Arithmetic coding
Arithmetic coding is a form of entropy encoding used in lossless data compression. Normally, a string of characters such as the words "hello there" is represented using a fixed number of bits per character, as in the ASCII code. When a string is converted to arithmetic encoding, frequently used characters will be stored with fewer bits and not-so-frequently occurring characters will be stored with more bits, resulting in fewer bits used in total. Arithmetic coding differs from other forms of entropy encoding, such as Huffman coding, in that rather than separating the input into component symbols and replacing each with a code, arithmetic coding encodes the entire message into a single number, an arbitrary-precision fraction q where 0.0 ≤ q < 1.0. It represents the current information as a range, defined by two numbers. Recent Asymmetric Numeral Systems family of entropy coders allows for faster implementations thanks to directly operating on a single natural number representing the current information.
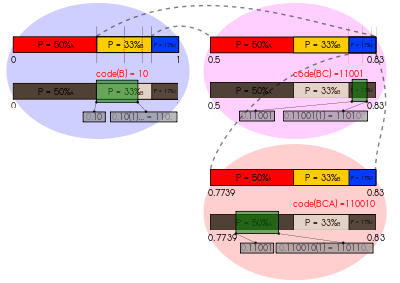
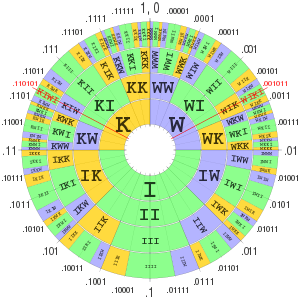
Implementation details and examples
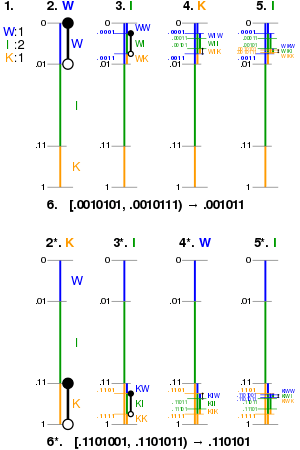
| 1. | The letter frequencies are found. |
|---|---|
| 2. | The interval [0, 1) is partitioned in the ratio of the frequencies. |
| 3–5. | The corresponding interval is iteratively partitioned for each letter in the message. |
| 6. | Any value in the final interval is chosen to represent the message. |
| 2*–6*. | The partitioning and value if the message were "KIWI" instead. |
Equal probabilities
In the simplest case, the probability of each symbol occurring is equal. For example, consider a set of three symbols, A, B, and C, each equally likely to occur. Simple block encoding would require 2 bits per symbol, which is wasteful: one of the bit variations is never used. That is to say, A=00, B=01, and C=10, but 11 is unused.
A more efficient solution is to represent a sequence of these three symbols as a rational number in base 3 where each digit represents a symbol. For example, the sequence "ABBCAB" could become 0.0112013, in arithmetic coding as a value in the interval [0, 1). The next step is to encode this ternary number using a fixed-point binary number of sufficient precision to recover it, such as 0.00101100102 — this is only 10 bits; 2 bits are saved in comparison with naïve block encoding. This is feasible for long sequences because there are efficient, in-place algorithms for converting the base of arbitrarily precise numbers.
To decode the value, knowing the original string had length 6, one can simply convert back to base 3, round to 6 digits, and recover the string.
Defining a model
In general, arithmetic coders can produce near-optimal output for any given set of symbols and probabilities (the optimal value is −log2P bits for each symbol of probability P, see source coding theorem). Compression algorithms that use arithmetic coding start by determining a model of the data – basically a prediction of what patterns will be found in the symbols of the message. The more accurate this prediction is, the closer to optimal the output will be.
Example: a simple, static model for describing the output of a particular monitoring instrument over time might be:
- 60% chance of symbol NEUTRAL
- 20% chance of symbol POSITIVE
- 10% chance of symbol NEGATIVE
- 10% chance of symbol END-OF-DATA. (The presence of this symbol means that the stream will be 'internally terminated', as is fairly common in data compression; when this symbol appears in the data stream, the decoder will know that the entire stream has been decoded.)
Models can also handle alphabets other than the simple four-symbol set chosen for this example. More sophisticated models are also possible: higher-order modelling changes its estimation of the current probability of a symbol based on the symbols that precede it (the context), so that in a model for English text, for example, the percentage chance of "u" would be much higher when it follows a "Q" or a "q". Models can even be adaptive, so that they continually change their prediction of the data based on what the stream actually contains. The decoder must have the same model as the encoder.
Encoding and decoding: overview
In general, each step of the encoding process, except for the very last, is the same; the encoder has basically just three pieces of data to consider:
- The next symbol that needs to be encoded
- The current interval (at the very start of the encoding process, the interval is set to [0,1], but that will change)
- The probabilities the model assigns to each of the various symbols that are possible at this stage (as mentioned earlier, higher-order or adaptive models mean that these probabilities are not necessarily the same in each step.)
The encoder divides the current interval into sub-intervals, each representing a fraction of the current interval proportional to the probability of that symbol in the current context. Whichever interval corresponds to the actual symbol that is next to be encoded becomes the interval used in the next step.
Example: for the four-symbol model above:
- the interval for NEUTRAL would be [0, 0.6)
- the interval for POSITIVE would be [0.6, 0.8)
- the interval for NEGATIVE would be [0.8, 0.9)
- the interval for END-OF-DATA would be [0.9, 1).
When all symbols have been encoded, the resulting interval unambiguously identifies the sequence of symbols that produced it. Anyone who has the same final interval and model that is being used can reconstruct the symbol sequence that must have entered the encoder to result in that final interval.
It is not necessary to transmit the final interval, however; it is only necessary to transmit one fraction that lies within that interval. In particular, it is only necessary to transmit enough digits (in whatever base) of the fraction so that all fractions that begin with those digits fall into the final interval; this will guarantee that the resulting code is a prefix code.
Encoding and decoding: example

