| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Deze module gaat over de belangrijkste aspecten die spelen bij het classificeren van data, oftewel het omzetten van 'ruwe data' in een informatieve kaart, met een zinvolle legenda. Na het lezen kent de lezer verschillende classificatiemethoden en verschillende meetschalen en weet hij hoe deze om te zetten in de juiste legenda's.
Inleiding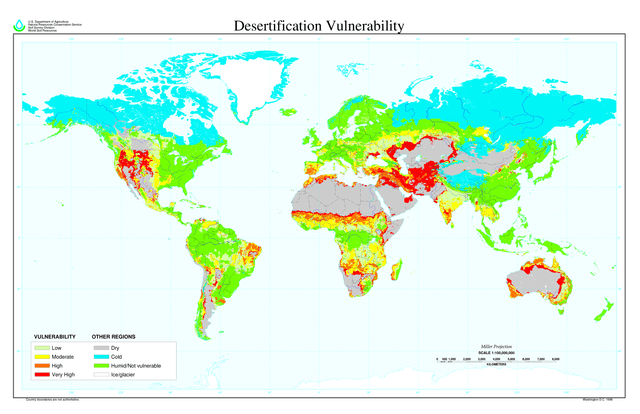 Een voorbeeld van een classificatie en een gekozen kleurenschema. Hier zijn gebieden geclassificeerd op de kans op verwoestijning. Hoe groter de kans op verwoestijning, hoe roder de kleur. Voordat je data ten behoeve van een kaart mooie legendakleuren kan geven, moet je deze data eerst classificeren. Daarbij moet je kennis hebben van de meetschaal waarmee deze data is ingedeeld. Deze module beschrijft classificatiemethoden, waarbij met name de geo-visualisatie van thematische kaarten aan de orde komt. Dit wordt met name geïllustreerd met één voorbeeld; het besteedbaar inkomen. Een kaart hiervan komt steeds weer in een ander gedaante tevoorschijn, zonder dat de data wijzigt. Daardoor komt het brede scala aan mogelijkheden aan de orde waar een GIS-specialist over beschikt. Duidelijk zal worden dat er écht steeds iets anders getoond wordt, waarbij elke kaart mogelijk voor een ander doel geschikt is. Achtereenvolgens komen aan de orde:
Met name thematische kartering via choropleten en chrochromatische kaarten komen aan de orde. Symbologie in zijn algemeenheid komt in de module hierna aan de orde. MeetschalenBij het maken van een kaart wordt per definitie een bepaalde grootheid van een bepaald thema (zoals houttransport, bereikbaarheid of bevolkingsdichtheid) ingewonnen met een bepaalde meetschaal (ook wel meetniveau genoemd). Zo zou de grootheid 'bereikbaarheid' misschien wel ingewonnen zijn in bereikbaarheidsklasses: A (0-15 minuten), B (15-30 minuten) en C (meer dan 30 minuten). Of de bereikbaarheid is gemeten in tijd: 0, 1, 16, 18, 19.33 minuten, et cetera. 'Bereikbaarheidsklasse' en 'tijd' zijn duidelijk verschillende meetschalen. Wanneer we hier kaarten van willen maken is het van belang om kennis te hebben van meetschalen. Bij het inwinnen van data is al voor een bepaalde meetschaal gekozen. Meetschalen worden in vier (of vijf) soorten ingedeeld (op volgorde van opklimmende toepasbaarheid/intelligentie):
Nominale en ordinale meetschalen beschrijven kwalitatieve datasets. Met een kwaliteit wordt een belangrijke eigenschap bedoeld waarmee iets aan een bepaald doel voldoet. Interval en ratio meetschalen daarentegen bschrijven kwantitatieve (getalsmatige) datasets. In het volgende schema worden de definities gegeven, tezamen met voorbeelden en enkele kenmerken. Helemaal rechts in de tabel staan voorbeelden van mogelijke kleurenschema's bij die meetschaal.
