frac {\ln(1-pz)}{\ln(1-p)}}-1{\biggr )}{\biggr )}\\[4pt]&=\exp {\bigl (}-r(\ln(1-pz)-\ln(1-p)){\bigr )}\\[4pt]&={\biggl (}{\frac {1-p}{1-pz}}{\biggr )}^{r},\qquad |z|<{\frac {1}{p}},\end{aligned}}}](../I/m/58ac77a8c8e8d8e302a1f7061d89c1933b09c683.svg)
which is the probability generating function of the NB(r,p) distribution.
The following table describes four distributions related to the number of successes in a sequence of draws:
| With replacements | No replacements | |
|---|---|---|
| Given number of draws | binomial distribution | hypergeometric distribution |
| Given number of failures | negative binomial distribution | negative hypergeometric distribution |
Properties
Cumulative distribution function
The cumulative distribution function can be expressed in terms of the regularized incomplete beta function:

Sampling and point estimation of p
Suppose p is unknown and an experiment is conducted where it is decided ahead of time that sampling will continue until r successes are found. A sufficient statistic for the experiment is k, the number of failures.
In estimating p, the minimum variance unbiased estimator is

The maximum likelihood estimate of p is

but this is a biased estimate. Its inverse (r + k)/r, is an unbiased estimate of 1/p, however.[23]
Relation to the binomial theorem
Suppose Y is a random variable with a binomial distribution with parameters n and p. Assume p + q = 1, with p, q ≥ 0. Then the binomial theorem implies that

Using Newton's binomial theorem, this can equally be written as:

in which the upper bound of summation is infinite. In this case, the binomial coefficient

is defined when n is a real number, instead of just a positive integer. But in our case of the binomial distribution it is zero when k > n. We can then say, for example

Now suppose r > 0 and we use a negative exponent:

Then all of the terms are positive, and the term

is just the probability that the number of failures before the rth success is equal to k, provided r is an integer. (If r is a negative non-integer, so that the exponent is a positive non-integer, then some of the terms in the sum above are negative, so we do not have a probability distribution on the set of all nonnegative integers.)
Now we also allow non-integer values of r. Then we have a proper negative binomial distribution, which is a generalization of the Pascal distribution, which coincides with the Pascal distribution when r happens to be a positive integer.
Recall from above that
- The sum of independent negative-binomially distributed random variables r1 and r2 with the same value for parameter p is negative-binomially distributed with the same p but with r-value r1 + r2.
This property persists when the definition is thus generalized, and affords a quick way to see that the negative binomial distribution is infinitely divisible.
Recurrence relation
The following recurrence relation holds:
![{\displaystyle {\begin{cases}(k+1)\Pr(k+1)-p\Pr(k)(k+r)=0,\\[5pt]\Pr(0)=(1-p)^{r}\end{cases}}}](../I/m/91c7f0560a6d03526a265792e49955f709351cd7.svg)
Parameter estimation
Maximum likelihood estimation
The maximum likelihood estimator only exists for samples for which the sample variance is larger than the sample mean.[24] The likelihood function for N iid observations (k1, ..., kN) is

from which we calculate the log-likelihood function

To find the maximum we take the partial derivatives with respect to r and p and set them equal to zero:
- and
![{\displaystyle {\frac {\partial \ell (r,p)}{\partial p}}=\left[\sum _{i=1}^{N}k_{i}{\frac {1}{p}}\right]-Nr{\frac {1}{1-p}}=0}](../I/m/5e8e9adbfe4007e774dd1bab086cb14d4478a438.svg)
![{\displaystyle {\frac {\partial \ell (r,p)}{\partial r}}=\left[\sum _{i=1}^{N}\psi (k_{i}+r)\right]-N\psi (r)+N\ln {(1-p)}=0}](../I/m/8adbed27a234975b23524e25bcf7829c36d9a243.svg)
where
- is the digamma function.

Solving the first equation for p gives:

Substituting this in the second equation gives:
![{\displaystyle {\frac {\partial \ell (r,p)}{\partial r}}=\left[\sum _{i=1}^{N}\psi (k_{i}+r)\right]-N\psi (r)+N\ln {\left({\frac {r}{r+\sum _{i=1}^{N}k_{i}/N}}\right)}=0}](../I/m/6a55fc8b9006d1eb8816a990b0e7abc6c932b635.svg)
This equation cannot be solved for r in closed form. If a numerical solution is desired, an iterative technique such as Newton's method can be used. Alternatively, the expectation–maximization algorithm can be used.[24]
Examples
Selling candy
Pat Collis is required to sell candy bars to raise money for the 6th grade field trip. There are thirty houses in the neighborhood, and Pat is not supposed to return home until five candy bars have been sold. So the child goes door to door, selling candy bars. At each house, there is a 0.6 probability of selling one candy bar and a 0.4 probability of selling nothing.
What's the probability of selling the last candy bar at the nth house?
Recall that the NegBin(r, p) distribution describes the probability of k failures and r successes in k + r Bernoulli(p) trials with success on the last trial. Selling five candy bars means getting five successes. The number of trials (i.e. houses) this takes is therefore k + 5 = n. The random variable we are interested in is the number of houses, so we substitute k = n − 5 into a NegBin(5, 0.4) mass function and obtain the following mass function of the distribution of houses (for n ≥ 5):

What's the probability that Pat finishes on the tenth house?

