| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Na het lezen van deze module kent de lezer de belangrijkste GIS-begrippen en -principes tot op een niveau waarmee zowel een gemiddelde GIS-softwarehandleiding is te begrijpen, als waarmee de rest van dit handboek begrepen kan worden. De lezer kent de kracht van geo-informatie en hij kan de beperkingen van geo-informatie als input noemen, voor zover die bij het maken van analyses én kaarten van belang zijn. Het deel over digitaliseren is facultatief opgenomen.
Wat is GIS?GIS is de afkorting van Geografisch Informatie Systeem. In een GIS kunnen diverse (informatie)lagen over elkaar worden gelegd. Met GIS-technieken kunnen ruimtelijke gegevens worden gegenereerd, gevisualiseerd, bewerkt en geanalyseerd. In het spraakgebruik, ook door GIS-specialisten zelf, wordt met GIS vaak nog in een bredere definitie bedoeld. De visualisatie van een GIS gebeurt meestal in kaartvorm. Zo ontstaan ruimtelijke relaties tussen de verschillende informatielagen, relaties die zonder locatiecomponent niet gemaakt konden worden en die zonder gebruik van een GIS dus verborgen zouden blijven. Elke informatielaag bevat een aantal bij elkaar horende ruimtelijke objecten, zoals wegen, percelen en straatverlichting. Bij de definitie van GIS alléén aan een kaartengenerator denken, is echter veel te beperkt. Met een GIS kunnen namelijk ook ruimtelijke analyses worden uitgevoerd met die informatielagen. Sterker, sommige cartografen vinden nog steeds dat een GIS helemaal geen goede kaarten kan maken. GIS is in de jaren tachtig ook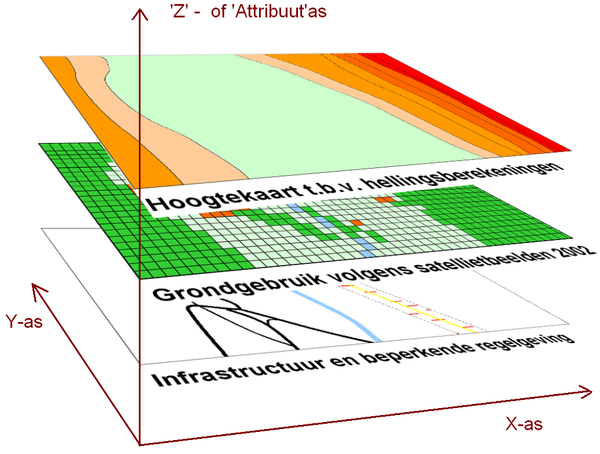 Een voorbeeld van een GIS-model, hier afgebeeld als een serie op elkaar gestapelde lagen informatie. Elke locatie (met een X- en Y-coördinaat) kan zo met meerdere kenmerken (Z-waarden) beschreven worden. In plaats van dat GIS als 'techniek' wordt gedefinieerd, wordt GIS ook vaak gebruikt voor een afdeling van een bedrijf, of een proces, inclusief 'data-, hard-, soft-, org- en humanware'. GIS wordt ook wel eens als synoniem gebruikt voor de complete geo-informatie voorziening. Daar valt dan ook onder de inwinning (het beheer) van geo-informatie en de ontsluiting met behulp van zogenaamde viewers aan werknemers of klanten. Soms worden vreemd genoeg ook landmeetkundige activiteiten, de landmeters zelf en vastgoedafdelingen van gemeentes tot GIS en de afdeling GIS gerekend. GIS-software maakt per definitie gebruik van een geo-informatie, en als het goed is, is die geo-informatie samenhangend ingebed in een GIS-model / de processen die een GIS moet ondersteunen voor een onderzoeksdoel of organisatie ('orgware'). Volgens T. Wade en S. Sommer is een GIS het geheel van software en data om informatie te tonen en / of te beheren op basis van hun geografische locaties, ruimtelijke analyses te kunnen uitvoeren en ruimtelijke processen te kunnen modelleren[1]. Volgens J. Maantay en J. Ziegler[2] zou in elke willekeurige definitie van GIS nooit de GIS-gebruiker mogen ontbreken, omdat deze essentiële expertkennis toevoegt, door het bedienen ervan, door de selectie van geo-informatie, de keuze van de GIS-functionaliteit en de representatie van het resultaat. 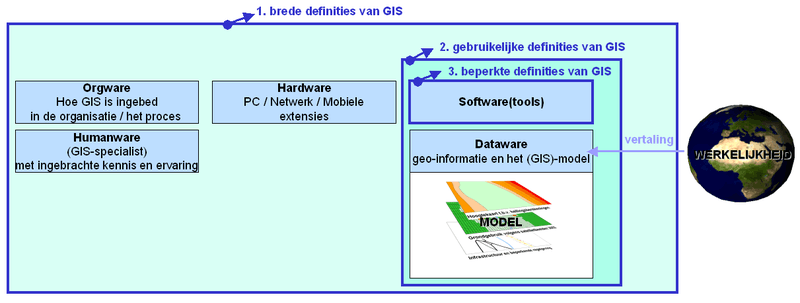 De reikwijdte van verschillende GIS-definities, en de componenten die meestal genoemd worden (zie tekst). Uit het voorgaande blijkt dat er geen eenduidigheid is over de definitie van GIS. Afhankelijk van de betrokkenheid, de kennis of het doel zijn de vele definities wel in drie soorten in te delen (zie figuur):
Die laatste definitie is letterlijk (te) beperkt te noemen, omdat de software die de fabrikant levert niets kan zonder data en een logisch model (de gebruikelijkere definities) en iemand die het GIS kan bedienen met de juiste GIS-tools (de bredere definities). Merk op dat de werkelijkheid niet tot een GIS behoort, zoals dat met geen enkel informatiesysteem het geval zal kunnen zijn. In de module Communicatie zal hier verder op worden ingegaan, omdat daardoor kennis over het datamodel onontbeerlijk is. Conclusies over de werkelijkheid kunnen alléén getrokken worden indien men weet welk datamodel (met alle beperkingen van dien) gebruikt is om die werkelijkheid in een kaart / GIS te zetten. Wat kan met een GIS? Hoe data-lagen in een GIS zichtbaar zijn en 'gestapeld' worden weergegeven; twee voorbeelden uit de gemeente. De belangrijkste soorten toepassingsmogelijkheden van GIS-software zijn:
1 tot en met 4 zijn toepassingsmogelijkheden waarbij het GIS ook als zogenaamd decision support system (beleidsondersteunend systeem) wordt gebruikt.
