Tatoeba
 | |
Type of site | Open collaborative multilingual "sentence dictionary" |
|---|---|
| Available in | 25 languages of the interface; content in 301 languages (May 2016) |
| Owner | Trang Ho, Allan Simon |
| Created by | Trang Ho, Allan Simon |
| Website | https://tatoeba.org/ |
| Commercial | No |
| Registration | Optional |
| Launched | 2006 |
| Current status | Online; beta |
Content license | Creative Commons Attribution 2.0 |
Tatoeba.org is a free collaborative online database of example sentences geared towards foreign language learners. Its name comes from the Japanese term "tatoeba" (例えば tatoeba), meaning "for example". Unlike other online dictionaries, which focus on words, Tatoeba focuses on translation of complete sentences. In addition, the structure of the database and interface emphasize one-to-many relationships. Not only can a sentence have multiple translations within a single language, but its translations into all languages are readily visible, as are indirect translations that involve a chain of stepwise links from one language to another.
The aim of the project
The aim of the Tatoeba Project is to create a database of sentences and translations that can be used by anyone developing a language learning application. The idea is that the project creates the data, so programmers can just focus on coding the application.
The data collected by the project is freely available under a Creative Commons Attribution (CC-BY) license.
Content
As of November 2017, the Tatoeba Corpus has over 6,000,000 sentences in 319 languages. The top 21 languages make up 90% of the corpus. Eighty-five of these languages have over 1,000 sentences. The top 13 languages have over 100,000 sentences each. The interface is available in 25 different languages.
Tatoeba.org is also the current home of the Tanaka Corpus, a public-domain series of about 150,000 English-Japanese sentence pairs compiled by Hyogo University professor Yasuhito Tanaka first released in 2001, and where it is undergoing its latest revisions.[1][2]
History
Tatoeba was founded by Trang Ho in 2006. She originally hosted the project on Sourceforge under the project name "multilangdict".[3]
Interface
Users, even those who are not registered, can search for words in any language to retrieve sentences that use them. Each sentence in the Tatoeba database is displayed next to its translations in other languages; direct and indirect translations are differentiated. Sentences are tagged for content such as subject matter, dialect, or vulgarity; they also each have individual comment threads to facilitate feedback and corrections from other users and cultural notes. As of early 2016, more than 200,000 sentences in 19 languages had audio readings. Sentences can also be browsed by language, tag, or audio.
Registered users can add new sentences or translate or proofread existing ones, even if their target language is not their native tongue. However, it is preferred that users translate into their native or "strongest" language and add sentences from their native language rather than translating into or adding from their target language.[4] Translations are linked to the original sentence automatically. Users can freely edit their own sentences, "adopt" and correct sentences without an owner, and comment on others' sentences. Advanced contributors, a rank above ordinary contributors, can tag, link, and unlink sentences. Corpus maintainers, a rank above advanced contributors, can untag and delete sentences. They can also modify owned sentences, though they typically do so only if the owner fails to respond to a request to make the change.
Database structure
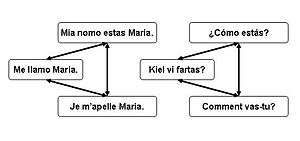
Tatoeba's basic data structure is a series of nodes and links. Each sentence is a node; each link bridges two sentences with the same meaning.[5]
License
The entire Tatoeba database is published under a Creative Commons Attribution 2.0 license,[6] freeing it for academic and other use.
Grants
Tatoeba received a grant from Mozilla Drumbeat in December 2010.[7][8]
Some work on the Tatoeba infrastructure was sponsored by Google Summer of Code, 2014 edition.[9]
Usage
Parallel text corpora such as Tatoeba are used for a variety of natural language processing tasks such as machine translation. The Tatoeba data has been used as data for treebanking Japanese[10] and statistical machine translation,[11] as well as the WWWJDIC Japanese-English dictionary and the Bilingual Sentence Pairs and Japanese Reading and Translation Practice on www.ManyThings.org.
Offline edition
Selected content from Tatoeba – 83,932 phrases in Esperanto along with all their translations into other languages – has appeared in the third edition of the multilingual DVD Esperanto Elektronike ("Electronic Esperanto") published in 6,000 copies by E@I in July 2011.
Tab-delimited data ready for import into Anki and similar software can be downloaded from http://www.manythings.org/anki/
See also
References
- ↑ "Tanaka Corpus". EDRDG Wiki. Electronic Dictionary Research and Development Group. 3 February 2011. Retrieved 20 March 2011.
- ↑ Breen, Jim (2 March 2011). "WWWJDIC – Information". WWWJDIC. Monash University. Retrieved 20 March 2011.
- ↑ "Trang's dictionary project". sourceforge.net.
- ↑ http://en.wiki.tatoeba.org/articles/show/quick-start
- ↑ Ho, Trang (23 February 2010). "How to be a good contributor in Tatoeba". Tatoeba Project Blog. Retrieved 20 March 2011.
- ↑ "Terms of use". Tatoeba.org. Retrieved 20 March 2011.
- ↑ Ho, Trang (17 January 2011). "Grant from Mozilla Drumbeat". Tatoeba Project Blog. Retrieved 20 March 2011.
- ↑ Moltke, Henrik (30 December 2010). "Best Drumbeat Projects: Tatoeba – a free and open database of sentences". Yoyodyne.cc. Archived from the original on 2 January 2011. Retrieved 20 March 2011.
...the Mozilla Foundation wants to encourage and help the Tatoeba project by giving it a USD 2.5K Mozilla Drumbeat Grant.
- ↑ https://www.google-melange.com/gsoc/org2/google/gsoc2014/tatoeba
- ↑ Francis Bond, 栗林 孝行 [Takayuki Kuribayashi], 橋本 力 [Hashimoto Chikara] (2008) HPSGに基づくフリーな日本語ツリー バンクの構築 [A free Japanese Treebank based on HPSG]. In 14th Annual Meeting of The Association for Natural Language Processing, Tokyo.
- ↑ Eric Nichols, Francis Bond, Darren Scott Appling and Yuji Matsumoto (2010) Paraphrasing Training Data for Statistical Machine Translation. Journal of Natural Language Processing, 17(3), pages 101–122.