FAM214A
| FAM214A | |||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Identifiers | |||||||||||||||||||||||||
| Aliases | FAM214A, KIAA1370, family with sequence similarity 214 member A | ||||||||||||||||||||||||
| External IDs | MGI: 2387648 HomoloGene: 35065 GeneCards: FAM214A | ||||||||||||||||||||||||
| |||||||||||||||||||||||||
| |||||||||||||||||||||||||
| Orthologs | |||||||||||||||||||||||||
| Species | Human | Mouse | |||||||||||||||||||||||
| Entrez | |||||||||||||||||||||||||
| Ensembl | |||||||||||||||||||||||||
| UniProt | |||||||||||||||||||||||||
| RefSeq (mRNA) | |||||||||||||||||||||||||
| RefSeq (protein) | |||||||||||||||||||||||||
| Location (UCSC) | Chr 15: 52.58 – 52.71 Mb | Chr 9: 74.95 – 75.03 Mb | |||||||||||||||||||||||
| PubMed search | [3] | [4] | |||||||||||||||||||||||
| Wikidata | |||||||||||||||||||||||||
| |||||||||||||||||||||||||



Protein FAM214A, also known as protein family with sequence similarity 214, A (FAM214A) is a protein that, in humans, is encoded by the FAM214A gene. FAM214A is a gene with unknown function found at the q21.2-q21.3 locus on Chromosome 15 (human).[5] The protein product of this gene has two conserved domains, one of unknown function (DUF4210) and another one called Chromosome_Seg.[6] Although the function of the FAM214A protein is uncharacterized, both DUF4210 and Chromosome_Seg have been predicted to play a role in chromosome segregation during meiosis.[7]
Gene
Overview
The FAM214A gene is located on the negative DNA strand (see Sense (molecular biology)) of chromosome 15 between position 52,873,514 and 53,002,014; thus making the gene 97,303 base pairs (bp) long.[5][8][9] FAM214A has been previously labeled with two other aliases, known as KIAA1370 and FLJ10980.[5] The FAM214A gene is predicted to contain 12 exons which comprise the final 4231 bp mRNA transcript after transcription has occurred.[10] It is this mRNA product that is then translated into the final FAM214A protein with the help of the promoter sequence and transcription factors. The promoter for the FAM214A mRNA sequence was predicted and analyzed by the El Dorado program on Genomatix.[11] This promoter is 601 base pairs long and spans a portion of the 5' UTR.[11]

Gene expression

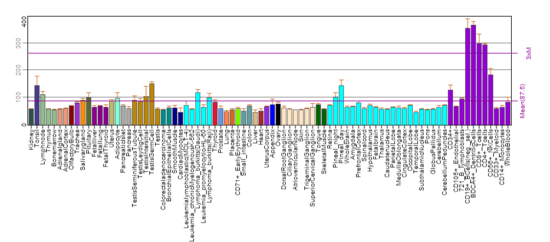
FAM214A is considered to be ubiquitously expressed (or very nearly so) in low levels according to a number of sources such as BioGPS and the Expression Atlas.[12][13][14] As can be seen in the BioGPS image below, there is a significantly higher expression level in immune-related cells and tissues, thus suggesting an immune role; however, there has been no specific in situ evidence to support this claim. Expression data has been collected from a number of studies performed on a large range of genes, therefore, some of the data is contradictory in nature.
