Marginal distribution
In probability theory and statistics, the marginal distribution of a subset of a collection of random variables is the probability distribution of the variables contained in the subset. It gives the probabilities of various values of the variables in the subset without reference to the values of the other variables. This contrasts with a conditional distribution, which gives the probabilities contingent upon the values of the other variables.
| Part of a series on statistics |
| Probability theory |
|---|
 |
Marginal variables are those variables in the subset of variables being retained. These concepts are "marginal" because they can be found by summing values in a table along rows or columns, and writing the sum in the margins of the table.[1] The distribution of the marginal variables (the marginal distribution) is obtained by marginalizing – that is, focusing on the sums in the margin – over the distribution of the variables being discarded, and the discarded variables are said to have been marginalized out.
The context here is that the theoretical studies being undertaken, or the data analysis being done, involves a wider set of random variables but that attention is being limited to a reduced number of those variables. In many applications, an analysis may start with a given collection of random variables, then first extend the set by defining new ones (such as the sum of the original random variables) and finally reduce the number by placing interest in the marginal distribution of a subset (such as the sum). Several different analyses may be done, each treating a different subset of variables as the marginal variables.
Definition
Marginal probability mass function
Given a known joint distribution of two discrete random variables, say, X and Y, the marginal distribution of either variable--X for example--is the probability distribution of X when the values of Y are not taken into consideration. This can be calculated by summing the joint probability distribution over all values of Y. Naturally, the converse is also true: we can obtain the marginal distribution for Y by summing over the separate values of X.
, and


X Y | x1 | x2 | x3 | x4 | pY(y) ↓ |
|---|---|---|---|---|---|
| y1 | 4/32 | 2/32 | 1/32 | 1/32 | 8/32 |
| y2 | 3/32 | 6/32 | 3/32 | 3/32 | 15/32 |
| y3 | 9/32 | 0 | 0 | 0 | 9/32 |
| pX(x) → | 16/32 | 8/32 | 4/32 | 4/32 | 32/32 |
| Table. 1 Joint and marginal distributions of a pair of discrete random variables, X and Y, dependent, thus having nonzero mutual information I(X; Y). The values of the joint distribution are in the 3×4 rectangle; the values of the marginal distributions are along the right and bottom margins. | |||||
A marginal probability can always be written as an expected value:

Intuitively, the marginal probability of X is computed by examining the conditional probability of X given a particular value of Y, and then averaging this conditional probability over the distribution of all values of Y.
This follows from the definition of expected value (after applying the law of the unconscious statistician)

Therefore, marginalization provides the rule for the transformation of the probability distribution of a random variable Y and another random variable X = g(Y):

Marginal probability density function
Given two continuous random variables X and Y whose joint distribution is known, then marginal probability density function can be obtained by integrating the joint probability distribution, , over Y, and vice versa. That is

and


where , and .


Marginal cumulative distribution function
Finding the marginal cumulative distribution function from the joint cumulative distribution function is easy. Recall that
for discrete random variables,

for continuous random variables,

If X and Y jointly take values on [a, b] × [c, d] then


If d is ∞, then this becomes a limit . Likewise for .


Marginal distribution and independence
Definition
Marginal distribution functions play an important role in the characterization of independence between random variables: two random variables are independent if and only if their joint distribution function is equal to the product of their marginal distribution functions,[2]
for discrete random variables,

for continuous random variables,

that is,

for all possible values x and y.[3]
Examples
- Discrete random variables
Let X and Y be two discrete random variables having joint distributions (See Table.2),
X Y | x1 | x2 | x3 | pY(y) ↓ |
|---|---|---|---|---|
| y1 | 1/12 | 4/12 | 1/12 | 1/2 |
| y2 | 1/12 | 4/12 | 1/12 | 1/2 |
| pX(x) → | 1/6 | 2/3 | 1/6 | 1 |
| Table. 2 Joint and marginal distributions of a pair of independent discrete random variables, X and Y. The values of the joint distribution are in the 3×2 rectangle; the values of the marginal distributions are along the right and bottom margins. | ||||
we can easily conclude from this table that
, which is the same as

.

Thus, discrete random variables X and Y are independent.
- continuous random variables[2]
Let X and Y be two random variables having marginal distribution functions


and joint distribution function

It is easy to check that

Marginal distribution vs. conditional distribution
Definition
The marginal probability is the probability that one of the variables takes a particular value: , disregarding what the values of the other variables are. In essence, we are calculating the probability of one independent variable. A conditional probability is the probability that an event will occur given that another specific event has already occurred. We say that we are placing a condition on the larger distribution of data, or that the calculation for one variable is dependent on another variable.[4]

The relationship between marginal distribution is usually described by saying that the conditional distribution is the joint distribution divided by the marginal distribution.[5] That is,
for discrete random variables,

for continuous random variables.