Met een aantal voorbeelden uit de gemeentelijke wereld wordt dit hieronder verder duidelijk gemaakt. Dit gebeurt zonder hierbij de indruk te willen wekken een volledige opsomming van alle mogelijkheden van een GIS te noemen. Wel zal de kracht en verscheidenheid van GIS in zijn volledige breedte duidelijk worden. Het voorbeeld komt uit de beheerstaken van de gemeente, die verantwoordelijk is voor het beheer van de openbare ruimte, zoals lantaarnpalen, de ondergrondse leidingen, en communicatie met de rechthebbenden van de percelen. 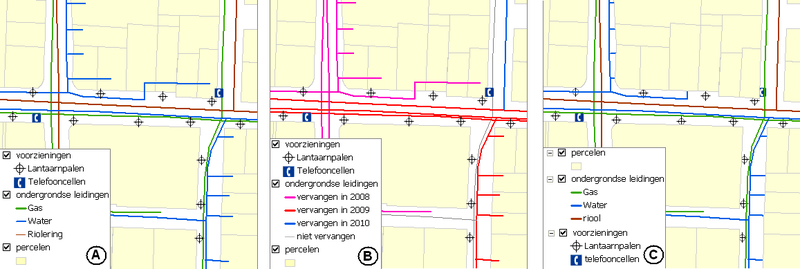 Hoe een kaart met één wijziging van de legenda kan wijzigen. De data-laag 'ondergrondse leidingen' is bij kaart A gevisualiseerd op soort, en bij kaart B gevisualiseerd op vervangingsjaar. Bij kaart C zijn de kaartlagen in de verkeerde volgorde gevisualiseerd. Vlakken dienen in het algemeen als eerste ('onderaan') getekend te worden. Ad Visualisatie:
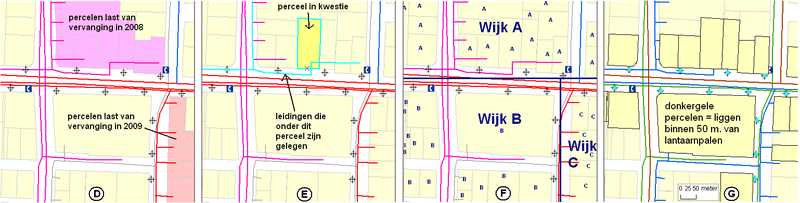 Vier toepassingsvoorbeelden van GIS. D = Welke percelen hebben last leidingen die in 2008 worden vervangen?; E = Welke leidingen liggen onder een bepaald perceel?; F = Bepaal de wijknummers voor alle percelen. G = Welke percelen liggen binnen 50 meter van een lantaarnpaal? Ad Analyses:
Ad Berekeningen:
Ad beheer:
Dit zijn voorbeelden van een aantal zeer gangbare functionaliteiten van GIS-software. De werkelijke mogelijkheden zijn véél groter. GIS als software bestaat al sinds de jaren tachtig. De ontwikkelingen zijn met name sinds 1990 zeer hard gegaan, en zijn betaalbaar geworden. Op het gebied van beheer, 3D-visualisatie, geostatistiek, geocoderen, cartografie, geoprocessing, netwerkanalyses zijn de functionaliteiten zeer breed en specialistisch te noemen. GIS-toepassingen zijn onder meer te vinden in / bij:
NB1: Uiteraard is bovenstaande tabel alleen indicatief, niet uitputtend. Meer voorbeelden van GIS-toepassingen zijn te vinden in de module met links: Overige Informatie. NB2: Dit handboek richt zich met name op het (goed) visualiseren van geo-informatie. Analyses en (beheer)toepassingen zijn vaak én zeer specifiek, én worden als mogelijkheden vaak al in de GIS (software) boeken uitgebreid uitgelegd. Daarnaast zijn die functionaliteiten per GIS-pakket zeer verschillend en worden ze verschillend genoemd. Wat is een GIS-model? Geo-informatie is als een pop of een modelauto; het is niet de werkelijkheid, maar geeft modelmatig weer hoe over de objecten nagedacht wordt, of nagedacht dient te worden. Zo'n model lijkt een beperking, maar kan ons ontzettend goed helpen om dát te zien waar het om gaat, en niet meer. 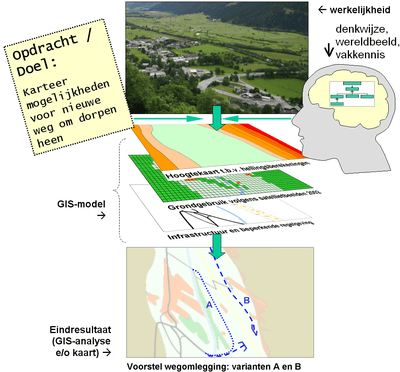 Kartering van een smal Oostenrijks dal met te veel wegverkeer door het dorp.  Steeds verder inzoomen (van links naar rechts) op twee soorten geo-informatie rasterdata (bovenste rij) en vectordata. Te zien is dat door de eigenschappen en de per definitie beperkte nauwkeurigheid, er beperkingen zitten aan hoe geo-informatie kan worden gebruikt. Voordat er een kaart gemaakt kan worden heb je – zoals eerder opgemerkt – een GIS-model nodig. Simpel gezegd is een GIS-model een verzameling (kaart)gegevens, verkregen uit metingen of berekeningen, meestal van een beperkt gebied; geo-informatie. GIS-modellen bestaan uit gestapelde, digitale lagen (geo-)informatie (datasets). De lagen liggen in één overeenkomstig assenstelsel. Elke laag bevat (de locaties van) objecten. Elke locatie of object is gelinkt aan een database met attribuut-informatie (in het figuur de Z-as). De 'Z'-as is in dit verband niet per definitie een hoogteas, maar geeft – voor welke laag dan ook – de attribuutwaarde weer. Bijvoorbeeld de hoogte, het grondgebruik, de onderhoudstatus of de aanwezige of toekomstige infrastructuur. Op basis van overeenkomstige Z- en Y-waarden kunnen de Z-waarden in een model verder verwerkt of gebruikt worden. Het kunnen combineren van de kaartlagen geldt dus niet alleen voor het kaarten maken, maar ook voor verdere analyses. De attribuutwaarden zelf kunnen namelijk geherclassificeerd worden. Of ze kunnen samen met attribuutwaarden van andere lagen gecombineerd worden, door zogenaamde ruimtelijke analyses. Hierboven werd al een voorbeeld genoemd waarbij een nieuwe supermarktlocatie moest worden bepaald met een GIS. Gezien de input – er werd over vijf soorten informatielagen gesproken – was er in die 'case' al een (sociaal-economisch) GIS-model bekend. GIS-modellen kennen blijkbaar niet alleen een ruimtelijke component (jouw input) maar ook een vakinhoudelijke kant. Kijk eens naar het figuur met de foto van een Oostenrijks dal. Hier is de plaats van een GIS-model te zien bij de totstandkoming van een GIS-opdracht. De GIS-opdracht was simpel; laat zien waar de mogelijkheden zijn om een weg aan te leggen om het dorp heen, gezien alle daar geldende beperkingen. Met de nodige vakkennis (het brein rechtsboven) van een planoloog of fysisch geograaf worden de