Uncertainty quantification
Uncertainty quantification (UQ) is the science of quantitative characterization and reduction of uncertainties in both computational and real world applications. It tries to determine how likely certain outcomes are if some aspects of the system are not exactly known. An example would be to predict the acceleration of a human body in a head-on crash with another car: even if we exactly knew the speed, small differences in the manufacturing of individual cars, how tightly every bolt has been tightened, etc., will lead to different results that can only be predicted in a statistical sense.
Many problems in the natural sciences and engineering are also rife with sources of uncertainty. Computer experiments on computer simulations are the most common approach to study problems in uncertainty quantification.[1][2][3]
Sources of uncertainty
Uncertainty can enter mathematical models and experimental measurements in various contexts. One way to categorize the sources of uncertainty is to consider:[4]
- Parameter uncertainty
- This comes from the model parameters that are inputs to the computer model (mathematical model) but whose exact values are unknown to experimentalists and cannot be controlled in physical experiments, or whose values cannot be exactly inferred by statistical methods. Some examples of this are the local free-fall acceleration in a falling object experiment, various material properties in a finite element analysis for engineering, and multiplier uncertainty in the context of macroeconomic policy optimization.
- Parametric variability
- This comes from the variability of input variables of the model. For example, the dimensions of a work piece in a process of manufacture may not be exactly as designed and instructed, which would cause variability in its performance.
- Structural uncertainty
- Also known as model inadequacy, model bias, or model discrepancy, this comes from the lack of knowledge of the underlying physics in the problem. It depends on how accurately a mathematical model describes the true system for a real-life situation, considering the fact that models are almost always only approximations to reality. One example is when modeling the process of a falling object using the free-fall model; the model itself is inaccurate since there always exists air friction. In this case, even if there is no unknown parameter in the model, a discrepancy is still expected between the model and true physics.
- Algorithmic uncertainty
- Also known as numerical uncertainty, or discrete uncertainty. This type comes from numerical errors and numerical approximations per implementation of the computer model. Most models are too complicated to solve exactly. For example, the finite element method or finite difference method may be used to approximate the solution of a partial differential equation (which introduces numerical errors). Other examples are numerical integration and infinite sum truncation that are necessary approximations in numerical implementation.
- Experimental uncertainty
- Also known as observation error, this comes from the variability of experimental measurements. The experimental uncertainty is inevitable and can be noticed by repeating a measurement for many times using exactly the same settings for all inputs/variables.
- Interpolation uncertainty
- This comes from a lack of available data collected from computer model simulations and/or experimental measurements. For other input settings that don't have simulation data or experimental measurements, one must interpolate or extrapolate in order to predict the corresponding responses.
Aleatoric and epistemic uncertainty
Uncertainty is sometimes classified into two categories,[5][6] prominently seen in medical applications.[7]
- Aleatoric uncertainty
- Aleatoric uncertainty is also known as statistical uncertainty, and is representative of unknowns that differ each time we run the same experiment. For example, a single arrow shot with a mechanical bow that exactly duplicates each launch (the same acceleration, altitude, direction and final velocity) will not all impact the same point on the target due to random and complicated vibrations of the arrow shaft, the knowledge of which cannot be determined sufficiently to eliminate the resulting scatter of impact points. The argument here is obviously in the definition of "cannot". Just because we cannot measure sufficiently with our currently available measurement devices does not preclude necessarily the existence of such information, which would move this uncertainty into the below category. Aleatoric is derived from the Latin alea or dice, referring to a game of chance.