Protein
Overview
The function of the FAM214A protein in humans is still unknown; however, there are three functional term associations including "biological process," "cellular component," and molecular function," that describe the function of this protein on The Gene Ontology which predict implications of its primary function in vivo.[15][16] The protein product of FAM214A consists of 1076 amino acids (aa), has been predicted to have a molecular mass of 121,700 Daltons, and has an isoelectric point around pH 7.7.[6][17][18] This protein is predicted to remain in the nucleus after transcription based upon its lack of signal peptide sequence and the predictions of the program PSORTII.[19] Due to alternative splicing, two other isoforms (Q32MH5-2 and Q32MH5-3) have been observed. They differ slightly from the primary product.[20] Isoform 2 has four different amino acids from bases 960-960 and is missing the end of the sequence from bases 964-1076.[20] Isoform 3 has seven extra amino acids added to the beginning of the sequence after the methionine.[20]
After being translated, the FAM214A protein is predicted to remain in the nucleus by more than one type of subprogram on PSORT II.[19] This protein has a pat4 signal, one of the two "classical" nuclear localization signals (NLSs), starting at residue 709.[21] Although it does not have the second "classical" NLS, pat7, nor the "non-classical" bipartite NLS it is still predicted to be targeted for the nucleus by the NCNN score.[21][22] This score predicts whether the protein is targeted for the nucleus or the cytoplasm based upon the amino acid sequence.[21][22] For the FAM214A protein, the NCNN score predicted nuclear localization with 94.1% certainty.[21][22] Based upon this information, PSORT generates an overall prediction of the protein's subcellular localization. For FAM214A, the predicted values were 69.6% for the nucleus as compared to 13.0% for the mitochondria, 8.7% for the cytoplasm, and 4.3% for the secretory vesicles and endoplasmic reticulum.[19]
Post-translational modifications
This protein most likely does not undergo a significant number of post-translational modifications due to the lack of signal peptide sequence predicted by NetNGlyc and NetOGlyc on the ExPASy web server.[24][25] This is because much of the intracellular machinery performing post-translational modifications requires the protein to move through organelles such as the endoplasmic reticulum and Golgi apparatus. Without a signal peptide sequence, the protein generally does not leave the nucleus, which was predicted by PSORT II as described above.[19]
A SAPS analysis of this protein was performed against the swp23s.q database, which indicated the presence of an abnormally large number of serine amino acids and an abnormally small number of alanine amino acids in this protein.[17] According to a review article by Fayard et al., phosphoinositide-dependent kinase 2 (PDK2) is a serine/threonine kinase that is important for regulating cell cycle. Because the FAM214A protein has a larger number of serine groups than is considered normal, there is the possibility that PDK2 has an important effect on this protein.[26] In order to determine whether the excessive number of serines were actually predicted to be phosphorylated, the protein sequence was run through the program NetPhos from the ExPASy webserver.[23] This program predicted the phosphorylation of 69 serines, 14 threonines, and 9 tyrosines.[23] According to the SAPS analysis from above, there are a total or 134 serines, thus indicating that approximately half are predicted to be phosphorylated in vivo. A diagram of the phosphorylation predictions is shown to the right.
One other type of post-translational modification was predicted for the FAM214A protein by the program NetCorona on ExPASy.[27] The program predicted a single cleavage site between position 214 and 215 in the FAM214A protein sequence after translation.[27]
Protein interactions
There are number of transcription factor binding sites predicted for the FAM214A promoter sequence.[11] A few of the ones with the highest predicted confidence are provided in the table below.[11]
Possible Transcription Factors Predicted to Bind to the FAM214A Promoter Sequence
| Predicted Transcription Factor | Start | End | Strand | Confidence |
| Transcription factor II B (TFIIB) recognition element | 97 | 103 | Negative | 1.0 |
| Myeloid zinc finger protein MZF1 | 151 | 161 | Negative | 1.0 |