benodigde informatielagen in stelling gebracht. Zoals maximaal mogelijke hellingshoeken, belemmerende regelgeving, bebouwing, enzovoort. Merk op dat al deze input (informatielagen) een ruimtelijke component hebben. Zelfs regelgeving is in een informatielaag weer te geven. Tezamen vormen deze informatielagen het belangrijkste deel van het GIS-model. Het GIS-model wordt gebruikt als een modelmatige representatie van de werkelijkheid, op basis van hoe tegen de werkelijkheid aan wordt gekeken. Dat is dus een model met een bepaald (en beperkt) doel. De output / de kaarten die ermee gemaakt kunnen worden zijn dus ook per definitie beperkt. Merk op dat het GIS-model in de figuur niet alleen uit kaarten bestaat, maar ook uit (de mogelijkheid tot) berekeningen. In de output is namelijk ook het begrip steilheid nodig; deze wordt in het model berekend. De steilheid is door een GIS vanuit de informatielaag 'hoogte' op elk punt berekend. Dit was nodig om te kijken waar de steilheid niet te groot zou zijn. Soms lees je dat het ontwerpen van een GIS-model (of de fysieke database ervan, of het verzamelen van een set data nodig voor een kaart) hetzelfde is als het zoeken naar de beste representatie van de werkelijkheid buiten. Eigenlijk is dat zéér fout. Omwille van kostenefficiency én om moeite te besparen ga je namelijk vooral niet 'alles wat je buiten ziet' in kaart brengen. Je zult nét zo nauwkeurig data willen inwinnen, of die data aanschaffen, die nét nog voldoende is voor het beantwoorden van je vraag. Wat wél bedoeld wordt, is dat de werkelijkheid buiten – voor zover die nodig is voor het beantwoorden van vragen – zo goed mogelijk beschreven moet worden. Wat is geo-informatie?Een kaart is volgens J. Maantay en J. Ziegler een schaalmodel van de werkelijkheid, waarbij de informatie over de fysieke wereld die nodig is om die modellen op te bouwen gevormd wordt door geo-informatie (Engels: 'spatial data')[6]. In dit handboek wordt geo-informatie gezien als input voor een GIS, noodzakelijk om een thema te visualiseren of een kaart te maken. Kennis over geo-informatie is nodig om voor de juiste input te kunnen zorgen, zodat de kwaliteit van het eindproduct – de analyse of de kaart – vooraf gegarandeerd kan worden richting de opdrachtgever en de doelgroep. Hieronder volgen daarom:
Objectsoorten en opslag van geo-informatieGeo-informatie beschrijft de werkelijkheid door een beschrijving er van in drie objectsoorten:
Deze objecten kunnen op twee manieren in bestanden of databases worden opgeslagen:
Bij de opslag worden de objectgegevens vaak in twee delen beschreven:
De reden dat geografische en administratieve gegevens in twee aparte delen worden beschreven, heeft te maken met het feit dat het lezen, opslaan en vooral rekenen met geografische gegevens veel efficiënter en sneller kan indien die gegevens in aparte, binaire formaten worden opgeslagen. Dit apart opslaan gebeurt zowel in bestandsgeoriënteerde opslag als bij ruimtelijke databases, ook al lijkt het soms om één bestand of één tabel in de database te gaan. Naast de geografische en administratieve objectgegevens kunnen bij de geo-informatie ook andere, extra gegevens worden opgeslagen, zoals:
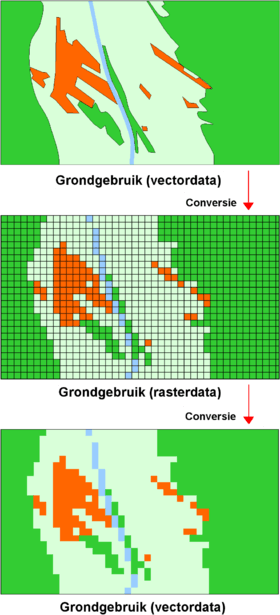 Voorbeeld van (onomkeerbare) conversies van vector- naar raster-data en weer terug.
Rechtsboven een voorbeeld van hoe de kwaliteit van data achteruit kan gaan bij conversies. Hier betreft het eerst een 'vector-naar-raster' conversie, daarna een 'raster-naar-vector' conversie.
Hierboven hadden we het steeds over tweedimensionale geo-informatie, waarin punten, lijnen en vlakken zowel als vectordata, als als rasterdata kunnen worden opgeslagen. Wanneer driedimensionale gegevens als raster worden opgeslagen, kan dat niet met tweedimensionale (vierkante) vlakjes, maar moet dat met (rechthoekige) kubusjes. Sterk ingezoomd op zo'n model zal je die kubusjes ook kunnen zien. Deze kubusjes worden voxels genoemd. Voxels is een samentrekking van de twee Engelse woorden 'volume' en 'pixels'; oftewel een 'pixel met een volume'. Je zal deze term en dergelijke bestanden alleen tegen komen als je veel met hoogtemodellen (zie ook de figuur) gaat werken. Niet alle GIS-softwarepakketten kunnen met voxels werken. Toepassing van Rasterdata: Rasterdata:
CAD-data en GIS-data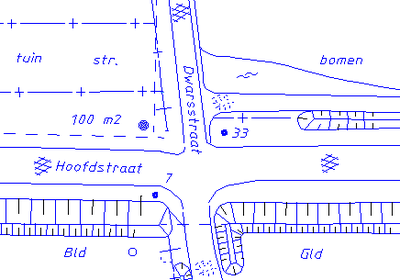 Een typisch voorbeeld van CAD-data. Teksten zijn geometrisch opgeslagen, eigenschappen van bepaalde gebieden, zoals asfaltering of gebruik, zijn met puntsymbolen en afgekorte teksten aangeduid. 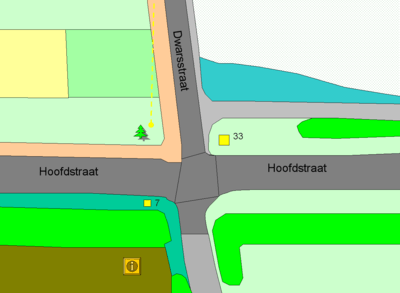 Een typisch voorbeeld van GIS-data. De teksten zijn in de attributen opgeslagen. Soms worden die gebruikt om labels te genereren, meestal worden ze gebruikt om met een kleur een eigenschap (bouwland, grasland of geasfalteerd) aan te geven. Merk op dat het kruispunt als een apart object is getekend. Vaak wordt door GIS-specialisten gesproken over de term 'GIS-data', als verbijzondering van geo-informatie. Ze doen dat bewust, omdat niet alle soorten geo-informatie met een GIS eenvoudig tot een kaart zijn om te vormen. Geo-informatie is namelijk een verzamelterm voor alle informatie met een geografische component. Dus ook CAD-(Computer Aided Design) gegevens vallen onder geo-informatie. Het bijzondere van GIS-data is dat niet alleen de punten, lijnen en vlakken worden opgeslagen, ook de bij die objecten horende attributen. Vandaar dat GIS-data, boven CAD-data, ook wel 'intelligente' data worden genoemd. Daardoor zijn er binnen een GIS plotseling veel meer mogelijkheden, zowel op het gebied van visualisaties (zie volgende paragraaf) als op het gebied van ruimtelijke en administratieve analyses. Overigens, met 'administratief' wordt bedoeld niet de ruimtelijke gegevens van objecten in GIS-data, maar de tegenhanger ervan, de tekstuele en numerieke tabelgegevens. Enkele eigenschappen van CAD-data en GIS-data:
GIS-specialisten hebben dus het liefst GIS-data, ook wel intelligente of 'GIS-waardige' data genoemd. Overigens, in de meeste GIS-pakketten is ook CAD-data in te lezen. GIS-pakketten hebben er echter wel vaak moeite mee. De in CAD-data opgeslagen visuele eigenschappen als lijndikte, lijnstijl en kleur en gebruikte puntsymbolen gaan dan verloren. Is CAD-data objectgeoriënteerd, dan kan deze met wat moeite omgezet worden in GIS-data. Ontwikkelaars van CAD-software slagen er steeds meer in om ook met hun CAD objectgeoriënteerde bestanden te kunnen leveren, waar wél attribuutdata in opgeslagen zijn en die wél goed is in te lezen in een GIS. CAD en GIS groeien daarmee steeds meer naar elkaar toe. Soms lezen ze dezelfde data in. In de praktijk zal echter voorlopig nog steeds gelden: werk je met een GIS, zoek dan in eerste instantie naar GIS-data. Objectgeoriënteerd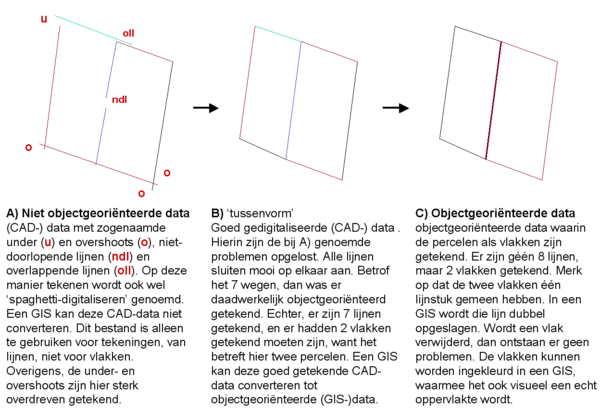 Wel of niet objectgeoriënteerd tekenen bepaalt de waarde ervan voor een GIS. In dit voorbeeld zijn twee aangrenzende kadastrale percelen op drie verschillende wijzen getekend. Links zijn lijnen getekend, rechts zijn objecten getekend (objectgeoriënteerd). Met name bij CAD-data worden lijnen van objecten niet altijd netjes exact op elkaar aangesloten, zogeheten undershoots. Dat is ook niet erg wanneer deze data 'slechts' voor visualisatie wordt gebruikt, zolang er maar niet te ver op wordt ingezoomd. Het is dan ook niet erg dat de tekenaars de lijnen te ver doortrekken daar waar ze op een andere lijn hadden moeten eindigen, zogeheten overshoots (of dangles). Met andere woorden CAD-bestanden worden lang niet altijd wat we noemen 'objectgeoriënteerd' opgebouwd. 'Spaghettidigitalisering' is de wat licht negatief bedoelde naam voor het 'niet objectgericht karteren of digitaliseren'. Bij verwerking in een GIS is dit objectgeoriënteerd zijn vrijwel altijd een noodzaak. Nog zo'n term is een pseudonode, een node (vertex) die niet nodig is, omdat de lijn daar niet buigt. Voor een GIS is dat qua analyse geen probleem. Komt het echter in één bestand heel vaak voor, dan kunnen deze psuedonodes, oftwel onnodige vertices, de performance wel negatief beïnvloeden. Pseudonodes ontstaan niet zozeer door overijverige of onzekere digitaliseer-specialisten. Vaker ontstaan die op het moment dat door een GIS-tool, in een bepaald conversieproces, korte lijstukjes, ooit met een CAD getekend, worden samengevoegd tot één lijn. In de figuur is dat het geval bij 'ndl' (linker deel figuur, paarsblauwe lijn). Worden die twee middelste lijnen (geautomatiseerd of handmatig) samengevoegd (middelste deel figuur), dan ontstaat er in het midden een vertex die zonder software niet zichtbaar is, omdat er geen buigpunt te zien is. Een GIS kan meestal deze onnodige tussenpuntenpunten weghalen met een tool zoals bijvoorbeeld 'remove pseudonodes'. Deze punten bepalen immers niet de vorm van zo'n lijn. Met objectgeoriënteerd (ook vaak objectgericht genoemd) wordt bedoeld dat de lijnen niet getekend zijn om allerlei grenzen aan te geven, maar om de objecten aan te geven. Begin- en eindpunten van lijnen zijn niet lukraak gekozen, maar stoppen en starten daar waar het object ook begint en eindigt. Ook voor vlakken geldt dat die niet omgeven worden door lukraak getekende lijnen, maar door één omhullende lijn. Twee rechthoekige aangrenzende percelen worden niet weergegeven door 7 of 8 lijnen, maar door 2 vlakken (zie figuur). Bovendien zijn de van een objectgeoriënteerde dataset vrijwel altijd ook meteen koppelbaar gemaakt aan beschrijvingen in andere (administratieve) databases. Tijdens het digitaliseren met CAD-software of achteraf met een GIS is middels topologische regels af te dwingen dat lijnen en vlakken objectgeoriënteerd worden getekend of opgeslagen. Er is bijvoorbeeld in te stellen dat lijnen op minimaal twee andere lijnen moeten aansluiten, anders had die lijn één lijn moeten zijn. Of dat vlakken (in het geval van grondgebruik of percelen) elkaar niet mogen overlappen. Zie verder de toelichting bij de figuur. 