Over de tabel:
Een visualisatieschaal, met een aantal onderscheiden klassen in bepaalde kleuren is een wezenlijk ander begrip dan een meetschaal. Daar waar de data de objecten classificeert in de typen A, B, C, en D, kan de visualisatie A en B tot één klasse groeperen, en C en D in een tweede klasse groeperen. Een visualisatieschaal is zichtbaar voor de kaartlezer, een meetschaal (net zoals de eigenlijke data) is dat niet. Dit brengt een verantwoordelijkheid voor de kaartmaker met zich mee. Er mag niet zomaar een classificatie worden gekozen. Er moet enige kennis van de data aanwezig zijn. In de paragraaf hierna zal dit met een aantal voorbeelden over besteedbaar inkomen duidelijk worden. Bij het visualiseren kunnen:
Kleurenschema'sInmiddels zijn de soorten kleurenschema's al genoemd. Hieronder voor de volledigheid een overzicht voorbeelden:
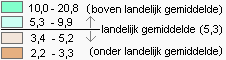
*) = Soms is het terecht tegenstellingen te benadrukken door contrasterende kleuren te kiezen (rood versus groen). Bijvoorbeeld als - bij de divergerende schaal - onder een armoedegrens of juist boven een armoedegrens uit komt. Of wanneer de politie of een assetmanager volgens het beleid zou moeten ingrijpen. Gaat het echter om het percentage van het aantal 70 plussers per gemeente, dan heeft ónder of boven een landelijk gemiddelde weinig te maken met goed of slecht. Je kiest dat wel twee goed onderscheidbare kleuren, maar geen tegengestelde kleuren. 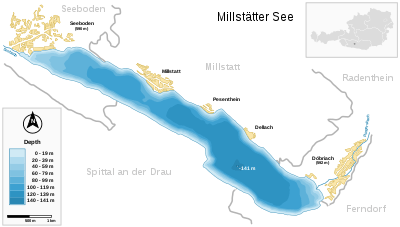 Een voorbeeld van een volgordelijk kleurenschema toegepast op vlakken (zie tekst)
Een voorbeeld van een meer in Oostenrijk (zie figuur rechts) toont hoe strak kaartsoorten, datasets en kleurenschema's qua mogelijkheden aan ekaar gebonden zijn. Het betreft een isolijnen (diepte-lijnen) kaart. De isolijnen zélf zijn echter door het GIS-programma onzichtbaar gehouden. Doordat de tussenliggende vlakken met verschillende blauwtinten zijn ingekleurd, is een choropleet ontstaan. Verder gaat het om een kwantitatieve dataset (diepte), een volgordelijk kleurenschema en er is als classificatiemethode voor het weergeven van de diepte gekozen voor een zogenaamde 'equal interval'-classificatie. Over classificatiemethodes is twee paragrafen verder meer te lezen.
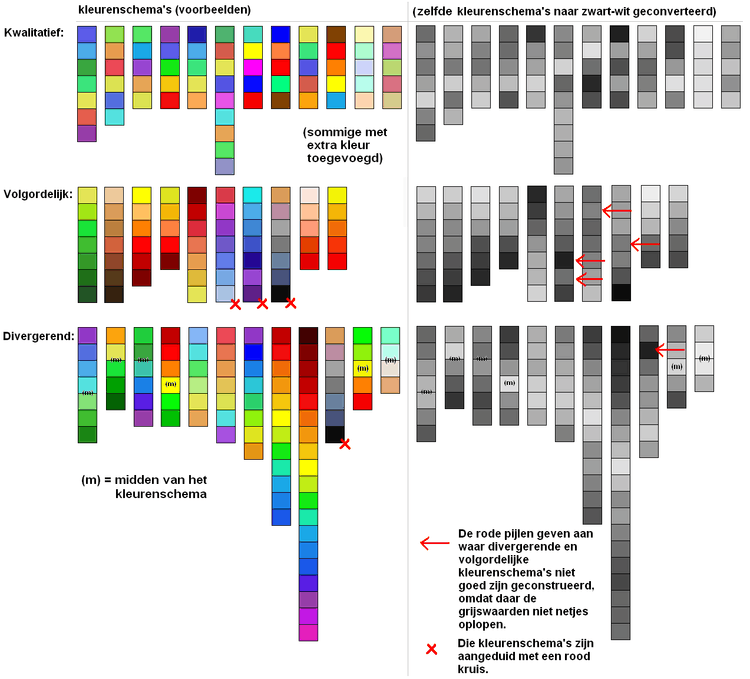 Voorbeelden van kleurenschema's (gesorteerd). Door kleurenschema's ook om te zetten naar zwart-wit (rechts in beeld), is te zien of de grijswaarden wel echt volgordelijk zijn. Het zijn immers de grijswaarden die via de oog-brein-combinatie de visuele volgordelijkheid bepalen, en niet de kleur! Zie verder tekst.