- Epistemic uncertainty
- Epistemic uncertainty is also known as systematic uncertainty, and is due to things one could in principle know but do not in practice. This may be because a measurement is not accurate, because the model neglects certain effects, or because particular data has been deliberately hidden. An example of a source of this uncertainty would be the drag in an experiment designed to measure the acceleration of gravity near the earth's surface. The commonly used gravitational acceleration of 9.8 m/s^2 ignores the effects of air resistance, but the air resistance for the object could be measured and incorporated into the experiment to reduce the resulting uncertainty in the calculation of the gravitational acceleration.
In real life applications, both kinds of uncertainties are present. Uncertainty quantification intends to work toward reducing epistemic uncertainties to aleatoric uncertainties. The quantification for the aleatoric uncertainties can be relatively straightforward to perform, depending on the application. Techniques such as the Monte Carlo method are frequently used. A probability distribution can be represented by its moments (in the Gaussian case, the mean and covariance suffice, although, in general, even knowledge of all moments to arbitrarily high order still does not specify the distribution function uniquely), or more recently, by techniques such as Karhunen–Loève and polynomial chaos expansions. To evaluate epistemic uncertainties, the efforts are made to gain better knowledge of the system, process or mechanism. Methods such as probability bounds analysis, fuzzy logic or evidence theory (Dempster–Shafer theory – a generalization of the Bayesian theory of subjective probability) are used.
Two types of uncertainty quantification problems
There are two major types of problems in uncertainty quantification: one is the forward propagation of uncertainty (where the various sources of uncertainty are propagated through the model to predict the overall uncertainty in the system response) and the other is the inverse assessment of model uncertainty and parameter uncertainty (where the model parameters are calibrated simultaneously using test data). There has been a proliferation of research on the former problem and a majority of uncertainty analysis techniques were developed for it. On the other hand, the latter problem is drawing increasing attention in the engineering design community, since uncertainty quantification of a model and the subsequent predictions of the true system response(s) are of great interest in designing robust systems.
Forward uncertainty propagation
Uncertainty propagation is the quantification of uncertainties in system output(s) propagated from uncertain inputs. It focuses on the influence on the outputs from the parametric variability listed in the sources of uncertainty. The targets of uncertainty propagation analysis can be:
- To evaluate low-order moments of the outputs, i.e. mean and variance.
- To evaluate the reliability of the outputs. This is especially useful in reliability engineering where outputs of a system are usually closely related to the performance of the system.
- To assess the complete probability distribution of the outputs. This is useful in the scenario of utility optimization where the complete distribution is used to calculate the utility.
Inverse uncertainty quantification
Given some experimental measurements of a system and some computer simulation results from its mathematical model, inverse uncertainty quantification estimates the discrepancy between the experiment and the mathematical model (which is called bias correction), and estimates the values of unknown parameters in the model if there are any (which is called parameter calibration or simply calibration). Generally this is a much more difficult problem than forward uncertainty propagation; however it is of great importance since it is typically implemented in a model updating process. There are several scenarios in inverse uncertainty quantification:
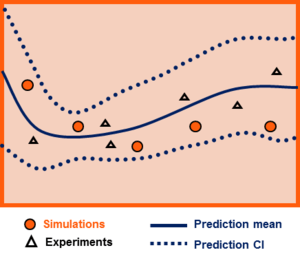
Bias correction only
Bias correction quantifies the model inadequacy, i.e. the discrepancy between the experiment and the mathematical model. The general model updating formula for bias correction is:

where denotes the experimental measurements as a function of several input variables , denotes the computer model (mathematical model) response, denotes the additive discrepancy function (aka bias function), and denotes the experimental uncertainty. The objective is to estimate the discrepancy function , and as a by-product, the resulting updated model is . A prediction confidence interval is provided with the updated model as the quantification of the uncertainty.






Parameter calibration only
Parameter calibration estimates the values of one or more unknown parameters in a mathematical model. The general model updating formulation for calibration is:

where denotes the computer model response that depends on several unknown model parameters , and denotes the true values of the unknown parameters in the course of experiments. The objective is to either estimate , or to come up with a probability distribution of that encompasses the best knowledge of the true parameter values.



Bias correction and parameter calibration
It considers an inaccurate model with one or more unknown parameters, and its model updating formulation combines the two together:

It is the most comprehensive model updating formulation that includes all possible sources of uncertainty, and it requires the most effort to solve.
Selective methodologies for uncertainty quantification
Much research has been done to solve uncertainty quantification problems, though a majority of them deal with uncertainty propagation. During the past one to two decades, a number of approaches for inverse uncertainty quantification problems have also been developed and have proved to be useful for most small- to medium-scale problems.
Methodologies for forward uncertainty propagation
Existing uncertainty propagation approaches include probabilistic approaches and non-probabilistic approaches. There are basically five categories of probabilistic approaches for uncertainty propagation:[8]
- Simulation-based methods: Monte Carlo simulations, importance sampling, adaptive sampling, etc.
- Local expansion-based methods: Taylor series, perturbation method, etc. These methods have advantages when dealing with relatively small input variability and outputs that don't express high nonlinearity. These linear or linearized methods are detailed in the article Uncertainty propagation.
- Functional expansion-based methods: Neumann expansion, orthogonal or Karhunen–Loeve expansions (KLE), with polynomial chaos expansion (PCE) and wavelet expansions as special cases.
- Most probable point (MPP)-based methods: first-order reliability method (FORM) and second-order reliability method (SORM).
- Numerical integration-based methods: Full factorial numerical integration (FFNI) and dimension reduction (DR).
For non-probabilistic approaches, interval analysis,[9] Fuzzy theory, possibility theory and evidence theory are among the most widely used.
The probabilistic approach is considered as the most rigorous approach to uncertainty analysis in engineering design due to its consistency with the theory of decision analysis. Its cornerstone is the calculation of probability density functions for sampling statistics.[10] This can be performed rigorously for random variables that are obtainable as transformations of Gaussian variables, leading to exact confidence intervals.
Methodologies for inverse uncertainty quantification
Frequentist
In regression analysis and least squares problems, the standard error of parameter estimates is readily available, which can be expanded into a confidence interval.
Bayesian
Several methodologies for inverse uncertainty quantification exist under the Bayesian framework. The most complicated direction is to aim at solving problems with both bias correction and parameter calibration. The challenges of such problems include not only the influences from model inadequacy and parameter uncertainty, but also the lack of data from both computer simulations and experiments. A common situation is that the input settings are not the same over experiments and simulations.
Modular Bayesian approach
An approach to inverse uncertainty quantification is the modular Bayesian approach.[4][11] The modular Bayesian approach derives its name from its four-module procedure. Apart from the current available data, a prior distribution of unknown parameters should be assigned.
- Module 1: Gaussian process modeling for the computer model
To address the issue from lack of simulation results, the computer model is replaced with a Gaussian process (GP) model

where

is the dimension of input variables, and is the dimension of unknown parameters. While is pre-defined, , known as hyperparameters of the GP model, need to be estimated via maximum likelihood estimation (MLE). This module can be considered as a generalized kriging method.




- Module 2: Gaussian process modeling for the discrepancy function
Similarly with the first module, the discrepancy function is replaced with a GP model

where

Together with the prior distribution of unknown parameters, and data from both computer models and experiments, one can derive the maximum likelihood estimates for . At the same time, from Module 1 gets updated as well.


- Module 3: Posterior distribution of unknown parameters
Bayes' theorem is applied to calculate the posterior distribution of the unknown parameters:

where includes all the fixed hyperparameters in previous modules.

- Module 4: Prediction of the experimental response and discrepancy function
Fully Bayesian approach
Fully Bayesian approach requires that not only the priors for unknown parameters but also the priors for the other hyperparameters should be assigned. It follows the following steps:[12]
- Derive the posterior distribution ;
- Integrate out and obtain . This single step accomplishes the calibration;
- Prediction of the experimental response and discrepancy function.