Consider the process for decoding a message encoded with the given four-symbol model. The message is encoded in the fraction 0.538 (using decimal for clarity, instead of binary; also assuming that there are only as many digits as needed to decode the message.)
The process starts with the same interval used by the encoder: [0,1), and using the same model, dividing it into the same four sub-intervals that the encoder must have. The fraction 0.538 falls into the sub-interval for NEUTRAL, [0, 0.6); this indicates that the first symbol the encoder read must have been NEUTRAL, so this is the first symbol of the message.
Next divide the interval [0, 0.6) into sub-intervals:
- the interval for NEUTRAL would be [0, 0.36), 60% of [0, 0.6).
- the interval for POSITIVE would be [0.36, 0.48), 20% of [0, 0.6).
- the interval for NEGATIVE would be [0.48, 0.54), 10% of [0, 0.6).
- the interval for END-OF-DATA would be [0.54, 0.6), 10% of [0, 0.6).
Since .538 is within the interval [0.48, 0.54), the second symbol of the message must have been NEGATIVE.
Again divide our current interval into sub-intervals:
- the interval for NEUTRAL would be [0.48, 0.516).
- the interval for POSITIVE would be [0.516, 0.528).
- the interval for NEGATIVE would be [0.528, 0.534).
- the interval for END-OF-DATA would be [0.534, 0.540).
Now 0.538 falls within the interval of the END-OF-DATA symbol; therefore, this must be the next symbol. Since it is also the internal termination symbol, it means the decoding is complete. If the stream is not internally terminated, there needs to be some other way to indicate where the stream stops. Otherwise, the decoding process could continue forever, mistakenly reading more symbols from the fraction than were in fact encoded into it.
Sources of inefficiency
The message 0.538 in the previous example could have been encoded by the equally short fractions 0.534, 0.535, 0.536, 0.537 or 0.539. This suggests that the use of decimal instead of binary introduced some inefficiency. This is correct; the information content of a three-digit decimal is bits; the same message could have been encoded in the binary fraction 0.10001010 (equivalent to 0.5390625 decimal) at a cost of only 8 bits. (The final zero must be specified in the binary fraction, or else the message would be ambiguous without external information such as compressed stream size.)