De visuele indruk van een kleurenschemaBij kwantitatieve data worden dus 'volgordelijke' kleurenschema's gebruikt. Deze paragraaf zal laten zien dat juist bij deze kwantitatieve data de kleur die deze data representeert niet zo maar vrij gekozen kan worden. Wat in eerste instantie van nature al geprobeerd zal worden, is om er voor zorgen dat onderlinge de kleuren maximaal van elkaar te onderscheiden zijn. Dit kan door te werken van licht naar donkerder, al of niet aangevuld door de donkere kleur nog verzadiger te laten worden. Jouw GIS komt meestal al met een aardig kleurenschema bij een eerste classificatie. (Zie ook de Kleuren verder op in deel B en de kleurenschema's die de Colorbrewer of misschien zelfs jouw GIS weten te creëeren). Echter niet alles gaat automatisch en makkelijk; de exacte kleuren die je kiest voor een legenda moeten namelijk in overeenstemming zijn met de data. Stem het gradueel laten oplopen van de verzadiging en / of het donkerder laten worden van de kleuren af op de dataset. Zie de figuur met de verschillende blauwe kleurenschema's. Stel voor dat hiermee bijvoorbeeld de neerslag van een gebied of de diepte van een meer wordt gerepresenteerd. Laten we de getoonde kleurenschema's eens bespreken. We gaan daarbij voor het gemak niet in op het aantal klassen dat gekozen is, dat is in deze paragraaf even niet het onderwerp. 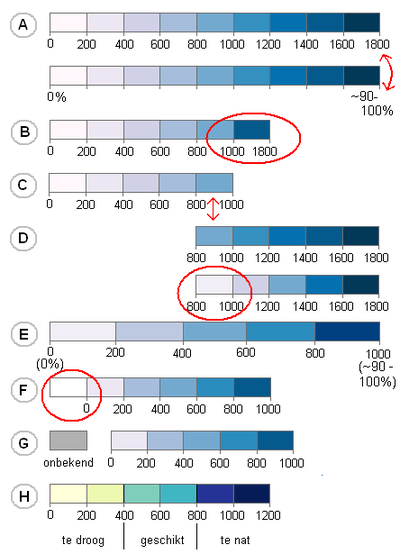 volgordelijk kleurenschema's in relatie tot de data. Het gaat hier bijvoorbeeld om neerslagcijfers in mm per jaar of dieptes in meters (zie verder tekst).
NB1: Merk dus op dat al deze kleurenschema's goed (kunnen) zijn. En merk op dat geen van de getoonde kleurenschema's in elk geval voldoet.
Normatieve en neutrale legenda's
Legenda's kunnen het beeld en daarmee de indruk van een kaart flink sturen. Hier rechts zie je twee legendavoorbeelden.
Geen van beide legenda's is fout, er is ook geen beste. Het zijn verschillende kleurenschema's die in verschillende situaties juist wel of juist niet gebruikt moeten worden. Een normatieve legenda / (of: normatief kleurenschema) is veel ingewikkelder dan een neutrale legenda (of neutraal kleurenschema). Zowel om te maken als om te lezen. Er dient goed over nagedacht te worden. Het hangt ook af 'van wie de kaart is'. Een reisorganisatie die huisjes wil aanprijzen, met daarbij een kaartje van attracties in de omgeving, zal eenzelfde soort bereikbaarheidskaart echt niet met dezelfde kleuren tonen als hierboven. Overheid, Brandweer, actiegroep 'buitenwijken beter bereikbaar' en actiegroep 'minder geld uittrekken voor de brandweer', zullen allen een andere legenda maken... In feite is een normatieve legenda niets anders dan een geclassificeerde volgordelijke legenda. Het gebruik van normatieve legenda'sNormatieve legenda's sturen de kaartlezer. Normatieve legenda's geven behalve informatie ook interpretatie. Je gaat aanvullende informatie toevoegen aan de legenda. Daardoor ontstaat een andere (of, als het goed is, betere) kaart. Er kunnen, vergelijkbaar als met de divergerende legenda's van hierboven, betere en snellere beslissingen mee worden genomen. Als je je als kaartmaker ook op deze wijze informatie verspreidt, bedenk dan dat je de indruk van een kaart sterk beïnvloedt; je stuurt de opinie van de kaartlezer. Je kan op deze wijze beslissingen en meningen van mensen sturen. Daar is niets mis mee. De kaart is een sterk visueel middel. Omdat op deze wijze grote hoeveelheden informatie, middels een plaatje, bij kunnen blijven bij mensen. Een actiegroep kan daar gerust gebruik van maken, zeker op het moment dat het als lezer duidelijk is waarvoor dat kaartje bedoeld is en voor welk medium en doelgroep het is ingezet. In de beleidsvorming, bij