However, the approach has significant drawbacks:
- For most cases, is a highly intractable function of . Hence the integration becomes very troublesome. Moreover, if priors for the other hyperparameters are not carefully chosen, the complexity in numerical integration increases even more.
- In the prediction stage, the prediction (which should at least include the expected value of system responses) also requires numerical integration. Markov chain Monte Carlo (MCMC) is often used for integration; however it is computationally expensive.
The fully Bayesian approach requires a huge amount of calculations and may not yet be practical for dealing with the most complicated modelling situations.[12]
Known issues
The theories and methodologies for uncertainty propagation are much better established, compared with inverse uncertainty quantification. For the latter, several difficulties remain unsolved:
- Dimensionality issue: The computational cost increases dramatically with the dimensionality of the problem, i.e. the number of input variables and/or the number of unknown parameters.
- Identifiability issue:[13] Multiple combinations of unknown parameters and discrepancy function can yield the same experimental prediction. Hence different values of parameters cannot be distinguished/identified.
References
- Sacks, Jerome; Welch, William J.; Mitchell, Toby J.; Wynn, Henry P. (1989). "Design and Analysis of Computer Experiments". Statistical Science. 4 (4): 409–423. doi:10.1214/ss/1177012413. JSTOR 2245858.
- Ronald L. Iman, Jon C. Helton, "An Investigation of Uncertainty and Sensitivity Analysis Techniques for Computer Models", Risk Analysis, Volume 8, Issue 1, pages 71–90, March 1988, doi:10.1111/j.1539-6924.1988.tb01155.x
- W.E. Walker, P. Harremoës, J. Rotmans, J.P. van der Sluijs, M.B.A. van Asselt, P. Janssen and M.P. Krayer von Krauss, "Defining Uncertainty: A Conceptual Basis for Uncertainty Management in Model-Based Decision Support", Integrated Assessment, Volume 4, Issue 1, 2003, doi:10.1076/iaij.4.1.5.16466
- Kennedy, Marc C.; O'Hagan, Anthony (2001). "Bayesian calibration of computer models". Journal of the Royal Statistical Society: Series B (Statistical Methodology). 63 (3): 425–464. doi:10.1111/1467-9868.00294.
- Der Kiureghian, Armen; Ditlevsen, Ove (2009). "Aleatory or epistemic? Does it matter?". Structural Safety. 31 (2): 105–112. doi:10.1016/j.strusafe.2008.06.020.
- Matthies, Hermann G. (2007). "Quantifying Uncertainty: Modern Computational Representation of Probability and Applications". Extreme Man-Made and Natural Hazards in Dynamics of Structures. NATO Security through Science Series. pp. 105–135. doi:10.1007/978-1-4020-5656-7_4. ISBN 978-1-4020-5654-3.
- Abhaya Indrayan, Medical Biostatistics, Second Edition, Chapman & Hall/CRC Press, 2008, pages 8, 673
- S. H. Lee and W. Chen, "A comparative study of uncertainty propagation methods for black-box-type problems", Structural and Multidisciplinary Optimization Volume 37, Number 3 (2009), 239–253, doi:10.1007/s00158-008-0234-7
- Jaulin, L.; Kieffer, M.; Didrit, O.; Walter, E. (2001). Applied Interval Analysis. Springer. ISBN 1-85233-219-0.
- Arnaut, L. R. Measurement uncertainty in reverberation chambers - I. Sample statistics. Technical report TQE 2, 2nd. ed., sec. 3.1, National Physical Laboratory, 2008.
- Marc C. Kennedy, Anthony O'Hagan, Supplementary Details on Bayesian Calibration of Computer Models, Sheffield, University of Sheffield: 1–13, 2000
- F. Liu, M. J. Bayarri and J.O.Berger, "Modularization in Bayesian Analysis, with Emphasis on Analysis of Computer Models", Bayesian Analysis (2009) 4, Number 1, pp. 119–150, doi:10.1214/09-BA404
- Paul D. Arendt, Daniel W. Apley, Wei Chen, David Lamb and David Gorsich , "Improving Identifiability in Model Calibration Using Multiple Responses", Journal of Mechanical Design, 134(10), 100909 (2012); doi:10.1115/1.4007573