This 8 bit output is larger than the information content, or entropy of the message, which is

But an integer number of bits must be used in the binary encoding, so an encoder for this message would use at least 8 bits, resulting in a message 8.4% larger than the entropy contents. This inefficiency of at most 1 bit results in relatively less overhead as the message size grows.
Moreover, the claimed symbol probabilities were [0.6, 0.2, 0.1, 0.1), but the actual frequencies in this example are [0.33, 0, 0.33, 0.33). If the intervals are readjusted for these frequencies, the entropy of the message would be 4.755 bits and the same NEUTRAL NEGATIVE END-OF-DATA message could be encoded as intervals [0, 1/3); [1/9, 2/9); [5/27, 6/27); and a binary interval of [0.00101111011, 0.00111000111). This is also an example of how statistical coding methods like arithmetic encoding can produce an output message that is larger than the input message, especially if the probability model is off.
Adaptive arithmetic coding
One advantage of arithmetic coding over other similar methods of data compression is the convenience of adaptation. Adaptation is the changing of the frequency (or probability) tables while processing the data. The decoded data matches the original data as long as the frequency table in decoding is replaced in the same way and in the same step as in encoding. The synchronization is, usually, based on a combination of symbols occurring during the encoding and decoding process.
Precision and renormalization
The above explanations of arithmetic coding contain some simplification. In particular, they are written as if the encoder first calculated the fractions representing the endpoints of the interval in full, using infinite precision, and only converted the fraction to its final form at the end of encoding. Rather than try to simulate infinite precision, most arithmetic coders instead operate at a fixed limit of precision which they know the decoder will be able to match, and round the calculated fractions to their nearest equivalents at that precision. An example shows how this would work if the model called for the interval [0,1) to be divided into thirds, and this was approximated with 8 bit precision. Note that since now the precision is known, so are the binary ranges we'll be able to use.
| Symbol | Probability | Interval reduced to eight-bit precision | Range | |
|---|---|---|---|---|
| (expressed as fraction) | (as fractions) | (in binary) | (in binary) | |
| A | 1/3 | [0, 85/256) | [0.00000000, 0.01010101) | 00000000 – 01010100 |
| B | 1/3 | [85/256, 171/256) | [0.01010101, 0.10101011) | 01010101 – 10101010 |
| C | 1/3 | [171/256, 1) | [0.10101011, 1.00000000) | 10101011 – 11111111 |
A process called renormalization keeps the finite precision from becoming a limit on the total number of symbols that can be encoded. Whenever the range is reduced to the point where all values in the range share certain beginning digits, those digits are sent to the output. For however many digits of precision the computer can handle, it is now handling fewer than that, so the existing digits are shifted left, and at the right, new digits are added to expand the range as widely as possible. Note that this result occurs in two of the three cases from our previous example.
| Symbol | Probability | Range | Digits that can be sent to output | Range after renormalization |
|---|---|---|---|---|
| A | 1/3 | 00000000 – 01010100 | 0 | 00000000 – 10101001 |
| B | 1/3 | 01010101 – 10101010 | None | 01010101 – 10101010 |
| C | 1/3 | 10101011 – 11111111 | 1 | 01010110 – 11111111 |
Arithmetic coding as a generalized change of radix
Recall that in the case where the symbols had equal probabilities, arithmetic coding could be implemented by a simple change of base, or radix. In general, arithmetic (and range) coding may be interpreted as a generalized change of radix. For example, we may look at any sequence of symbols:

as a number in a certain base presuming that the involved symbols form an ordered set and each symbol in the ordered set denotes a sequential integer A = 0, B = 1, C = 2, D = 3, and so on. This results in the following frequencies and cumulative frequencies:
| Symbol | Frequency of occurrence | Cumulative frequency |
|---|---|---|
| A | 1 | 0 |
| B | 2 | 1 |
| D | 3 | 3 |
The cumulative frequency for an item is the sum of all frequencies preceding the item. In other words, cumulative frequency is a running total of frequencies.
In a positional numeral system the radix, or base, is numerically equal to a number of different symbols used to express the number. For example, in the decimal system the number of symbols is 10, namely 0, 1, 2, 3, 4, 5, 6, 7, 8, and 9. The radix is used to express any finite integer in a presumed multiplier in polynomial form. For example, the number 457 is actually 4×102 + 5×101 + 7×100, where base 10 is presumed but not shown explicitly.
Initially, we will convert DABDDB into a base-6 numeral, because 6 is the length of the string. The string is first mapped into the digit string 301331, which then maps to an integer by the polynomial:

The result 23671 has a length of 15 bits, which is not very close to the theoretical limit (the entropy of the message), which is approximately 9 bits.
To encode a message with a length closer to the theoretical limit imposed by information theory we need to slightly generalize the classic formula for changing the radix. We will compute lower and upper bounds L and U and choose a number between them. For the computation of L we multiply each term in the above expression by the product of the frequencies of all previously occurred symbols:

The difference between this polynomial and the polynomial above is that each term is multiplied by the product of the frequencies of all previously occurring symbols. More generally, L may be computed as:

where are the cumulative frequencies and are the frequencies of occurrences. Indexes denote the position of the symbol in a message. In the special case where all frequencies are 1, this is the change-of-base formula.