advisering, zeker bij eindrapporten, zijn normatieve legenda's zeer nuttig. De kaart (of het geografisch informatie systeem) is zo tot een 'decision supporting system' of beleidsondersteunend systeem gemaakt. Legendaopmaak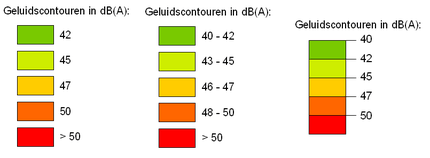 Drie voorbeelden van legenda's bij een isolijnen kaart, hier een geluidscontouren kaart. Alleen de rechter legenda is goed (waarom?: zie tekst). De linker legenda is ronduit fout en verschijnt vaak als eerste als je vraagt aan je GIS-programma om een legenda toe te voegen. De middelste legenda klopt gezien de klassegrenzen, maar is lastig leesbaar en dus matig vormgegeven. Wat je GIS-programma als eerste 'prompt' als opgemaakte legenda bij jouw kaart, zal qua en classificatie en de bijbehorende kleuren (immers, jij hebt er al over nagedacht) vast wel goed zijn. Echter de opmaak kan vaak veel beter. Onder andere bij isolijnenkaarten is dit het geval. Het is daarbij onder andere gebruikelijk de legendaeenheden tegen elkaar aan te zetten. Ook dienen de klassegrenzen zelf weer gegeven te worden, in plaats van bij elk vakje/kleurtje de bijbehorende range van getallen te plaatsen. Het scheelt niet alleen typen, maar belangrijker is dat er minder te lezen is voor de kaartlezer. Sterker. Binnen één bepaalde klasse is niet onderscheiden wat daar getalsmatig de waarde is, slechts op de grenzen daarvan is die waarde bekend. Vandaar dat je beter de klassegrenzen zelf in de legenda moet zetten, en deze legendaeenheden ook aan elkaar vast moet plaatsen. Immers, op de kaart zullen ze ook nooit losse vlakken vormen. De legenda komt zo natuurlijker over en de legenda wordt als één gelezen, in plaats van als verschillende vlakjes. Het is - ook als de kaart en het onderwerp nog niet meteen duidelijk zijn of bekeken zijn - meteen duidelijk dat het om een isolijnenkaart gaat. Zie figuur. Samengestelde kaarten en gecombineerde legenda's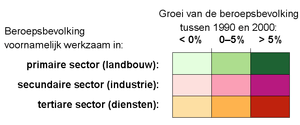 Voorbeeld van een gecombineerde legenda. Er zijn twee soorten samengestelde kaarten te definiëren:
De eerste genoemde soort (zie de voorbeeldlegenda) is vaak lastig te interpreteren en is vaak meer voor onderzoeksdoeleinden en ervaren kaartlezers bedoeld. Je ziet hem soms in atlassen. Vaak wordt met zo'n kaart gepoogd te kijken of er een verband is tussen beide weergegeven grootheden. In het voorbeeld zou een conclusie kunnen zijn: "of in een gebied nu werknemers voornamelijk uit de primaire, secundaire of tertiare sector komen, er is sowieso in de noordelijke gebieden een daling van de beroepsbevolking". Blijkbaar is er niet met het soort werk, maar de ligging van die gebieden een relatie met de afname van de beroepsbevolking. De licht gekleurde gebieden liggen dan allen in het noorden, maar het betreft zowel, groene, paarse als oranje kleuren, door elkaar heen. Wanneer alle lichte gebieden (met een afname dus) voornamelijk groen en paars zijn, zou er een andere conclusie getrokken worden: "in het noorden zie ik allemaal lichte kleuren, maar die lichte kleuren zie ik net zo goed in het zuiden, het zijn voornamelijk groene en paarse kleuren, dus de afname ligt niet aan de ligging, maar aan de sector die in die gemeente dominant is. Merk op dat er slechts een zeer gering aantal klassen (zowel horizontaal als verticaal) in een gecombineerde legenda moeten worden opgenomen. Een mens kan normaal slechts 8 klassen nog zien, maar dat is al met enige moeite.  Een voorbeeld van een volgordelijk kleurenschema toegepast op lijnen (zie tekst)  Zelfde afbeelding als hierboven, nu met groene ondergrond. Hierdoor is het een goed voorbeeld van een slechte kaart geworden, omdat de kleuren uit de voorgrond (de lijnen) niet meer objectief geïnterpreteerd kunnen worden (zie tekst).
