Regressie-analyse
Regressie-analyse is een statistische techniek voor het analyseren van gegevens waarin (mogelijk) sprake is van een specifieke samenhang, aangeduid als regressie. Deze samenhang houdt in dat de waarde van een stochastische variabele (de afhankelijke variabele), op een storingsterm na, afhangt van een of meer in principe instelbare vrij te kiezen variabelen. De afhankelijke variabele wordt meestal met aangeduid en de onafhankelijke variabele met (eventueel als vector). Het verband is dan:


- ,

Hierin stelt de storingsterm voor, die onafhankelijk is van (dat wil zeggen dat men aanneemt dat de volledige variatie te wijten is aan een fout in ).

De functie is in de relatie onbekend, maar voor toepassing van regressie-analyse behoort deze wel tot een bepaalde klasse die met een beperkt aantal parameters beschreven kan worden. Het paar wordt wel aangeduid als onafhankelijke en afhankelijke variabele of als verklarende en te verklaren variabele; ook wordt wel gesproken van voorspeller en responsvariabele, of predictor en criteriumvariabele.


Terminologie
- Onafhankelijke variabele
- Deze variabele wordt ook instelvariabele genoemd. De waarde van de variabele wordt bepaald door de keuzes die door degene die het experiment uitvoert gemaakt worden.
- Afhankelijke variabele
- De waarde van de afhankelijke variabele is het gevolg van de keuzes die gemaakt zijn bij de instelvariabele(n). De afhankelijke variabele is een stochastische variabele.
- Regressie
- De terminologie "regressie", teruggang, is in dit verband eigenlijk misplaatst. De term werd voor het eerst gebruikt door de Engelse antropoloog Francis Galton. Hij merkte namelijk op dat kinderen uitzonderlijke eigenschappen van hun ouders overerven, doch dat er een tendens bestaat van "regressie naar het midden". De kinderen nemen de eigenschappen van hun ouders namelijk in afgezwakte mate over. Zo hebben lange ouders, lange kinderen, en korte ouders korte kinderen, maar steeds minder uitgesproken. Galton ontdekte dit verband door het toepassen van de methode van de kleinste kwadraten en noemde ze naar het door hem bestudeerde fenomeen, regressie-analyse. Later verfijnde Karl Pearson de rekenmethode en behield de door Galton aangewende psycho-antropologische terminologie.
Voorbeeld
Het benzineverbruik van een bepaald type auto hangt af van de snelheid waarmee gereden wordt. Beredeneerd kan worden dat dit verband kwadratisch is en wel als volgt:
- .

Afhankelijk van omstandigheden als wegdek, verkeerssituatie, weersomstandigheden e.d., zal het benzineverbruik bij eenzelfde snelheid toch nog variaties vertonen, die weergegeven worden als storingsterm . Met de gegevens verkregen uit een aantal testritten (steekproef) zal men door middel van regressie-analyse de parameters schatten.
Lineaire regressie
Er is sprake van lineaire regressie als de bovengenoemde functie een lineaire functie is van de verklarende variabelen.
Enkelvoudige lineaire regressie
Eenvoudig
Het idee dat in de berekening wordt uitgewerkt is het volgende:
- De gemiddelde waarde van alle x-waarden zal een waarde voor opleveren die dicht bij de gemiddelde y-waarde ligt. Het punt is het uitgangspunt voor de lijn.
- De waarde van de helling van de lijn ligt waarschijnlijk dicht bij de gemiddelde waarde van alle hellingen die ontstaan als elk meetpunt verbonden wordt met het hierboven aangegeven .


De rekenkundige uitwerking van bovenstaande punten volgt hieronder.
Rekenkundige benadering
In het eenvoudigste geval is er slechts één verklarende variabele . We spreken dan van enkelvoudige lineaire regressie. Het model voor wordt dan:
- .

Meestal wordt de storingsterm normaal verdeeld verondersteld met verwachting 0 en standaardafwijking σ.
We kunnen de parameter σ, die meestal ook onbekend is, ook direct zichtbaar maken in de relatie:
- ;

waarin nu standaardnormaal verdeeld is.
Met methoden uit de schattingstheorie worden de parameters van deze lineaire relatie geschat.
Omdat een schatting gebaseerd is op het resultaat van een steekproef, kan het analyseren van enkelvoudige lineaire regressie opgevat worden als het bepalen van de best passende lijn door de gegeven meetpunten. Wat "best passen" betekent is natuurlijk afhankelijk van het gehanteerde criterium. Een zo'n criterium is het "kleinste-kwadratencriterium". Daarvoor wordt de kleinste-kwadratenmethode gebruikt. Van lijn worden de coëfficiënten en zodanig berekend dat de som van de kwadraten van alle afwijkingen van het meetpunt ten opzichte van de lijn (zie figuur) minimaal is.




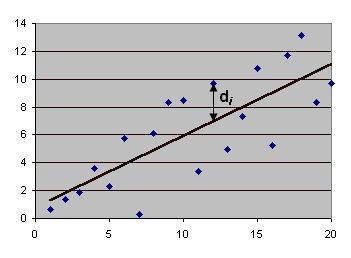
Theorie
We bekijken het geval van enkelvoudige lineaire regressie. Bij verschillende waarden van de verklarende variabele worden de waarden van de bijbehorende stochastische variabelen waargenomen. Deze stochastische variabelen worden verondersteld onderling onafhankelijk te zijn. Het model voor de steekproef is dus:




waarin de onderling onafhankelijk zijn en alle N(0,1)-verdeeld. Het gaat er nu om schattingen te geven voor de parameters op basis van de steekproefuitkomst . Meestal gebruikt men daarvoor de kleinste-kwadratenmethode. De daaruit resulterende kleinste-kwadratenschatters en voor resp. en worden gegeven door:





en
- .

