Frequentieanalyse (statistiek)
Frequentieanalyse[1] wordt toegepast op waarnemingen aan een bepaald verschijnsel. Het verschijnsel kan tijdsafhankelijk zijn (bijvoorbeeld de gemeten neerslag in een bepaald punt) of plaatsafhankelijk (bijvoorbeeld gewasopbrensten in een gebied) of anderszins.
In de statistiek verstaat men onder de frequentie van een waarde het aantal keren dat deze waarde van een bepaald toevallig optredend verschijnsel X (de variabele) voorkomt.
Ook de term cumulatieve frequentie komt voor. Het betreft hier de studie van het aantal malen dat waarde X van het waargenomen verschijnsel kleiner is dan een referentiewaarde xr. De cumulatieve frequentie wordt ook frequentie van onderschrijding genoemd, en is verder gewoon een frequentie.
De frequentie waarmee de waarde van een bepaald verschijnsel X groter is dan de referentiewaarde xr wordt frequentie van overschrijding genoemd.
De analyse van een cumulatieve frequentie wordt bijvoorbeeld gedaan om inzicht te krijgen in hoe vaak rivierafvoeren en de bijbehorende waterstanden onder een toelaatbare waarde blijven of boven een toelaatbare waarde uitkomen in verband met de daarmee samenhangende dijkhoogte.[2] [3]
Beginselen
Definitie
Frequentie is het aantal malen dat de waarde van het verschijnsel X voorkomt. De relatieve frequentie dat in een waarnemingsreeks een waarde niet groter dan x voorkomt, wordt gegeven door de empirische verdelingsfunctie:


De frequentie is dan .

Met behulp van de empirische verdelingsfunctie kunnen allerlei andere frequenties uitgedrukt worden.
Als alle waargenomen waarden verschillend zijn, geldt voor de kleinste waargenomen waarde :


en voor de grootste waargenomen waarde :


Dit moet niet verward worden met de verdelingen van het minimum en het maximum van de waarnemingen. Beide zijn variabelen die in elke reeks waarnemingen een andere waarde kunnen hebben. Als de waarnemingen gelijkverdeeld en onderling onafhankelijk zijn geldt voor het minimum :

- ,

en voor het maximum :

- ,

Schatting
De waargenomen frequenties kunnen gebruikt worden voor het schatten van de overeenkomstige kansen.[4].
Als p de kans op een bepaald verschijnsel is en K de waargenomen frequentie in een reeks van N, dan is een voor de hand liggende schatting voor p:
- .

Alternatieve schatters zijn:

en
- ,

elk met specifieke voor- en nadelen.
De noemer N+1 bijvoorbeeld garandeert dat de kans dat X groter is dan de waargenomen niet op 0 geschat wordt.[1] Er bestaan andere voorstellen voor de noemer.[5]
Rangschikking
Er is een eenvoudig verband tussen de geordende steekproef en de empirische verdelingsfunctie. Als de realisatie is van de geordende steekproef, dan maakt de empirische verdelingsfunctie steeds een sprong van 1/N in de waarnemingen. Dus voor is:



- ,

waarin en


Voorspelling
Onzekerheid
Op basis van een reeks waarnemingen worden ook voorspellingen gedaan. Uit bijvoorbeeld de verdeling van rivierafvoeren voor de jaren 1950 tot 2000, worden de rivierafvoeren voor de jaren 2000 tot 2050 voorspeld. Een voorwaarde is wel dat de omgevingsfactoren niet veranderen. Mochten zij wel veranderen, zoals door civieltechnische ingrepen in de rivier of in het opvanggebied van het regenwater, of door klimaatveranderingen, dan is de voorspelling onderhevig aan een systematische fout. Ook zonder een systematische fout is de voorspelling onderworpen aan een toevallige fout, doordat door toeval de waargenomen afvoeren lager of hoger zijn dan normaal, of omgekeerd de afvoeren van 2000 tot 2050 door toeval hoger of lager kunnen zijn dan normaal.
Betrouwbaarheidsgordel