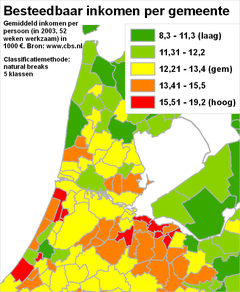
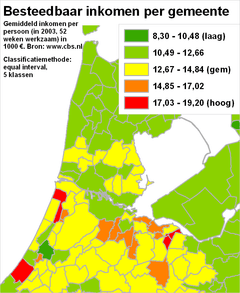
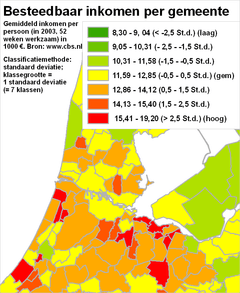
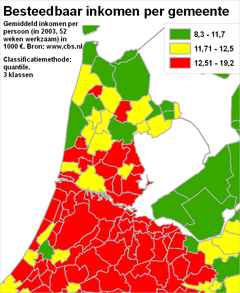
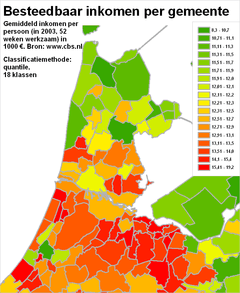
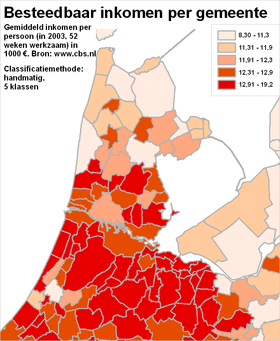
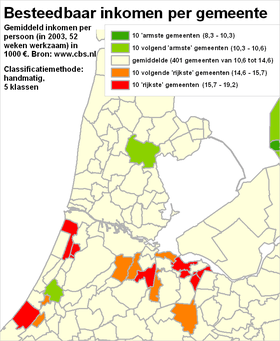
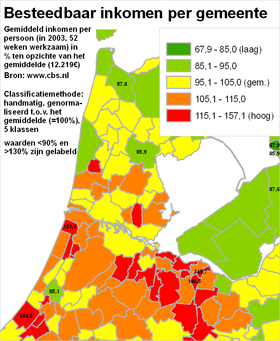
Het classificerenClassificeren is het indelen van verschijnselen of objecten in klassen op grond van overeenkomende of aanverwante eigenschappen. Dit indelen gebeurt door het aangeven van klassegrenzen. Bij nominale meetschalen is het classificeren relatief eenvoudig, omdat de individuele objecten al geclassificeerd zijn: die ene stad behoort nu eenmaal tot die ene provincie. Ook bij ordinale meetschalen is al een classificatie aangebracht: een gebied behoort nu eenmaal tot die ene grondwatertrap. Hooguit zou een kaartmaker er in bepaalde gevallen voor kunnen kiezen om bepaalde klassen toch samen te voegen. Onderstaande voorbeelden gaan vooral over het classificeren van gegevens die met een interval meetschaal of een ratio meetschaal zijn ingewonnen. Het classificeren zelf gaat (bijvoorbeeld met een GIS) heel gemakkelijk. Echter, het goed classificeren blijkt een hele kunst - net zoals het vervolgens toedelen van de juiste kleuren aan die klassen die zo ontstaan zijn (zie vorige paragrafen). Kijk maar eens naar de volgende vier kaarten. Hier zijn vier maal exact dezelfde gegevens over het besteedbaar inkomen per gemeente weergegeven. Er zijn steeds exact dezelfde legendakleuren gebruikt. Het doel van elke kaart is steeds een goed beeld te geven over de spreiding die er is tussen de gemeentes voor wat betreft de inkomens van de (gemiddelde) werknemers.
Merk op dat de kaarten verschillende visuele beelden achterlaten bij de kaartlezer:
NB: Was slechts één van deze kaarten in een krant, folder of website terechtgekomen, dan had waarschijnlijk bij geen enkele versie iemand de vraag gesteld 'zijn de klassegrenzen wel goed bepaald?'. De vragen die we daarom als verantwoordelijke kaartmaker moeten stellen zijn:
In de paragraaf hierna worden deze vragen beantwoord op basis van het voorbeeld van hierboven. Het is belangrijk om nu al vast te weten dat er géén één beste classificatiewijze is, en dat de te gebruiken classificatiewijze af hangt van het exacte doel van de kaart. Het classificeren komt neer op twee aspecten: het bepalen van klassegrenzen en het bepale van het aantal klassen. Het indelen op kleur is een aspect dat hier dus in principe buiten valt.