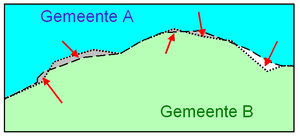 Slivers zijn niet sluitende of overlappende vlakken, daar waar dat niet het geval zou mogen zijn. Vaak zie je dit pas wanneer er sterk is ingezoomd op deze grensgebieden. Zoals je bij lijnen under- en overshoots hebt, zo heb je bij vlakken zogeheten slivers, ook wel sliver-polygonen genoemd. Een Nederlandse term bestaat hier niet voor. Slivers zijn polygonen (vlakken) die elkaar onterecht niet over raken – er zitten dan gaten tussen de vlakken – of elkaar onterecht overlappen. Zo dienen gemeentegrenzen (de omtrekken van de vlakken die gemeentes beschrijven) van naburige gemeente te sluiten. Er mogen nooit gebieden zijn waarvoor geldt dat die niet tot een bepaalde gemeente vallen. Ook mogen de gemeentes elkaar niet overlappen. Bij veel soorten geo-informatie mogen géén slivers vóórkomen. Denk aan bodemkaarten, hoogtezones, geluidsniveaus en allerlei bestuurlijke indelingen. Er kan namelijk op één plek altijd maar één (niet meer en niet minder) waarde van toepassing zijn; er is op een bepaalde plek maar één bodemsoort, één hoogtezone, een geluidsniveau en één provincie van toepassing. Er kan op één punt niet géén bodemsoort voorkomen, of twee bodemsoorten. Over slivers:
Het bijzondere van GIS-data: de attributenHieronder, om elk misverstand uit te sluiten, hoe objecten uit werkelijkheid en de attributen van die objecten worden opgeslagen in een GIS-bestand. 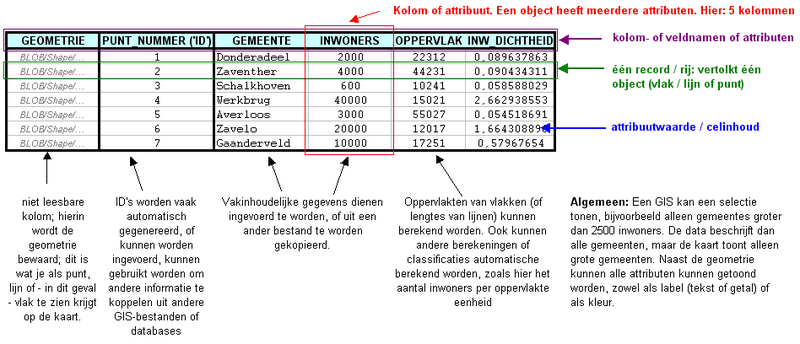 Hoe objecten en hun attributen in rijen en kolommen worden opgeslagen in een GIS. Dit geldt voor vrijwel alle dataformaten van alle leveranciers, voor zowel filegebaseerde bestanden als op databases. Het meeste zal de lezer logisch voorkomen. Maar wie nog onbekend is met GIS moet de opbouw kunnen begrijpen. Niet zozeer om een GIS-specialist te kunnen volgen, maar om het maximale uit een GIS te halen. In het figuur hieronder wordt duidelijk dat GIS-data uit een geografische en een administratieve component bestaat: 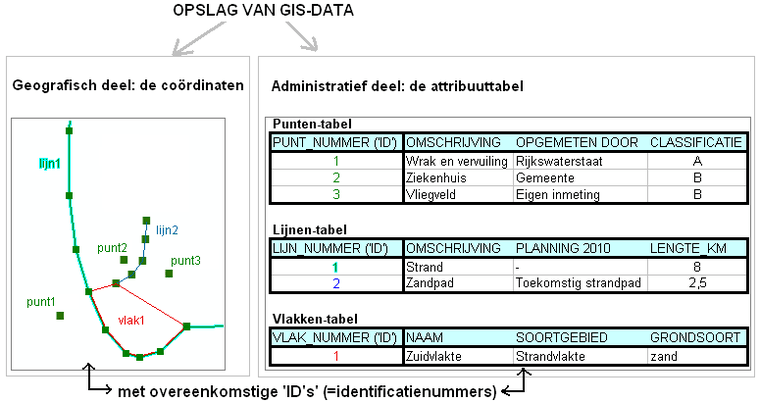 GIS-data zoals die wordt opgeslagen in een bestand of database bestaat uit twee delen, een geografisch en een administratief deel. Of het nu punten, lijnen of vlakken zijn, de objecten die in beide delen worden beschreven zijn via een 'ID' gekoppeld.  Zonder geo-visualisatie is GIS-data slechts ruwe data. Pas met een GIS komt de data tot leven en ontstaat een echte kaart. Dat gaat op basis van de attributen bij de GIS-data; voorwaarde is dat de data objectgeoriënteerd is. Te zien zijn drie voorbeelden met dezelfde GIS-data (linksboven) als uitgangspunt. Rechtsonder zijn die attributen niet als symbolen, maar als teksten geplaatst. Bij bedrijfstoepassingen of bij zeer grote hoeveelheden administratieve gegevens word veel attribuutgegevens vaak opgeslagen en beheerd buiten de GIS-data, in een externe database. Slechts dat éne ID is dan voldoende om de objecten op basis van attributen uit de database juist te kunnen visualiseren. Er moet dan wel een verbinding (of onlinekoppeling) tussen het GIS-pakket en die externe database zijn. Is dat niet het geval, dan zijn er problemen te verwachten op het gebied van uitwisseling van gegevens, combineerbaarheid, consistentie en actualiteit en is er waarschijnlijk sprake van een onnodig hoge beheerslast voor de organisatie. Wanneer je in een GIS-pakket GIS-data laadt, zal eerst voor alle objecten uit een GIS-bestand één willekeurige kleur worden getekend. Alle objecten (bijvoorbeeld: alle punten) hebben dan dezelfde kleuren. Op basis van de thematische / administratieve gegevens uit de tabel zijn de individuele objecten dan andere kleuren of symbolen toe te kennen. Dat is te zien in de figuur hier rechtsboven. Duidelijk is dat de attribuutwaarden van de verschillende objecten, samen met de inventiviteit van de GIS-specialist, bepalen hoe de objecten uit de GIS-data gevisualiseerd worden. De mogelijkheden zijn 'eindeloos'. Richtlijnen over hoe dat moet gebeuren staan in de delen B en C van dit handboek. Let op: buiten deze twee bovenstaande paragrafen wordt niet specifiek over GIS-data gesproken. Gekozen is om de term geo-informatie te gebruiken, een algemeen geaccepteerde, neutrale term. Vaak zal echter wel bedoeld worden: GIS-data, omdat dit voor een GIS-specialist de meest ideale geo-informatie is. Gebruik maken van attributen: over queries of 'zoekvragen'Attributen zijn de kracht van geo-informatie. Een GIS kan hier op meerdere manieren slim gebruik van maken. Zoals gezegd, in deel B (thematische kaarten) en deel C (o.a. bij het labellen) zal op de daadwerkelijke toepassing terug gekomen worden. Hieronder nog wat theoretische achtergrond, die nodig zal zijn om er überhaupt gebruik van te kunnen maken. Hieronder een voorbeeld hoe een goed doordacht (maar zeer simpel) GIS-model er voor zorgt dat er snel en plezierig gebruik kan worden gemaakt van de