The upper bound U will be L plus the product of all frequencies; in this case U = L + (3 × 1 × 2 × 3 × 3 × 2) = 25002 + 108 = 25110. In general, U is given by:

Now we can choose any number from the interval [L, U) to represent the message; one convenient choice is the value with the longest possible trail of zeroes, 25100, since it allows us to achieve compression by representing the result as 251×102. The zeroes can also be truncated, giving 251, if the length of the message is stored separately. Longer messages will tend to have longer trails of zeroes.
To decode the integer 25100, the polynomial computation can be reversed as shown in the table below. At each stage the current symbol is identified, then the corresponding term is subtracted from the result.
| Remainder | Identification | Identified symbol | Corrected remainder |
|---|---|---|---|
| 25100 | 25100 / 65 = 3 | D | (25100 − 65 × 3) / 3 = 590 |
| 590 | 590 / 64 = 0 | A | (590 − 64 × 0) / 1 = 590 |
| 590 | 590 / 63 = 2 | B | (590 − 63 × 1) / 2 = 187 |
| 187 | 187 / 62 = 5 | D | (187 − 62 × 3) / 3 = 26 |
| 26 | 26 / 61 = 4 | D | (26 − 61 × 3) / 3 = 2 |
| 2 | 2 / 60 = 2 | B | — |
During decoding we take the floor after dividing by the corresponding power of 6. The result is then matched against the cumulative intervals and the appropriate symbol is selected from look up table. When the symbol is identified the result is corrected. The process is continued for the known length of the message or while the remaining result is positive. The only difference compared to the classical change-of-base is that there may be a range of values associated with each symbol. In this example, A is always 0, B is either 1 or 2, and D is any of 3, 4, 5. This is in exact accordance with our intervals that are determined by the frequencies. When all intervals are equal to 1 we have a special case of the classic base change.
Theoretical limit of compressed message
The lower bound L never exceeds nn, where n is the size of the message, and so can be represented in bits. After the computation of the upper bound U and the reduction of the message by selecting a number from the interval [L, U) with the longest trail of zeros we can presume that this length can be reduced by bits. Since each frequency in a product occurs exactly the same number of times as the value of this frequency, we can use the size of the alphabet A for the computation of the product



Applying log2 for the estimated number of bits in the message, the final message (not counting a logarithmic overhead for the message length and frequency tables) will match the number of bits given by entropy, which for long messages is very close to optimal:

Connections with other compression methods
Huffman coding
Because arithmetic coding doesn't compress one datum at a time, it can get arbitrarily close to entropy when compressing iid strings. By contrast, using the extension of Huffman coding (to strings) does not reach entropy unless all probabilities of alphabet symbols are powers of two, in which case both Huffman and arithmetic coding achieve entropy.
When naively Huffman coding binary strings, no compression is possible, even if entropy is low (e.g. ({0, 1}) has probabilities {0.95, 0.05}). Huffman encoding assigns 1 bit to each value, resulting in a code of the same length as the input. By contrast, arithmetic coding compresses bits well, approaching the optimal compression ratio of
![1-[-0.95\log _{2}(0.95)+-0.05\log _{2}(0.05)]\approx 71.4\%.](../I/m/6d67ecf0a07f6d1d6a34dc7730f5cfe74bc75e98.svg)
One simple way to address Huffman coding's suboptimality is to concatenate symbols ("blocking") to form a new alphabet in which each new symbol represents a sequence of original symbols — in this case bits — from the original alphabet. In the above example, grouping sequences of three symbols before encoding would produce new "super-symbols" with the following frequencies:
- 000: 85.7%
- 001, 010, 100: 4.5% each
- 011, 101, 110: 0.24% each
- 111: 0.0125%
With this grouping, Huffman coding averages 1.3 bits for every three symbols, or 0.433 bits per symbol, compared with one bit per symbol in the original encoding, i.e., compression. Allowing arbitrarily large sequences gets arbitrarily close to entropy — just like arithmetic coding — but requires huge codes to do so, so is not as practical as arithmetic coding for this purpose.