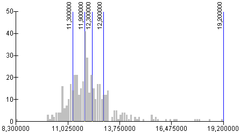
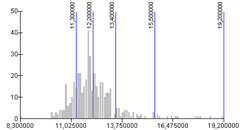
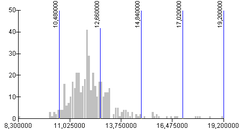
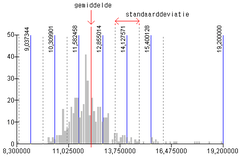
Klassegrenzen bepalenMet een GIS zijn meestal allerlei classificatiewijzen (allen voorzien van mooie, betrouwbare namen) makkelijk te selecteren en uit te voeren. Binnen no-time is er sprake van een mooie kaart. De voorbeelden hierboven tonen aan dat zomaar een keuze maken blijkbaar niet een goede werkwijze is; ze leveren echt verschillende kaarten op. Er zal dus naar die verschillen gekeken moeten worden. Dat kan door de verschillende kaarten zelf te vergelijken, zoals bij de bespreking van de vier kaarten van hierboven. Echter, het is beter de ruwe statistische gegevens te gaan bekijken. Op basis van die daadwerkelijke gegevens moet de classificatie bepaald worden, tezamen met het doel van de kaart. Laten we daarom eerst eens wat beter kijken naar de daadwerkelijke gegevens zelf. De hierboven met vier kaarten geïllustreede, verschillende classificaties zien er - in dezelfde volgorde - statistisch gezien zo uit:
Deze vier diagrammen geven steeds dezelfde data weer. Deze worden door de grijze kolommen weergegeven. Voor alle diagrammen zijn deze dus hetzelfde. Op de horizontale as staan de meetwaarden, dus in dit geval, de gemiddelde inkomens per gemeente. Op de verticale as is te zien hoe vaak die individuele meetwaarden voorkomen. In dit voorbeeld komt de klasse rondom 12 het vaakste voor, in zo'n 40 gemeenten. De spreiding van aantallen over alle individuele meetwaarden wordt in de statistiek een verdeling genoemd. In blauw zijn de toegepaste klassegrenzen te zien. Dat zijn de enige verschillen tussen de vier diagrammen. Hoewel in werkelijkheid verdelingen binnen datasets erg onregelmatig kunnen en zullen verlopen, is het toch zo dat de verdelingen vaak een op een patroon lijken. De statistiek beschrijft onder andere de volgende verdelingen:
NB:
Jij als kaartenmaker alleen, hebt dus de beschikking over de ruwe data, in dit geval, de exacte gemiddelde inkomensgegevens van de individuele gemeenten. Jij hebt een beeld van de voorkomende meetwaarden en de verdeling. Door te classificeren 'sla je de data plat', populair gezegd . Je maakt van de ruwe data een mooi, visueel aantrekkelijk plaatje. Beter gezegd: van data maak je informatie. Data is een onoverzichtelijke hoeveelheid gegevens. Zou je er voor kiezen om elke afzonderlijke gemeenten één kleur te geven, die afhangt van het gemiddelde inkomen, of je zou in elke gemeente het exacte getal weergeven dat overeenkomt met het gemiddelde inkomen, dan breng je alle data - onverdund - in kaart. Het zal nog steeds een onoverzichtelijke brij aan data zijn. Dat is niet de bedoeling van een goede kaart. Een goede kaart maakt wel degelijk keuzes. Je vat de brij samen. Als informatiemakelaar (zie Deel A) heb je die plicht om dit goed te doen. De kaartenlezer beschikt immers niet over de data achter de kaart, en kan het visuele beeld niet verifiëren, laat staan mentaal corrigeren (zie eerder in dit Deel B, over Bertin). Laten we de vier inmiddels genoemde classificatiewijzen eens op een rij zetten en beschrijven:
Er zijn overigens nog meer statistische methodes om de dataset in klassen te verdelen, namelijk die geclassificeerd worden op basis van de verdeling in de dataset, zoals op basis van aritmische, harmonische of geometrische verdelingen. Meer over deze laatst genoemde verdelingen, statistische kartering en dataclassificatie is onder andere te lezen in Kraak en Ormeling [1].
Het aantal klassenBij een classificatie dient, zoals eerder genoemd, ook het aantal klassen bepaald te worden. Bij een nominale schaal - of anders gezegd, op een chorochromatische kaart - wordt dit aantal vaak gedicteerd door de data zelf: Een provinciekaart van Nederland kent nu eenmaal 12 provincies, en een bodemkaart kent nu eenmaal tientallen bodemsoorten, en dus ook evenzoveel legendaeenheden. Bij dergelijke kaarten is het vooral een kwestie van kleuren groeperen, dus alle bodemsoorten op zand krijgen een zandige kleur (geel-oranje), en alle veen-bodemsoorten krijgen een lichte tot donkere paarse kleur. Desgewenst kan je het aantal klassen verminderen, door deze te groeperen: alle bodemsoorten op zand krijgen één (geel oranje) kleur. Hiermee wordt de kaart veel leesbaarder. Of dit mogelijk is, hangt af van het doel van de kaart.