mogelijkheden die een GIS biedt. Het eerste figuur toont één tabel (gegevensbestand of geo-informatie) met grote steden van Nederland. Merk op dat er een kolom 'Status' in staat: 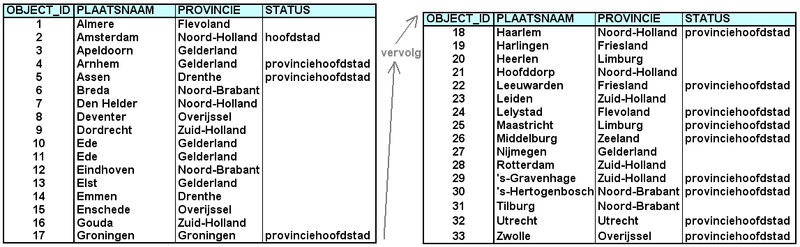 Tabelrepresentatie van een GIS-bestand van een aantal grote Nederlandse steden. Voor die steden die een provinciehoofdstad zijn, is dit in deze kolom 'Status' aangegeven. Met dit (gedeeltelijk getoonde) bestand zijn drie kaarten gemaakt. Door slim gebruik te maken van de attributen zijn met dit bestand verschillende soorten kaarten te maken: 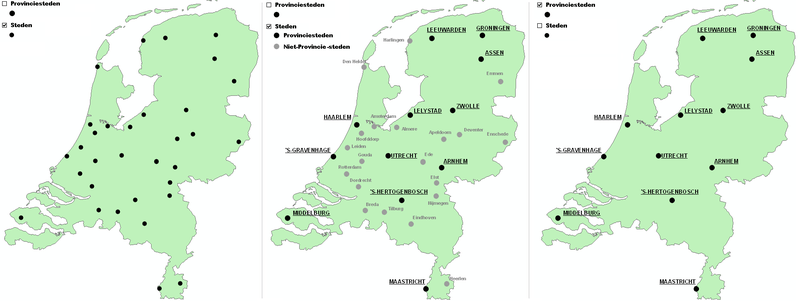 Drie kaarten van steden van Nederland op basis van dezelfde hierboven getoonde data (klik op het figuur voor meer detail). Over de kaart met steden en provinciehoofdsteden:
In tegenstelling wat een beginnende GIS-ser of – eerder – een buitenstaander misschien zou verwachten, hoeven voor de drie kaarten die gemaakt zijn niet verschillende bestanden (één met hoofdsteden, één met alle steden, en misschien wel één met overige steden) te worden gemaakt. Het mag duidelijk zijn dat de opbouw van zo'n steden bestand moet aangepast zijn op basis van wat nodig is voor analyse en kaarten maken. De exacte opbouw van zo'n GIS-bestand is een simpel voorbeeld van een GIS-model. Zonder over die opbouw vooraf goed (en eenmalig) na te denken, kan je later wel eens enorm veel moeite blijken te hebben met het maken van goede analyses en kaarten. In de tweede en derde kaart lijkt het zo in de eenvoudige legenda die linksboven is getoond, dat er sprake is van een tweetal bestanden ('lagen') die worden aan- of uitgevinkt. In werkelijkheid verwijzen ze beide naar dezelfde data: het eerder genoemde bestand met álle steden. Hoe kan het dan zijn dat de laag 'provinciesteden' niet alle objecten/steden laat zien in de kaart, maar slechts die steden die ook echt provinciehoofdstad zijn? Hier boven is twee maal gesproken over selecteren. Het (automatisch) selecteren gebeurt met zogenaamde queries (Engels, spreek uit: kwèries) of in het Nederlands 'zoekvragen'. Een query beperkt het objecten dat voorkomt in een geheel databestand op basis van een of meer voorwaarden. Queries maken gebruik van zogenaamde SQL-statements (Standard Query Language). GIS-pakketten zorgen vaak dat je met een wizard of op een andere manier deze selecties makkelijk kan maken. Vaak heb je het snel onder de knie. Een beperkte hoeveelheid kennis over SQL kan jou effectiviteit en de functionaliteit van je GIS vergroten. Hieronder wordt alleen een zeer summiere uitleg en het hierboven gebruikte voorbeeld gegeven. Een SQL-query (of: select-statement in dit geval) ziet er bijvoorbeeld als volgt uit: SELECT * FROM tabelnaam WHERE kolomnaam = ... voorwaarde ...
In het voorbeeld van hierboven is bij de 2e en 3e kaart dit select-statement gebruikt: SELECT * FROM hetnederlandsestedendataset WHERE [STATUS] = 'provinciehoofdstad'. Dankzij deze 'select-statements' hoeven we niet twee aparte bestanden te beheren; één met provinciehoofdsteden en een ander met de overige steden. Zonder select-statements en zonder bepaalde attribuutkolommen zou je nooit de toegevoegde waarde uit een GIS kunnen halen die er in zit. Door slim gebruik te maken van attribuutkolommen kunnen bestanden bij elkaar worden toegevoegd die voorheen misschien dubbel of separaat van elkaar zouden moeten worden bijgehouden. Dit zorgt voor minder werk en minder fouten aan de kant van de beheerder.
Eigenschappen van geo-informatieUit bovenstaande paragrafen zal het nu duidelijk zijn waarom geo-informatie géén kaartlaag genoemd mag worden. Geo-informatie staat in dienst van een GIS-model. Een GIS-model om analyses of kaarten te maken. Een (digitaal gemaakte) kaart bestaat uit een of meer geo-informatie bestanden / datasets, die geheel of gedeeltelijk in een kaart gebruikt of getoond kunnen worden. Zo kan een GIS-data bestand 'topografie' ook gebruikt worden om op een kaart alleen straten weer te geven. Een GIS beschrijft de werkelijkheid – voor zover de mens die al kan kennen – met allerlei beperkingen. Jij als GIS-specialist moet die altijd in het achterhoofd houden. Een GIS beschrijft niet de werkelijkheid. Dat komt omdat de geo-informatie die er in zit (vaak onterecht dus kaartlagen genoemd; datasets is beter) een gedwongen beperking van die werkelijkheid is. Hier volgen een aantal van die eigenschappen, die beperkingen kunnen zijn.
Wanneer jij bovenstaande beperkingen kent, weet je welke kaartlagen wel of niet mogen worden gecombineerd, welke conclusies mogen worden getrokken en – eventueel – welke waarschuwingen je de gebruiker mee moet geven met de kaart. In Deel B en C zullen aan deze beperkingen cartografische principes worden verbonden. Zoals – in het geval van de boom – met welke schaal en dikte je bepaalde symbolen moet weergeven. En in hoeveel verschillende klassen classificeer je de bevolkingsdichtheid van 12 provincies of honderden gemeenten?