Ook de parameter kan geschat worden, en wel door:

- .

Herhalingen
Als bij dezelfde waarde van de verklarende variabele meer dan één waarneming is gedaan, kan de parameter geschat door middel van de variantie binnen deze groepen. Het model is dan:

waarin de weer onderling onafhankelijk zijn en alle N(0,1)-verdeeld.

(NB. De groepen zijn hier voor de eenvoud alle van gelijke omvang gekozen; noodzakelijk is dit niet.)

In de formules voor de schattingen en voor resp. en moet nu overal de bij horende y-waarde vervangen worden door het gemiddelde


van die groep. Een schatting van is;
- .

De kwadratensom hierin is een van de termen uit de variantieanalyse, waarin de totale kwadratensom uiteenvalt in drie delen:
- .

De laatste term daarin is de kwadratensom ten gevolge van de regressie. De middelste term meet de afwijkingen van de groepsgemiddelden ten opzichte van de geschatte regressielijn, en is daarmee een maat voor het goed passen van het model.
Meervoudige lineaire regressie
Zijn er meer verklarende variabelen, maar is wel een lineaire functie daarvan, dan spreken we van multipele (of meervoudige) lineaire regressie. Het model heeft de vorm:
- ,

met weer N(0,1)-verdeeld.
Ook hier worden met de kleinste-kwadratenmethode de parameters geschat. De analyse verloopt geheel analoog aan het enkelvoudige geval. Het is alleen rekentechnisch ingewikkelder.

Theorie
Ook hier worden bij verschillende waarden van de verklarende variabelen de waarden van de bijbehorende stochastische variabelen waargenomen. Deze stochastische variabelen worden verondersteld onderling onafhankelijk te zijn. Het model voor de steekproef is dus:



waarin de onderling onafhankelijk zijn en alle N(0,1)-verdeeld. Het is overzichtelijker deze relaties met vectoren te noteren, waardoor ze in gedaante sterk vereenvoudigen.
- .

Hierin is en . De waarden van de 'en vinden we terug in de matrix , waarvan de -de rij gegeven wordt door:




- .

De kleinste-kwadratenmethode voert tot de normaalvergelijkingen:
- .

In de gebruikelijke gevallen is de matrix inverteerbaar, zodat de oplossing, de kleinste-kwadratenschatters, gegeven wordt door:

- .

Voorbeeld
temperatuur
(in °C)lengte
(in mm)20 1000,02 60 1000,96 100 1001,82 120 1002,75
Om de lineaire uitzettingscoëfficiënt van aluminium te bepalen, meet een fysicus de lengte van een aluminium staaf bij 4 verschillende temperaturen. Het resultaat staat hiernaast.
De gemeten lengte is natuurlijk niet exact gelijk aan de "werkelijke" (verwachte) lengte; er zit nog een meetfout in en eventueel andere storingen. De verwachte lengte hangt lineair samen met de temperatuur , daarom kunnen we voor de gemeten lengte schrijven:
- ,

waarin de meetfout en de overige storingen zijn samengevat in . De parameter is de lengte bij 0 graden; de parameter staat in directe relatie met de gezochte uitzettingscoëfficiënt. Op basis van de boven gegeven steekproefuitkomst kunnen schattingen en van deze parameters berekend worden. Als we daartoe de methode der kleinste kwadraten gebruiken, zijn deze schattingen gebaseerd op de volgende grootheden:


- en .


Deze werden vroeger, bij "handmatige" berekening bepaald, door de tabel met de meetdata met geschikte kolommen uit te breiden en de kolomtotalen te berekenen:
waarneming
nr.1 20 1000,02 400 20000,4 2 60 1000,96 3600 60057,6 3 100 1001,82 10000 100182,0 4 120 1002,75 14400 120330,0 totaal 300 4005,55 28400 300570,0


Als kleinste-kwadratenschatting voor de gezochte parameter vinden we:
- (mm/K).

Variantieanalyse
Vanwege de overeenkomstige analysemethodiek is het mogelijk een variantie-analyse op te vatten als een regressie-analyse. Als voorbeeld nemen we het ANOVA-model met één factor.
- ,

waarin de onderling onafhankelijk zijn en alle N(0,1)-verdeeld. Dit model wordt ook vaak op equivalente wijze geschreven als:

- ,

met als extra voorwaarde:
- .

Door invoeren van zgn. dummy-variabelen kunnen we het model ook schrijven als:


waarin het de vorm heeft van een regressiemodel zonder intercept.
Gesegmenteerde regressie
In sommige gevallen lijkt het verband tussen de variabelen stuksgewijs lineair, als een op een of meer plaatsen gebroken rechte. Het bereik van de verklarende variabele wordt dan verdeeld in segmenten, waarna een lineaire regressie per segment wordt uitgevoerd. De opdeling in segmenten kan daarbij ook onderdeel zijn van de statistische analyse.