| Myelin transcription factor 1-like, neuronal C2HC zinc finger factor 1 | 388 | 400 | Negative | 0.945 |
| Androgene receptor binding site, IR3 sites | 495 | 513 | Negative | 0.923 |
| Wilms Tumor Suppressor | 1 | 17 | Positive | 0.968 |
| Non-palindromic nuclear factor I binding sites | 27 | 47 | Positive | 0.988 |
| Alternative splicing variant of FOXP1, activated in ESCs | 383 | 383 | Positive | 1.0 |
| Pleomorphic adenoma gene 1 | 488 | 510 | Positive | 1.0 |
| ETS-like gene 1 (ELK-1) | 569 | 589 | Positive | 0.961 |
The only protein predicted according STRING to interact with the FAM214A protein is called MFSD6L. This protein belongs to the major facilitator superfamily is predicted to be a transmembrane protein. Like FAM214A, the function of this protein has not yet been characterized through experimentation or research.[28][29] Because this MFSD6L protein is the only FAM214A protein interaction predicted with any certainty, the sequence for it was run through the PSORT II program. The data from the NLS subprogram predicted the presence of a single pat4 and two pat7 NLS sequences, thus indicating possible nuclear localization.[19][21] The NCNN score, on the other hand, predicted cytoplasmic localiztion with 94.1% certainty, thus leaving the overall PSORT II score at 39.1% plasma membrane, 39.1% endoplasmic reticulum, 4.3% vacuolar, 4.3% vesicles of secretory system, 4.3% Golgi, 4.3% mitochondrial, and 4.3% nuclear.[21][22] This is contradictory as there are three total nuclear localization signals, but this may be due to the fact that the significant transmembrane nature of the MFSD6L protein may be causing issues with these predictions.[21]
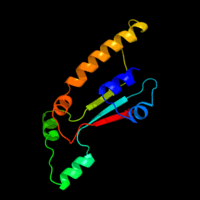
Secondary and tertiary structure
The secondary structure of the FAM214A protein consists of a number of alpha helices and beta sheets as predicted by Biology Workbench and Protein Homology/analogY Recognition Engine (PHYRE).[30][31] The PHYRE program predicts that 66 percent of the FAM214A secondary structure is disordered and therefore unable to be analyzed and converted into a tertiary structure prediction.[30] It was; however, able to predict approximately 10 percent of the protein's structure with 95 percent significance.[30] The diagram for this is shown to the left.[30]
Conservation
Paralog
A single paralogous gene has been found on chromosome 9 in Homo sapiens and is named FAM214B (family with sequence similarity, B).[32] FAM214B, although considered a paralog, has a significantly different protein sequence from that of FAM214A. When the two were compared against each other on NCBI’s BLAST, the only significant similarity observed was within the last 200 amino acids (where the DUF4210 and Chromosome_Seg domains are located).[33] Although the similarity between FAM214A and B is low, these two proteins are in the same protein family and contain the same two conserved domains.[7][34]
Orthologs
The FAM214A protein has a significant number of orthologs across a large number of taxonomic groups including Mammalia, Aves, Reptilia, Amphibia, Actinopterygii, Echinoidea, Insecta, Trematoda, Crustacea, Tricoplacia, Anthozoa, and Eurotiomycetes.[35] This indicates that the FAM214A protein is well conserved within Eukaryotes but does not appear to be conserved in Bacteria or Archaea. In all orthologs, the most-conserved region was near the end of the protein where the conserved domains are (see below). Orthologs for the human FAM214A protein were found as far back as Tuber melanosporum, Talaromyces stipitatus, and Aspergillus nidulans, which all diverged approximately 1215 million years ago.
Orthologs for the FAM214A Protein
| Genus Species | Common name | Divergence from human liineage (MYA) [36] | NCBI protein accession number | Sequence length | Percent identity to human sequence [33] | Common gene name |
| Homo sapiens | Human | - | NP_062546.2 | 1076 | 100 | FAM214A |
| Pan troglodytes | Common Chimpanzee | 6.3 | XP_003314724 | 1083 | 99 | FAM214A |
| Pan paniscus | Bonobo | 6.3 | XP_003827895.1 | 1076 | 100 | FAM214A |
| Rattus norvegicus | Rat | 92.3 | NP_001100308 | 1074 | 100 | LOC300836 |
| Bos taurus | Cow | 94.2 | XP_601152 | 1087 | 100 | KIAA1370 |
| Canus lupus familiaris | Dog | 94.2 | XP_544682 | 1081 | 100 | KIAA1370 |
| Ornithorhynchus anatinus | Platypus | 167.4 | XP_001515207 | 1169 | 95 | KIAA1370 |
| Gallus gallus | Chicken | 296.0 | NP_001005811 | 1093 | 99 | FAM214A |