Intermezzo: Over het gebruik van satellietbeelden en luchtfoto's 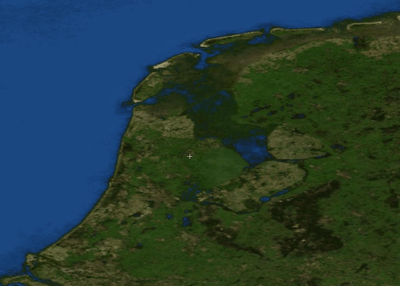 Noord-Nederland vanuit de satelliet (zie tekst). Of deze rasterbestanden nu satellietbeelden zijn of 'echte luchtfoto's', er kleven gevaren aan. Hier onder een opsomming van enkele eigenschappen van dergelijke beelden. Het zijn die eigenschappen die al snel kunnen leiden tot foute interpretaties bij de lezer:
Vermijd dergelijke slechte data, zorg voor goede projecties, zoom niet te ver in op kaarten en gebruik deze kaarten niet voor (nauwkeurige) afstandsmetingen of ruimtelijke analyses waar afstanden, vóórkomen en oppervlak een rol spelen. (Meer informatie over Remote Sensing (technieken, satellietbeelden), zie met name Lillesand, Kiefer, en Chipman; Remote Sensing and Image Interpretation, 2003, 5e editie). Toepassingscontext
De input die je gebruikt in een GIS is vaak niet (geheel) door jou of jouw bedrijf zelf ingewonnen. Of de data is afkomstig uit een afdeling die jij niet kent. Bekijk bijvoorbeeld eens bovenstaande tabel. 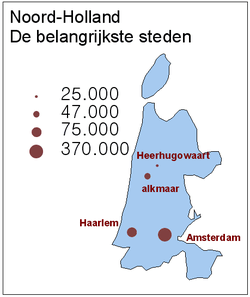 Mogelijke GIS-output o.b.v. de tabel. Stel je bent redacteur van een krant in Noord-Holland. Je moet een kaartje maken van de belangrijkste steden van Noord-Holland, als illustratie bij een artikel. De data krijg je via de mail van een behulpzame collega. Die heeft de data – heel handig – van de website van het busvervoerbedrijf 'Synnexxion' gehaald. Wanneer hier snel met een GIS een kaartje van wordt gemaakt, is het kaartje rechts wellicht het resultaat. Keurig met titel. Niet gevraagd, maar toch gedaan: je hebt de grootte van de cirkels op de een of andere manier laten afhangen van het aantal inwoners. En je hebt ook mooi een legenda toegevoegd. GIS is prachtig gebruikt. Of toch niet? Je mag hopen dat de redactie de klachten van de lezers voor is. Wat is er fout gegaan? Het aantal inwoners klopt niet. Dat stond wel in de kolomnaam van die tabel, maar bedoeld werd het aantal inwoners relevant voor Synnexxion. Namelijk, het aantal inwoners dat binnen een straal van 500 meter woont in de omgeving van de bushaltes. Notabene, steden als Zaanstad en Den-Helder staan er niet in. Waarom niet? Omdat deze tabel alle steden bevatte in Noord-Holland waar het fictieve bedrijf Synnexxion een aanbestedingscontract heeft voor het openbaar vervoer. Toch was de tabel voor Synnexxion vrijwel foutloos. Het aantal inwoners, zoals door Synnexxion gedefinieerd, klopte wel degelijk. Waarom mag zo'n tabel toch niet gebruikt worden? Er is sprake van een andere toepassingscontext. Voor het bedrijfsmodel van Synnexxion is ook de geringe precisie van de aantallen en het tweetal spelfouten in de namen geen enkel probleem. In 'jouw' kaart staan die fouten wél te veel. De kaart binnen de muren van Synnexxion is goed, er buiten is die kaart fout. Blijkbaar hebben data en kaarten een toepassingscontext. Overigens, dat er meer mis is met de kaart van Noord-Holland (symbolen, uitlijning va de elementen, ontbreken van essentiële onderdelen), wordt in Deel B en C duidelijk. Er zijn ook twee opdrachten over.
Digitalisering (facultatief)Voor het maken van kaarten en analyses is dus geo-informatie nodig. Meestal hoeft een GIS-specialist als kaartenmaker niet zozeer bij het totale totstandkomingsproces van geo-informatie stil te staan. De gegevens zijn immers vaak al aanwezig. Toch is het voor sommige GIS-specialisten – zeker als er geadviseerd dient te worden bij inkoop en bij digitaliseringstrajecten – nodig om meer van digitalisering af te weten. In het hoofdstuk hiervoor (Eigenschappen van geo-informatie) is al besproken dat niet elke soort geo-informatie inhoudelijk gezien zomaar gebruikt kan worden. Bijvoorbeeld omdat de actualiteit, nauwkeurigheid of toepassingscontext niet in orde is. Voor een GIS-specialist is er echter nog een beperking of geo-informatie wel gebruikt kan worden. Dat is de manier hoe het bestand modelmatig is opgebouwd en hoe het is opgeslagen. Kort gezegd, de manier van digitaliseren, of de 'mate van' digitalisering. Niet elk digitaal bestand is namelijk geschikt voor een elke toepassing in een GIS. Neem bijvoorbeeld een digitale, beschikbare, gedetailleerde topografische (wegen)kaart van Nederland, in een rasterformaat opgeslagen. Hier kan je lastig in meten en mee ontwerpen, omdat er geen vertices in zitten. Hierdoor ontbreken de juiste, nauwkeurige (hoek)punten van objecten. Je kan de objecten bovendien niet / nauwelijks geautomatiseerd laten analyseren. Selecties in dit bestand maken ("toon alleen grote steden of A- en B-wegen") kan ook niet. Laat staan dat de dataset voor bijvoorbeeld GIS-analyses, lineair refereren, routeberekeningen gebruikt kan worden. We moeten als GIS-specialist dus weten wat de mate van digitalisering is; de functionaliteit hangt namelijk af van de mate van digitalisering. Het zijn bijna dogma's – beweringen die goed klinken en door niemand betwist lijken te worden – dat digitaliseren goed is en dat digitalisering vroeg of laat zijn geld wel opbrengt. We 'moeten binnen een organisatie nu eenmaal verder', want 'stilstaan is achteruitgang'. Digitaliseren biedt inderdaad veel meer mogelijkheden dan analoge data. Maar hoever moet je gaan? Want de ene digitaliseringswijze is de andere niet! Wanneer het bedrijf een analoge gegevenscollectie of objecten buiten denkt te moeten digitaliseren, is bij te veel beleidsmakers, beslissers, managers en soms zelfs ICT'ers het credo "digitaliseren is goed en logisch" – al of niet met de benodigde business-case – helaas al voldoende om hen een 'GO' te ontfutselen voor dit digitaliseringstraject. Welke functionaliteit met die digitaliseringsslag bereikt moet worden, is voor de GIS-specialist / onderzoeker vaak nog wel duidelijk, echter, dat is het