NIAM
Natural language Information Analysis Method (NIAM) is een informatieanalyse- en datamodelleringmethode en is onder andere ontwikkeld door Sjir Nijssen in de jaren zeventig. Het kenmerk van NIAM is dat het analyseren van informatie door middel van de menselijk gesproken taal wordt uitgevoerd. Dit heeft als voordeel dat het analyseerproces in samenwerking met de gebruiker uitgevoerd kan worden. Zo ontstaan er geen verkeerde interpretaties door de gebruiker en/of de informatieanalist. Vanuit NIAM zijn verschillende dialecten ontwikkeld waaronder object role modeling en CogNIAM.
Geschiedenis
- Begin jaren zeventig: Fillmore deed een onderzoek naar het gebruik van de gesproken taal in combinatie met onderzoekingen.
- 1974: Abrial onderzocht de relatie tussen het gebruik van semantiek (de betekenis van woorden) en binaire relaties (relaties tussen twee ‘objecten’) bij het modelleren van informatie.
- 1975: Falkenberg vervolgde het onderzoek door niet alleen deze techniek te gebruiken bij binaire relaties, maar ook bij n-aire relaties (relaties tussen n ‘objecten’).
- 1976-1977: Nijssen ontwikkelde een notatie voor deze methode en noemde dat ENALIM (Evolving Natural Language Information Model). Nijssen leidde een groep van onderzoekers uit België die deze methode verder ontwikkelde. De methode werd toen bekend als NIAM (Nijssen Information Analyse Methodology).
- Jaren tachtig: Nijssen en Falkenberg gingen samenwerken op de University of Queensland om de methode verder uit te werken.
- 1989: Nijssen schreef in samenwerking met Terry Halpin het eerste boek over deze methode.
- Begin jaren negentig: Halpin ontwikkelde een dialect gebaseerd op NIAM: formal object role modeling (FORM) en er ontstonden allerlei tools voor op de computer om met de NIAM methode informatie te modelleren.
- Halverwege jaren negentig: Guido Bakema, Jan Pieter Zwart en Harm van der Lek ontwikkelden als wiskundigen een doorontwikkeling van NIAM: Fully Communication Oriented Information Modeling (FCO-IM) waarbij een unificatie van FeitType en ObjectTypen werd doorgevoerd om een wiskundige elegantie te vinden, en hergebruik van semantiek te bevorderen.
NIAM betekent tegenwoordig “Natural language Information Analysis Method”, omdat Nijssen niet de enige was die aan deze methode had gewerkt, maar een heel team achter hem stond.
Werkwijze
De werkwijze van NIAM is geheel anders dan bij de meeste andere informatieanalysemethoden. In plaats van entiteiten te zien als gerelateerde tabellen, zijn bij NIAM de relaties de entiteiten. In NIAM’s termologie heet een relatie ook wel ‘role’. Hierdoor is het bij NIAM moeilijk om entiteiten los van elkaar te zien. In NIAM is het de bedoeling om met behulp van de menselijke gesproken taal “feiten” vast te leggen. Deze feiten bestaat in NIAM dan uit entiteiten, attributen en domeinen.
Hieronder volgt een stappenplan hoe NIAM wordt toegepast. Achter elk kernwoord van de stappen staat wat het inhoudt.
- Verwoorden betekent dat je samen met een domeindeskundige (een persoon die met de informatie werkt die de analist gaat modelleren) het hele proces verwoordt. Dit gebeurt gewoon in zijn eigen taal, daarom is het verstandig dat de informatieanalist dit ook doet in samenwerking met de domeindeskundige en niet zelf gaat verwoorden. De domeindeskundige kan het beste verwoorden wat er allemaal gebeurt in het bedrijf.
- Classificeren is het indelen van feittypen in groepen.
- Kwalificeren is een betekenisvolle naam geven aan feittypen.
- IGD (Information Grammatica Diagram) is het uiteindelijke schema met allerlei symbolen en de bijbehorende verwoorde feiten.
- Toepassen van de beperkingregels in de IGD.
- Groeperen: zo veel mogelijk feittypen samenvoegen zonder dat er redundantie optreedt.
- Lexicaliseren de IGD zodanig veranderen dat de rollen worden gespeeld door labeltypen zonder dat er redundantie optreedt.
- Tabellen genereren. Normaal genereer je de kolommen van tabellen met de entiteiten. Niet bij NIAM, daar gebruik je de rollen om kolommen te maken. Twee of meer rollen tussen twee feittypen worden de kolommen.
Schrijfwijze
Symbolen
Hieronder in figuur 1 wordt een conceptueel schema getoond. Dit diagram bestaat uit een binair feittype bestaande uit 2 rollen, de linkerrol gespeeld door het entiteittype employee, de rechterrol gespeeld door het labeltype name.
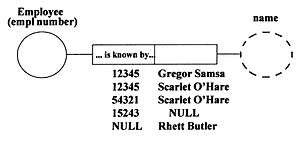
figuur 1
Beperkingregels
- Waardenregel: deze wordt opgelegd aan de labeltypen of rollen, en specificeert de waarden die instanties van deze labeltypen of rollen kunnen bevatten. Voorbeeld:
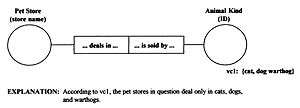
figuur 2
- Uniciteitsregel: dit is een beperkingsregel die je aan een rol of combinatie van rollen kan opleggen. Voorbeeld:

figuur 3
- Verplichtingsregel: dit is een beperkingsregel die je aan een rol oplegt. Iedere instantie van het objecttype dat de rol speelt, moet voorkomen in de populatie van het feittype waartoe de rol behoort. Voorbeeld:

figuur 4
Zie ook
- DEMO (Design and Engineering Methodology for Organizations)
- Object role modeling
- Fully Communication Oriented Information Modeling
Literatuur
- Sjir Nijssen & Terry Halpin (1989). Conceptual Schema and Relational Database Design. Prentice Hall, Sydney.
- Guido Bakema, Jan Pieter Zwart & Harm van der Lek (2002). Volledig Communicatiegeoriënteerde Informatiemodellering, FCO-IM. Den Haag: ten Hagen & Stam. ISBN 90-267-2316-4
- J.J.V.R. Wintraecken (1987). Informatie-analyse volgens NIAM in theorie en praktijk. Academic Serivce, Schoonhoven, (2e druk), ISBN 90-623-3169-6.
- Sjir Nijssen & A. Le Cat (2009), Kennis Gebaseerd Werken, ISBN 978-90-5540-013-3.
| Zie de categorie NIAM van Wikimedia Commons voor mediabestanden over dit onderwerp. |