What's the probability that Pat finishes on or before reaching the eighth house?
To finish on or before the eighth house, Pat must finish at the fifth, sixth, seventh, or eighth house. Sum those probabilities:





What's the probability that Pat exhausts all 30 houses in the neighborhood?
This can be expressed as the probability that Pat does not finish on the fifth through the thirtieth house:

Length of hospital stay
Hospital length of stay is an example of real world data that can be modelled well with a negative binomial distribution.[25]
See also
References
- ↑ DeGroot, Morris H. (1986). Probability and Statistics (Second ed.). Addison-Wesley. pp. 258–259. ISBN 0-201-11366-X. LCCN 84006269. OCLC 10605205.
- ↑ "Mathworks: Negative Binomial Distribution".
- 1 2 Cook, John D. "Notes on the Negative Binomial Distribution" (PDF).
- ↑ Saha, Abhishek. "Introduction to Probability / Fundamentals of Probability: Lecture 14" (PDF).
- ↑ W., Weisstein, Eric. "Negative Binomial Distribution". mathworld.wolfram.com.
- ↑ SAS Institute, "Negative Binomial Distribution", SAS(R) 9.4 Functions and CALL Routines: Reference, Fourth Edition, SAS Institute, Cary, NC, 2016.
- 1 2 Crawley, Michael J. (2012). The R Book. Wiley. ISBN 978-1-118-44896-0.
- 1 2 "Set theory: Section 3.2.5 – Negative Binomial Distribution" (PDF).
- ↑ "Random: The negative binomial distribution".
- ↑ "Stat Trek: Negative Binomial Distribution".
- ↑ Wroughton, Jacqueline. "Distinguishing Between Binomial, Hypergeometric and Negative Binomial Distributions" (PDF).
- 1 2 Hilbe, Joseph M. (2011). Negative Binomial Regression (Second ed.). Cambridge, UK: Cambridge University Press. ISBN 978-0-521-19815-8.
- ↑ Lloyd-Smith, J. O. (2007). "Maximum Likelihood Estimation of the Negative Binomial Dispersion Parameter for Highly Overdispersed Data, with Applications to Infectious Diseases". PLoS ONE. 2 (2): e180. doi:10.1371/journal.pone.0000180. PMC 1791715. PMID 17299582.

- ↑ Villarini, G.; Vecchi, G.A.; Smith, J.A. (2010). "Modeling of the dependence of tropical storm counts in the North Atlantic Basin on climate indices". Monthly Weather Review. 138 (7): 2681–2705. doi:10.1175/2010MWR3315.1.
- ↑ Mailier, P.J.; Stephenson, D.B.; Ferro, C.A.T.; Hodges, K.I. (2006). "Serial Clustering of Extratropical Cyclones". Monthly Weather Review. 134 (8): 2224–2240. doi:10.1175/MWR3160.1.
- ↑ Vitolo, R.; Stephenson, D.B.; Cook, Ian M.; Mitchell-Wallace, K. (2009). "Serial clustering of intense European storms". Meteorologische Zeitschrift. 18 (4): 411–424. doi:10.1127/0941-2948/2009/0393.
- ↑ McCullagh, Peter; Nelder, John (1989). Generalized Linear Models (Second ed.). Boca Raton: Chapman and Hall/CRC. ISBN 0-412-31760-5.
- ↑ Cameron, Adrian C.; Trivedi, Pravin K. (1998). Regression analysis of count data. Cambridge University Press. ISBN 0-521-63567-5.
- ↑ Robinson, M.D.; Smyth, G.K. (2007). "Moderated statistical tests for assessing differences in tag abundance". Bioinformatics. 23 (21): 2881–2887. doi:10.1093/bioinformatics/btm453. PMID 17881408.
- ↑ Love, Michael; Anders, Simon (October 14, 2014). "Differential analysis of count data – the DESeq2 package" (PDF). Retrieved October 14, 2014.
- ↑ Chen, Yunshun; Davis, McCarthy (September 25, 2014). "edgeR: differential expression analysis of digital gene expression data" (PDF). Retrieved October 14, 2014.
- ↑ Greenwood, M.; Yule, G. U. (1920). "An inquiry into the nature of frequency distributions representative of multiple happenings with particular reference of multiple attacks of disease or of repeated accidents". J R Statist Soc. 83 (2): 255–279. doi:10.2307/2341080.
- ↑ Haldane, J. B. S. (1945). "On a Method of Estimating Frequencies". Biometrika. 33 (3): 222–225. doi:10.1093/biomet/33.3.222. JSTOR 2332299.
- 1 2 Aramidis, K. (1999). "An EM algorithm for estimating negative binomial parameters". Australian & New Zealand Journal of Statistics. 41 (2): 213–221. doi:10.1111/1467-842X.00075.
- ↑ Carter, E.M., Potts, H.W.W. (4 April 2014). "Predicting length of stay from an electronic patient record system: a primary total knee replacement example". BMC Medical Informatics and Decision Making. 14: 26. doi:10.1186/1472-6947-14-26. Retrieved 23 April 2014.