An alternative is encoding run lengths via Huffman-based Golomb-Rice codes. Such an approach allows simpler and faster encoding/decoding than arithmetic coding or even Huffman coding, since the latter requires a table lookups. In the {0.95, 0.05} example, a Golomb-Rice code with a four-bit remainder achieves a compression ratio of , far closer to optimum than using three-bit blocks. Golomb-Rice codes only apply to Bernoulli inputs such as the one in this example, however, so it is not a substitute for blocking in all cases.

{kind=link}
US patents
A variety of specific techniques for arithmetic coding have historically been covered by US patents, although various well-known methods have since passed into the public domain as the patents have expired. Techniques covered by patents may be essential for implementing the algorithms for arithmetic coding that are specified in some formal international standards. When this is the case, such patents are generally available for licensing under what is called "reasonable and non-discriminatory" (RAND) licensing terms (at least as a matter of standards-committee policy). In some well-known instances, (including some involving IBM patents that have since expired), such licenses were available for free, and in other instances, licensing fees have been required. The availability of licenses under RAND terms does not necessarily satisfy everyone who might want to use the technology, as what may seem "reasonable" for a company preparing a proprietary commercial software product may seem much less reasonable for a free software or open source project.
At least one significant compression software program, bzip2, deliberately discontinued the use of arithmetic coding in favor of Huffman coding due to the perceived patent situation at the time. Also, encoders and decoders of the JPEG file format, which has options for both Huffman encoding and arithmetic coding, typically only support the Huffman encoding option, which was originally because of patent concerns; the result is that nearly all JPEG images in use today use Huffman encoding[1] although JPEG's arithmetic coding patents[2] have expired due to the age of the JPEG standard (the design of which was approximately completed by 1990).[3] There are some archivers like PackJPG, that can losslessly convert Huffman encoded files to ones with arithmetic coding (with custom file name .pjg), showing up to 25% size saving.
Some US patents relating to arithmetic coding are listed below.
- U.S. Patent 4,122,440 — (IBM) Filed 4 March 1977, Granted 24 October 1978 (Now expired)
- U.S. Patent 4,286,256 — (IBM) Granted 25 August 1981 (Now expired)
- U.S. Patent 4,467,317 — (IBM) Granted 21 August 1984 (Now expired)
- U.S. Patent 4,652,856 — (IBM) Granted 4 February 1986 (Now expired)
- U.S. Patent 4,891,643 — (IBM) Filed 15 September 1986, granted 2 January 1990 (Now expired)
- U.S. Patent 4,905,297 — (IBM) Filed 18 November 1988, granted 27 February 1990 (Now expired)
- U.S. Patent 4,933,883 — (IBM) Filed 3 May 1988, granted 12 June 1990 (Now expired)
- U.S. Patent 4,935,882 — (IBM) Filed 20 July 1988, granted 19 June 1990 (Now expired)
- U.S. Patent 4,989,000 — Filed 19 June 1989, granted 29 January 1991 (Now expired)
- U.S. Patent 5,099,440 — (IBM) Filed 5 January 1990, granted 24 March 1992 (Now expired)
- U.S. Patent 5,272,478 — (Ricoh) Filed 17 August 1992, granted 21 December 1993 (Now expired)
Note: This list is not exhaustive. See the following link for a list of more patents.[4] The Dirac codec uses arithmetic coding and is not patent pending.[5]
Patents on arithmetic coding may exist in other jurisdictions; see software patents for a discussion of the patentability of software around the world.
Benchmarks and other technical characteristics