Ter bepaling van de betrouwbaarheid van voorspellingen op grond van een waargenomen reeks cumulatieve frequenties kunnen betrouwbaarheidsintervallen worden geconstrueerd waarmee het bereik van de waarschijnlijke fout wordt geschat.
In het geval van cumulatieve kansen zijn er slechts 'twee mogelijkheden: er vindt onderschrijding plaats of overschrijding. De som van onderschrijdings– en overschrijdingskans is 1 of 100% Daarom is de binomiale verdeling van toepassing om het betrouwbaarheidsinterval te schatten.
Voor de binomiale verdeling met parameters , de succeskans, en , het aantal waarnemingen, is de standaardafwijking gegeven door:




Het betrouwbaarheidsinterval voor de succeskans wordt voor grote waarden van afgeleid met behulp van de Student-verdeling. Een ondergrens en een bovengrens van het interval worden onder de voorwaarde niet te klein of te groot is, gegeven door:



en

Daarin is
- de fractie waargenomen successen
- een waarde uit de t-verdeling, afhankelijk van de gewenste betrouwbaarheid.


Echter, de binomiale verdeling is slechts symmetrisch rond het gemiddelde (waar Pc = 0.5), maar hij wordt meer asymmetrisch naarmate Pc nadert tot 0 of 1. Daarom kunnen bij benadering Pc en 1–Pc zelf gebruikt worden als weegfactoren bij de toewijzing van t.Sd aan U and L :
- L = Pc − 2Pc.t.Sd
- U = Pc + 2(1 − Pc).t.Sd
waaruit te zien is dat deze uitdrukkingen bij Pc=0.5 gelijk zijn aan de twee voorgaande.
| Voorbeeld N = 25, Pc = 0.8, Sd = 0.08, het betrouwbaarheidsniveau is 90%, t = 1.71, L = 0.70, U = 0.85 |
Aanpassing van waarschijnlijkheidsverdelingen
Om de cumulatieve frequentieverdeling weer te geven met een continue wiskundige vergelijking kan men trachten deze aan te passen aan een bekende cumulatieve kansverdeling[1] ,[6] . Wanneer dit gelukt is dan is de continue wiskundige vergelijking voldoende om de discrete cumulatieve kansverdeling te beschrijven en is het niet nodig deze in een tabelvorm te geven. Verder kan de vergelijking behulpzaam zijn zijn bij interpolatie en extrapolatie. Echter de extrapolatie van een cumulatieve kansverdeling kan een bron van fouten kan zijn. Een van de mogelijke fouten is dat de wiskundige verdeling de kansverdeling niet meer volgt buiten de onderzochte gegevensreeks.
Elke vergelijking die de waarde 1 oplevert bij wiskundige integratie van een ondergrens tot een bovengrens die overeenkomen met het gegevensbestand kan worden gebruikt als een kansverdeling.
De aanpassing kan gedaan worden volgens verschillende methoden[1] , bijvoorbeeld:
- de parametermethode, waarbij de parameters als gemiddelde en standaardafwijking uit de gegevens worden geschat
- de regressiemethode, waarbij de parameters worden bepaald uit een regressie van Pc (verkregen door rangschikking) op de cumulatieve waarschijnlijkheid van de aangepaste verdeling
Toepassingen van beide methoden met gebruikmaking van:
- de normale verdeling
- de lognormale verdeling
- de Gumbel verdeling of Fisher–Tippet type 1 verdeling van extreme waarden[7]
- de exponentiële verdeling
leveren mogelijk geen significant verschillende resultaten op[1] . Ook kunnen verschillende kansverdelingen ongeveer overeenkomstige resultaten opleveren en de onderlinge verschillen kunnen klein zijn vergeleken met het breedte van het betrouwbaarheidsinterval. Dit illustreert dat het soms niet eenvoudig is te bepalen welke kansverdeling de beste is.
Herhalingsperiode