Example
Suppose we are trying to understand the relationship in a classroom of 200 students between the amount of time studied (X) and the percent correct (Y).[6] We can assume X and Y are discrete random variables representing the amount of time studied and the percent correct, respectively. Then the joint distribution of X and Y can simply be described by listing all the possible values of p(xi,yj), as shown in Table.3.
X Y |
Time studied (minutes) | |||||
|---|---|---|---|---|---|---|
| % correct | x1 (0-20) | x2 (21-40) | x3 (41-60) | x4(>60) | pY(y) ↓ | |
| y1 (0-20) | 2/200 | 0 | 0 | 8/200 | 10/200 | |
| y2 (21-40) | 10/200 | 2/200 | 8/200 | 0 | 20/200 | |
| y3 (41-59) | 2/200 | 4/200 | 32/200 | 32/200 | 70/200 | |
| y4 (60-79) | 0 | 20/200 | 30/200 | 10/200 | 60/200 | |
| y5 (80-100) | 0 | 4/200 | 16/200 | 20/200 | 40/200 | |
| pX(x) → | 14/200 | 30/200 | 86/200 | 70/200 | 1 | |
| Table.3 Two-way table of dataset of the relationship in a classroom of 200 students between the amount of time studied and the percent correct | ||||||
If we want to study how many students who got a score below 20 in the test, we need to calculate the marginal distribution. To translate it into a statistical problem, we can derive the equation: ,which means, 5% of the students get a score lower than 20 in the test, that is, 10 students.

In another case, if we want to study the probability that the students studied more than 60 minutes but got a score lower than 20, we need to calculate the conditional distribution. Here, the given condition is that those students studied more than 60 minutes, namely, . According to the equation given above, we can calculate that .


Real-world example
Suppose that the probability that a pedestrian will be hit by a car, while crossing the road at a pedestrian crossing, without paying attention to the traffic light, is to be computed. Let H be a discrete random variable taking one value from {Hit, Not Hit}. Let L (for traffic light) be a discrete random variable taking one value from {Red, Yellow, Green}.
Realistically, H will be dependent on L. That is, P(H = Hit) will take different values depending on whether L is red, yellow or green (and likewise for P(H = Not Hit)). A person is, for example, far more likely to be hit by a car when trying to cross while the lights for perpendicular traffic are green than if they are red. In other words, for any given possible pair of values for H and L, one must consider the joint probability distribution of H and L to find the probability of that pair of events occurring together if the pedestrian ignores the state of the light.
However, in trying to calculate the marginal probability P(H = Hit), what is being sought is the probability that H = Hit in the situation in which the particular value of L is unknown and in which the pedestrian ignores the state of the light. In general, a pedestrian can be hit if the lights are red OR if the lights are yellow OR if the lights are green. So, the answer for the marginal probability can be found by summing P(H | L) for all possible values of L, with each value of L weighted by its probability of occurring.
Here is a table showing the conditional probabilities of being hit, depending on the state of the lights. (Note that the columns in this table must add up to 1 because the probability of being hit or not hit is 1 regardless of the state of the light.)
L H |
Red | Yellow | Green |
|---|---|---|---|
| Not Hit | 0.99 | 0.9 | 0.2 |
| Hit | 0.01 | 0.1 | 0.8 |

To find the joint probability distribution, more data is required. For example, suppose P(L = red) = 0.2, P(L = yellow) = 0.1, and P(L = green) = 0.7. Multiplying each column in the conditional distribution by the probability of that column occurring results in the joint probability distribution of H and L, given in the central 2×3 block of entries. (Note that the cells in this 2×3 block add up to 1).
L H |
Red | Yellow | Green | Marginal probability P(H) |
|---|---|---|---|---|
| Not Hit | 0.198 | 0.09 | 0.14 | 0.428 |
| Hit | 0.002 | 0.01 | 0.56 | 0.572 |
| Total | 0.2 | 0.1 | 0.7 | 1 |

The marginal probability P(H = Hit) is the sum 0.572 along the H = Hit row of this joint distribution table, as this is the probability of being hit when the lights are red OR yellow OR green. Similarly, the marginal probability that P(H = Not Hit) is the sum along the H = Not Hit row.
Multivariate distributions
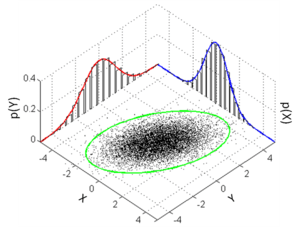
For multivariate distributions, formulae similar to those above apply with the symbols X and/or Y being interpreted as vectors. In particular, each summation or integration would be over all variables except those contained in X.[3]
That means, If X1,X2,...,Xn are discrete random variables, then the marginal probability mass function should be
;

if X1,X2,...Xn are continuous random variables, then the marginal probability density function should be
.

See also
References
- Trumpler, Robert J. and Harold F. Weaver (1962). Statistical Astronomy. Dover Publications. pp. 32–33.
- "Marginal distribution function". www.statlect.com. Retrieved 2019-11-15.
- A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 9781852338961. OCLC 262680588.CS1 maint: others (link)
- "Marginal & Conditional Probability Distributions: Definition & Examples". Study.com. Retrieved 2019-11-16.
- "Exam P [FSU Math]". www.math.fsu.edu. Retrieved 2019-11-16.
- Marginal and conditional distributions, retrieved 2019-11-16
Bibliography
- Everitt, B. S.; Skrondal, A. (2010). Cambridge Dictionary of Statistics. Cambridge University Press.
- Dekking, F. M.; Kraaikamp, C.; Lopuhaä, H. P.; Meester, L. E. (2005). A modern introduction to probability and statistics. London : Springer. ISBN 9781852338961.CS1 maint: multiple names: authors list (link)