meestal niet bij die beslissers. Zowel bij beslissers als zelfs bij specialisten worden termen als digitaliseren, vectoriseren, verrasteren onbewust door elkaar gehaald, waardoor bij beide groepen spraakverwarring aanwezig kan zijn en – erger – verkeerde beslissingen in een digitaliseringsproject of in het digitaliseringsbeleid worden genomen. Dit hoofdstuk brengt daarom zo simpel mogelijk de verschillende termen in beeld. Een simpel plaatje met een toelichting kan gebruikt worden om spraakverwarring te voorkomen. Digitalisering wordt veelal omschreven als het omzetten van data van een analoog naar een digitaal medium[7]. Echter, in de literatuur over geo-informatie, wordt óók tot digitalisering, gerekend wanneer opgemeten gegevens van objecten (zoals ligging en eigenschappen) uit de (meestal: fysieke) werkelijkheid direct digitaal worden opgeslagen – dus zonder tussenkomst van analoge vastlegging op bijvoorbeeld papier. Digitalisering is een digitale vorm van vastleggen (zie figuur hierna). Waar vroeger zaken vooral analoog werden vastgelegd (voor zowel geo-informatie als 'gewone' informatie in tekstuele documenten), gebeurt dat tegenwoordig vrijwel altijd digitaal. Administratieve documenten werden in de jaren zeventig en tachtig van de vorige eeuw nog wel alleen analoog vastgelegd. Echter, tegenwoordig is dat nergens meer het geval. Alle administratieve data die moet worden vastgelegd, wordt digitaal opgeslagen. Bij geo-informatie is het, begin 21e eeuw, soms toch nog steeds zo dat er (oude) gegevens alleen analoog voor handen is. Dat zat 'm vaak in de kosten. Inmiddels is het wel een zeldzaamheid geworden; de meeste collecties zijn inmiddels gedigitaliseerd. De belangrijkste geo-informatie is nu wel digitaal, meestal zelfs gevectoriseerd. De laatste (analoge) collecties zijn nu meestal wel op zijn minst gescand. Scannen (onder andere in de vormen van verrasteren, vertiffen (omzetten in een TIF), en ver-PDF-en) is het proces waarbij (teksten, foto's kaarten of andere uitdrukkingsvormen op) documenten via een optisch invoerapparaat ('scanner') systematisch afgetast worden in een digitaal formaat. Door dit scannen is het verstrekken en verzenden van een kopie makkelijker. Deze vorm van digitaliseren is voor gewone documenten, regelgeving, besluiten, brieven en zelfs plattegronden, dwarsdoorsneden of projectkaarten misschien prima en genoeg. Echter, deze 'simpelste' en oudste vorm van digitalisering is voor geo-informatie meestal onvoldoende. De kaart (PDF of TIF) kan dan slechts gelinkt worden met een kaart. Klikken op een projectgebied en er verschijnt een nieuw scherm met daarin de tekening. Echt combineren, laat staan de individuele, getekende objecten aanklikken of selecteren kan niet. Geen enkele overlaytechniek is mogelijk. Geautomatiseerde bewerking (denk aan: "maak een lijst, voor elk object één regel, van in welke gebieden al deze objecten liggen") blijken onmogelijk. Terwijl de organisatie de gegevens wel in huis denkt te hebben – ja zelfs gedigitaliseerd! – kunnen deze relaties niet gelegd worden; het antwoord op deze vragen is elke keer weer handmatig uitzoekwerk. We moeten in deze gevallen dus een stap verder gaan met de mate van digitalisering. Het figuur hierna geeft – voor geo-informatie:
Algemene opmerkingen over het schema:
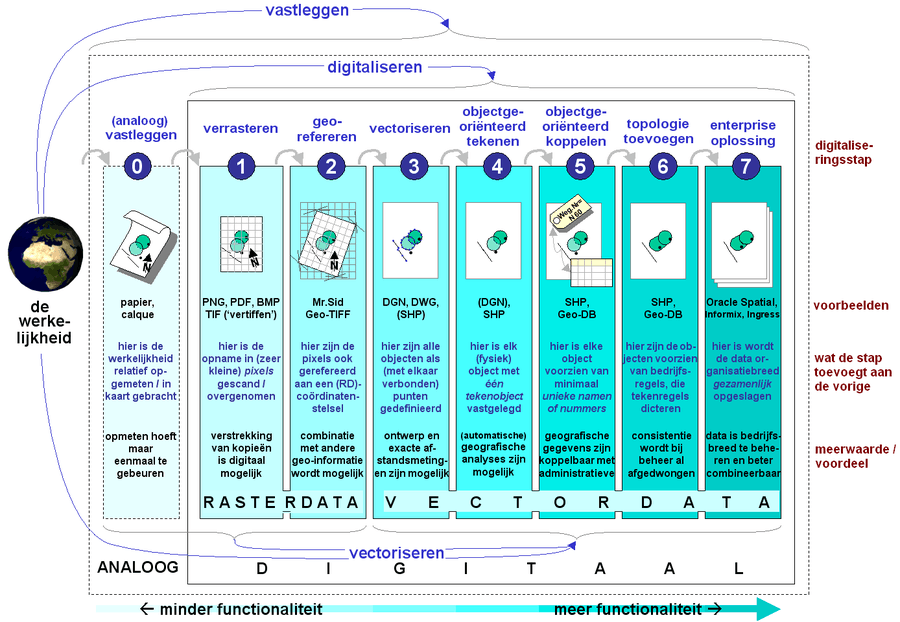 Definities van digitaliseren, vectoriseren en verrasteren met elkaar in verband gebracht; Gradaties in digitalisering bij geo-informatie zijn eveneens weergegeven en uitgelegd. Zie verder de tekst. In bovenstaand schema worden per gradatie in de digitalisering weergegeven:
Hoewel dit niet per definitie het geval is, ziet men vaak in de praktijk wel dat wanneer een bepaalde gradatie in digitalisering bereikt is – bijvoorbeeld gradatie 6 – dat dan de vorige gradaties / functionaliteiten bij de digitalisering ook mogelijk zijn. Vandaar dat er hier gekozen is niet alleen over zeven functionaliteiten te spreken, maar over zeven gradaties. Meer opmerkingen over de zeven getoonde digitaliseringsstappen:
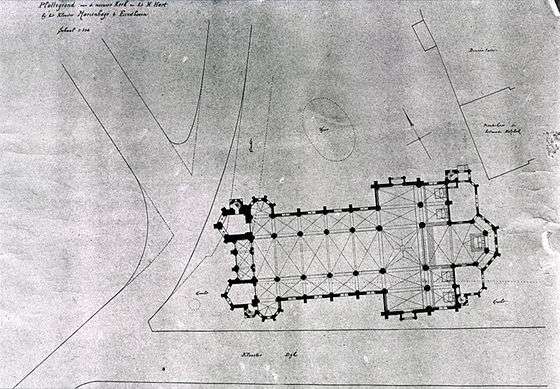 Voorbeeld van (oude) analoge kaart die door te scannen digitaal is gemaakt: Scan van een kaart van de Heilig Hartkerk te Eindhoven, inclusief omgeving (zie verder tekst).
Als laatste een voorbeeld van een kaart die digitaal is, maar wellicht niet 'genoeg' digitaal; zie de kaart van de kerk, rechtsboven. Een bibliothecaris vindt dit misschien afdoende. En misschien was de opdracht van het management ook om alle plattegronden/ kaarten te digitaliseren voor het nageslacht. Maar als er ook echt onderzoek, berekeningen, analyses, of bepaalde beheerwerkzaamheden moest worden uitgevoerd, was dat absoluut onvoldoende. Het is namelijk een JPG. Met wat metadata erbij is de afbeelding weliswaar vindbaar en kopieerbaar voor iedereen. Echter, de gegevens zijn niet gegeorefereerd, er kunnen geen (GIS-)analyses mee uitgevoerd worden en de kaart is niet combineerbaar met andere kaarten. Een simpele, aan GIS-afdelingen vaak gevraagde klus als op welke percelen of op welk bodemtype liggen de weg en de kerk, zijn pas mogelijk te maken als deze JPG gevectoriseerd en liefst ook objectgeoriënteerd wordt. Let op de noordpijl rechtsboven het midden. Ook op met CAD-programma's getekende kaarten/plattegronden, verraadt zo'n noordpijl vaak dat het géén gegeorefereerd bestand is. Dat beperkt toekomstig wellicht noodzakelijke GIS-functionaliteit enorm. Alleen viewen, niet op de juiste locatie, maar via een hyperlink vanuit een GIS-pakket of viewer is mogelijk. Referenties
LiteratuurVoor literatuur zie Overige informatie en links.
Ga naar de opdrachten over deze module 'Inleiding GIS'.
Ga verder met de volgende module: 'Vervolg GIS'. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||