| Taeniopygia guttata | Zebra Finch | 296.0 | XP_002196177 | 1112 | 99 | FAM214A |
| Anolis carolinensis | Carolina Anole | 296.0 | XP_003227400 | 1086 | 99 | KIAA1370 |
| Xenopus tropicalis | Tropical Clawed Frog | 371.2 | NP_001015702 | 946 | 98 | FAM214A |
| Danio rerio | Zebrafish | 400.1 | NP_001189349 | 1021 | 75 | FAM214A |
| Apis mellifera | Honey Bee | 782.7 | XP_393903 | 1339 | 45 | LOC410423 |
| Strongylocentrotus purpuratus | Sea Urchin | 742.9 | XP_799179 | 297 | 27 | FAM214A-like |
| Drosophila melanogaster | Fruit Fly | 782.7 | NP_610688 | 1297 | 27 | CG9005 |
| Schistosoma mansoni | Schistosome Parasite | 792.4 | XP_002579285 | 766 | 26 | Hypothetical Protein |
| Daphnia pulex | Common Water Flea | 782.7 | EFX87516 | 200 | 18 | Hypothetical Protein DAPPUDRAFT_207300 |
| Nematostella vectensis | Sea Anemone | 855.3 mya | XP_001633540 | 191 | 18 | Hypothetical Protein |
| Tuber melanosporum | Truffle | 1215.8 | XP_002841833 | 622 | 15 | Hypothetical Protein |
| Talaromyces stipitatus | - | 1215.8 | XP_002478567 | 797 | 25 | Conserved Hypothetical Protein |
| Aspergillus nidulans | Filamentous Fungus | 1215.8 | XP_658605 | 728 | 15 | hypothetical protein AN1001.2 |
Phylogeny
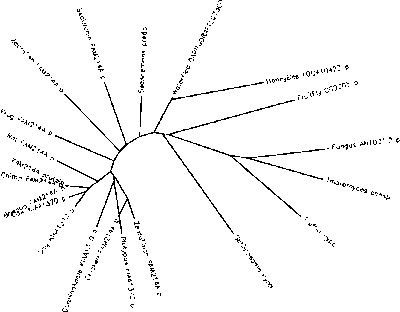
An unrooted phylogenetic tree of 20 orthologs was generated by the CLUSTALW program on Biology Workbench to demonstrate the evolutionary relationship between FAM214A and its orthologs.[31]
Conserved domains
Within the FAM214A protein, there are three well-conserved regions. These include a well-conserved region near the n-terminus of the protein and two conserved domains including the Domain of Unknown Function 4210 (DUF4210) and a Chromosome_Seg domain near the c-terminus.[7] A schematic diagram of these three regions is shown below. The well-conserved region near the n-terminus of the protein is not predicted to contain any known domains or motifs; however, the cleavage site predicted by NetCorona above is located within this region and it is well-conserved in a majority of the proteins orthologous to FAM214A.[27] The two conserved domains located at the end of this protein are the most important portion of the peptide based upon evolutionary history. All organisms in the Ortholog table above except the platypus (which is missing the Chromosome_Seg domain) contain both of these conserved domains within their protein sequence.[7]
References
- 1 2 3 GRCh38: Ensembl release 89: ENSG00000047346 - Ensembl, May 2017
- 1 2 3 GRCm38: Ensembl release 89: ENSMUSG00000034858 - Ensembl, May 2017
- ↑ "Human PubMed Reference:".
- ↑ "Mouse PubMed Reference:".
- 1 2 3 4 "Gene Cards: FAM214A family with sequence similarity 214, A".
- 1 2 "Protein FAM214A". NCBI. Retrieved 2 Feb 2013.
- 1 2 3 4 "NCBI Conserved Domains".
- ↑ "Gene Loc Map Region around Gene FAM214a". Gene Cards.
- 1 2 "FAM214A family with sequence similarity 214, A". NCBI.
- ↑ "Homo sapiens family with sequence similarity 214, member A (FAM214A), mRNA". NCBI.
- 1 2 3 4 "Genomatix: El Dorado". Genomatix.
- 1 2 "FAM214A Gene Expression from Gene Cards". Gene Cards.
- 1 2 "FAM214A Gene Expression from BioGPS". BioGPS.
- ↑ "FAM214A Gene Expression From Expression Atlas".
- ↑ "The Gene Ontology".
- ↑ "The Gene Ontology: Term Associations".
- 1 2 "Biology Workbench: SAPS".
- ↑ Kozlowski, LP (2016). "IPC - Isoelectric Point Calculator". Biology direct. 11 (1): 55. doi:10.1186/s13062-016-0159-9. PMC 5075173. PMID 27769290.
- 1 2 3 4 5 "PSORT II Prediction".
- 1 2 3 "Protein FAM214A - Homo sapiens (Human)". UniProt.
- 1 2 3 4 5 6 7 "PSORT II NLS". PSORT.
- 1 2 3 4 Reinhardt A, Hubbard T (May 1998). "Using neural networks for prediction of the subcellular location of proteins". Nucleic Acids Research. 26 (9): 2230–6. doi:10.1093/nar/26.9.2230. PMC 147531. PMID 9547285.
- 1 2 3 "NetPhos". ExPASy.
- ↑ "NetNGlyc". ExPASy.
- ↑ "NetOGlyc". ExPASy.
- ↑ Fayard E, Tintignac LA, Baudry A, Hemmings BA (December 2005). "Protein kinase B/Akt at a glance". Journal of Cell Science. 118 (Pt 24): 5675–8. doi:10.1242/jcs.02724. PMID 16339964.
- 1 2 3 "NetCorona". ExPASy.
- ↑ "Gene Cards MFSD6L". Gene Cards.
- ↑ "UniProt MFSD6L". UniProt.
- 1 2 3 4 5 "PHYRE Protein Fold Recognition Server".
- 1 2 3 "Biology Workbench".
- ↑ "Gene Cards-Paralogs". Gene Cards.
- 1 2 "NCBI BLAST". NCBI.
- ↑ "Conserved Domains FAM214B". NCBI.
- ↑ "Gene Cards Orthologs". Gene Cards.
- ↑ Hedges, SB; Dudley J; Kumar S (2006). "TimeTree: a public knowledge-base of divergence times among organisms". pp. 2971–2972.
r