Every programmatic implementation of arithmetic encoding has a different compression ratio and performance. While compression ratios vary only a little (usually under 1%),[6] the code execution time can vary by a factor of 10. Choosing the right encoder from a list of publicly available encoders is not a simple task because performance and compression ratio depend also on the type of data, particularly on the size of the alphabet (number of different symbols). One of two particular encoders may have better performance for small alphabets while the other may show better performance for large alphabets. Most encoders have limitations on the size of the alphabet and many of them are specialized for alphabets of exactly two symbols (0 and 1).
Teaching aid
An interactive visualization tool for teaching arithmetic coding, dasher.tcl, was also the first prototype of the assistive communication system, Dasher.
See also
Notes
- ↑ What is JPEG? comp.compression Frequently Asked Questions (part 1/3)
- ↑ "Recommendation T.81 (1992) Corrigendum 1 (01/04)". Recommendation T.81 (1992). International Telecommunication Union. 9 November 2004. Retrieved 3 February 2011.
- ↑ JPEG Still Image Data Compression Standard, W. B. Pennebaker and J. L. Mitchell, Kluwer Academic Press, 1992. ISBN 0-442-01272-1
- ↑ comp.compression Frequently Asked Questions (part 1/3)
- ↑ Dirac video codec 1.0 released
- ↑ For instance, Howard & Vitter (1994) discuss versions of arithmetic coding based on real-number ranges, integer approximations to those ranges, and an even more restricted type of approximation that they call binary quasi-arithmetic coding. They state that the difference between real and integer versions is negligible, prove that the compression loss for their quasi-arithmetic method can be made arbitrarily small, and bound the compression loss incurred by one of their approximations as less than 0.06%. See: Howard, Paul G.; Vitter, Jeffrey S. (1994), "Arithmetic coding for data compression" (PDF), Proceedings of the IEEE, 82 (6): 857–865, doi:10.1109/5.286189 .
References
- MacKay, David J.C. (September 2003). "Chapter 6: Stream Codes". Information Theory, Inference, and Learning Algorithms. Cambridge University Press. ISBN 0-521-64298-1. Archived from the original (PDF/PostScript/DjVu/LaTeX) on 22 December 2007. Retrieved 2007-12-30.
- Press, WH; Teukolsky, SA; Vetterling, WT; Flannery, BP (2007). "Section 22.6. Arithmetic Coding". Numerical Recipes: The Art of Scientific Computing (3rd ed.). New York: Cambridge University Press. ISBN 978-0-521-88068-8.
- Rissanen, Jorma (May 1976). "Generalized Kraft Inequality and Arithmetic Coding" (PDF). IBM Journal of Research and Development. 20 (3): 198&ndash, 203. doi:10.1147/rd.203.0198. Retrieved 2007-09-21.
- Rissanen, J.J.; Langdon G.G., Jr (March 1979). "Arithmetic coding" (PDF). IBM Journal of Research and Development. 23 (2): 149&ndash, 162. doi:10.1147/rd.232.0149. Archived (PDF) from the original on 28 September 2007. Retrieved 2007-09-22.
- Witten, Ian H.; Neal, Radford M.; Cleary, John G. (June 1987). "Arithmetic Coding for Data Compression" (PDF). Communications of the ACM. 30 (6): 520&ndash, 540. doi:10.1145/214762.214771. Archived (PDF) from the original on 28 September 2007. Retrieved 2007-09-21.
- Rodionov Anatoly, Volkov Sergey (2010) “p-adic arithmetic coding” Contemporary Mathematics Volume 508, 2010 Contemporary Mathematics
- Rodionov Anatoly, Volkov Sergey (2007) ” p-adic arithmetic coding”, https://arxiv.org/abs//0704.0834v1
External links

- Newsgroup posting with a short worked example of arithmetic encoding (integer-only).
- PlanetMath article on arithmetic coding
- Anatomy of Range Encoder The article explains both range and arithmetic coding. It has also code samples for 3 different arithmetic encoders along with performance comparison.
- Introduction to Arithmetic Coding. 60 pages.
- Eric Bodden, Malte Clasen and Joachim Kneis: Arithmetic Coding revealed. Technical Report 2007-5, Sable Research Group, McGill University.
- Arithmetic Coding + Statistical Modeling = Data Compression by Mark Nelson.
- Data Compression With Arithmetic Coding by Mark Nelson (2014)
- Fast implementation of range coding and rANS by James K. Bonfield
Data compression methods | |||||||
|---|---|---|---|---|---|---|---|
| Lossless |
| ||||||
| Audio |
| ||||||
| Image |
| ||||||
| Video |
| ||||||
| Theory | |||||||
| |||||||