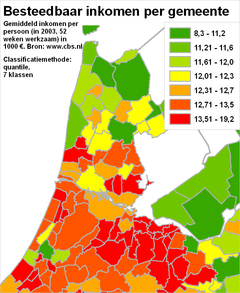
Ook bij een ordinale meetschaal (geluidsniveau's, grondwatertrappen) wordt het aantal klassen gedicteerd door de data; het aantal klassen staat min of meer vast, omdat er al een ordening - en dus ook een indeling - is aangebracht. Het samenvoegen kan (soms) wenselijk zijn, maar meestal is die indeling al niet voor niets zo in de dataset aangebracht. De classificatie is in feite al gebeurd. De volgorde (in tegenstelling tot de hierboven besproken schalen) ligt wel vast; dat betekent dat er een zelfde volgordelijkheid in de kleuren in de legenda moet terugkomen (zie hiervoor in de paragraaf over meetschalen en kleurenschema's). Zorg dat de oplopende kleuren ongeveer diezelfde 'beweging' in de data volgen. Is er (bijvoorbeeld in het geval van grondwatertrappen) misschien een opdeling te make in het aantal klassen (grondwatertrappen) waardoor er twee groepen ontstaan? Geef de 'droogste' groep dan kleuren die min of meer bij elkaar horen - en langzaam oplopen qua grijswaarde of verzadiging - en doe dat voor de 'natste' groep met een andere (blauwere) kleur. Bij de overige kwantitatieve schalen, is het lastiger - anders gezegd - hebben we meer mogelijkheden. Interval en ratio meetschalen kennen in theorie een oneindig aantal tussenliggende meetwaarden. We kunnen dus ook in theorie kiezen voor het splitsen van de data over 2, 3, 10, 100 of 1000 klassen. Bij 100 en 1000 klassen hebben we al gauw het gevoel dat we niet goed bezig zijn. Maar wat is dan wel goed? Vergelijk eens de volgende kaarten, die exact weer hetzelfde fenomeen beschrijven als eerder: het gemiddelde besteedbaar inkomen per gemeente.
Merk op dat de kaarten - opnieuw - verschillende visuele beelden achterlaten bij de kaartlezer:
Duidelijk is dat 3 klassen onvoldoende is en 18 klassen niets toevoegd, behalve onduidelijkheid. De manier van classificeren lijkt dus van invloed op de spreiding van het fenomeen, vanuit het oogpunt van de kaartlezer bezien althans. Opnieuw blijkt hier weer de verantwoordelijkheid van de kaartmaker. Het is dus duidelijk dat je met het aantal klassen waarmee je gaat karteren moet experimeteren. Let op - net als hierboven besproken bij het bepalen van klassegrenzen - wat voor beeld de kaart achterlaat, of bepaalde klassen wèl gevuld zijn en zo ja met hoeveel meetwaarden. En zoals het beeld naar voren komt, sluit dat aan bij het doel van de kaart? In het voorbeeld met het besteedbaar inkomen kan het zijn dat je tóch kiest om de gegevens in 7 of 9 klassen op te delen, bijvoorbeeld omdat je wil dat het duidelijk is dat onderlinge gemeentes, die net even wat meer of minder verdienen, toch wilt kunnen vergelijken. De algehele spreiding van het fenomeen ('gemiddeld inkomen per gemeente') blijft intakt. Gaat het echter alléém om die spreiding, dan blijkt hier dat 5 klassen voldoende is; de kaarten met 7 en 18 klassen hebben echt geen meerwaarde voor wat betreft een beter, visueel beeld van die spreiding. Voor het gehele beeld van Nederland is een verdeling in 5 klassen in dit geval voldoende. Overigens, iemand die bewust de verschillen tussen de rijke Randstad en 'het platteland' wil benadrukken, zou juist toch voor 3 klassen kunnen kiezen. Wel zal hij hierin een iets minder overheersende kleur moeten kiezen; immers, de klassemiddens van al die rijke gemeenten, zijn helemaal niet zo maximaal rijk als die volle kleur rood bij de kaartlezer misschien doet vermoeden.
Lessen uit het classificerenTijdens het classificeren zien we heel exact hoe de ruwe dataset er écht uit ziet. Bij het testen van classificatie(methode)s leren we de data goed kennen. Misschien zijn we als GIS-specialist zelf al de (deskundige) onderzoeker van die data. Er zijn bij dit proces van het testen meerdere 'mislukte' en 'gelukte' kaarten verschenen. Dit testen is niet voor niets, de GIS-specialist is bevoorrecht. We kunnen door al die kennis namelijk bepaalde lessen trekken uit het classificeren. Het kan goed zijn dat we hierdoor besluiten toch een andere kaart te gaan maken dan we oorspronkelijk dachten. Allerlei ander technieken kunnen de scherpe kanten van bepaalde classificatiemethoden er af halen. Zo leggen de kaarten weer een andere nadruk of zijn ze nog makkeliker door de kaartlezer te lezen doordat de boodschap nog kernachtiger is, of de informatie nog verder toegespitst. Te denken valt aan:
Met name het laatste aspect is nog niet naar voren gekomen in het verhaal over het besteedbare inkomen. Er is 'zomaar' gekozen voor een divergerende kleurschaal. Één neutrale gele kleur in het midden, de kleuren lopen naar de minimale en maximale waarden toe langzaam uiteen naar twee andere, tegenovergestelde kleuren. Misschien willen we helemaal geen verschillen benadrukken! Dan moeten we ook helemaal géén verschillende kleurtinten gebruiken, maar één kleurtint die langzaam donkerder wordt. Dat is een volgordelijke schaal. Door toepassing van de divergerende schaal hebben we misschien onbewust een extra, visuele classificatie toegebracht. Dat is extra informatie of een mening! Wellicht is dat niet juist en niet objectief. Een kaartlezer associeert in meer of mindere mate - en bewust of onbewust - kleuren met bepaalde eigenschappen. Rood is rijk of misschien wel slecht. En groen is arm, rustig of landelijk (zie eventueel het stuk over kleurassociaties). Delft is bijvoorbeeld groen, maar niet landelijk. Meer over kleuren weten? Zie Kleuren). Kortom, besef dat het ook anders kan. Hieronder een aantal voorbeelden.
Merk op ook deze kaarten - nog steeds dezelfde dataset! - verschillende visuele beelden achterlaten bij de kaartlezer:
Proportionele symbolen / Legenda's bij figuratieve kaarten Legenda voorbeelden waarmee de data geclassificeerd (boven) en ongeclassificeerde (onder) in beeld wordt gebracht. Figuratieve kaarten geven kwantitatieve data weer door middel van proportionele symbolen. Dat wil zeggen, de grootte van de symbolen is evenredig met de data. Meestal is de grootte van de symbolen zelfs rechtevenredig met de data - zoals in beide voorbeelden rechts - maar dat hoeft niet. Je kan er namelijk voor kiezen om lage waarden meer te laten opvallen en grote, extreme waarden relatief kleiner weer te geven. bijvoorbeeld wanneer het de verdeling van de data erg asymmetrisch is. De legenda kan bij figuratieve kaarten op twee manieren worden weergegeven (zie figuur):
Bij het de geclassificeerde legenda zijn er een beperkt aantal symboolgroottes te zien. De symboolgrootte dient proportioneel te zijn met de klassemiddens.
Bij de ongeclassificeerde legenda zijn er een 'oneindig' aantal symboolgroottes te verwachten. In de legenda worden meestal een aantal tussenliggende voorbeelden opgenomen, maar sowieso dienen de kleinste en de grootste symbolen te zijn opgenomen. Er kunnen figuratieve symbolen (kerstbomen, of kruizen) gebruikt worden bij figuratieve kaarten, echter, abstracte wiskundige symbolen zoals cirkels of staven zijn bij het proportioneel weergeven van die symbolen veel beter leesbaar. In het begin van deel B bleek het al: het voordeel van cirkels boven staafdiagrammen is dat op met cirkels een sterk uiteenlopende dataset beter gevisualiseerd kan worden; dat komt omdat een cirkel een oppervlakte heeft, en een staaf een lengte. Echter, het menselijk oog neemt de grootte van een cirkel niet zo goed waar. Dat komt omdat eerder de doorsnede ervaren wordt dan de oppervlakte. Grote waarden worden dus te laag beoordeeld, kleinere cirkels vallen daarentegen te veel op. Dit heet het Flannery-effect. Overigens, bollen gebruiken om een volume weer te geven (zoals m3 LPG in de Rotterdamse haven) is helemaal gevaarlijk. 3D figuren gebruiken voor proportioneel kan het oog (immers op scherm of papier weergegeven) helemaal slecht in schatten (een soort dubbel Flannery-effect). Grote bollen worden véél te klein ingeschat. Gebruik driedimensionale symbolen dus alleen bij zeer sterk uiteenlopende (volume)cijfers. Cirkels kan je gewoon voor aantallen, oppervlaktes en inhoud gebruiken. Een legenda is bij dergelijke proportionele kaarten dus echt een must.
Referenties
LiteratuurVoor literatuur zie Overige informatie en links.
Ga naar de opdrachten en vragen over deze module 'Classificatie'.
Ga verder met Deel B: Symbologie. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||