De cumulatieve frequentie Pc kan ook frequentie van onderschrijding worden genoemd. De frequentie van overschrijding wordt berekend als:
- Pe = 1 − Pc.
De herhalingsperiode T wordt gedefinieerd als:
- T = 1/Pe
en geeft aan het aantal waarnemingen dat naar verwachting moet worden gedaan om opnieuw een waarde van de variable onder studie te vinden die groter is dan de waarde gebruikt bij de bepaling van T.
De beneden– en bovengrens van het betrouwbaarheidsinterval van de herhalingsperiode T worden respectievelijk gevonden als:
- TL = 1/(1−L)
- TU = 1/(1−U)
Voor extreem hoge waarden van de bestudeerde variabele is U weinig verschillend van 1 en kleine veranderingen van U leiden dan tot grote veranderingen van TU. Dus de schatting van de herhalingsperiode van extreme waarden is onderhevig aan een grote toevalsfout. Daarnaast is de betrouwbaarheidsgordel is geldig voor voorspellingen op lange termijn. Voor voorspellingen op korte termijn kan het betrouwbaarheidsinterval U−L en TU−TL wijder zijn. Samen met de beperkte zekerheid (< 100%) gebruikt in de t-toets verklaart dit waarom bijvoorbeeld een 100-jarige neerslag zich weleens 2 maal in 10 jaar voor zou kunnen doen.
Het strikte begrip herhalingsperiode heeft alleen betekenis wanneer het een tijdsafhankelijk verschijnsel betreft, zoals puntneerslag. De herhalingsperiode komt dan overeen met de geschatte wachttijd tot de overschrijding zich weer voordoet. De herhalingsperiode heeft dezelfde tijdeenheden als de tijdlengte waarvoor elke waarneming representatief is. Als het bijvoorbeeld dagneerslagen betreft dan wordt de herhalingsperiode uitgedrukt in dagen, terwijl dit jaren zou zijn voor jaarneerslagsommen.
Software
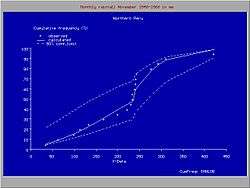
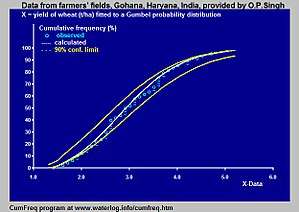
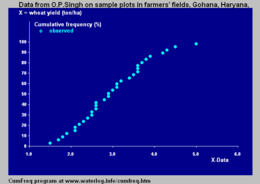
Om het maken van cumulatieve frequentieverdelingen en aanpassingen aan kansverdelingen te vereenvoudigen kan men gebruikmaken van een computerprogramma[6] als CumFreq[8] . Dit programma selecteert de best passende kansverdeling uit een aantal welbekende verdelingen of het gebruikt een verdeling naar keuze van de gebruiker.
CumFreq geeft grafieken van de waargenomen waarden, de aanpassing aan de kansverdeling en de betrouwbaarheidsgordel. Ook geeft het de wiskundige uitdrukking van de bijbehorende kansverdeling. Daarnaast geeft het grafieken van de herhalingsperioden en de bijbehorende betrouwbaarheidsintervallen.
Het model kan worden gebruikt voor elk soort gegevensbestand en dus niet noodzakelijkerwijs hydrologische gegevens.
Voor de (log)normale verdeling wordt een numerieke methode toegepast, daar een analytische uitdrukking voor de cumulatieve (log)normale verdeling niet bestaat.
Het model geeft benevens de mogelijkheid een discontinuïteit te introduceren, waarbij de gegevensreeks wordt verdeeld in twee delen met een verschillende kansverdeling. Het programma bepaalt het breekpunt door toepassing van een toets van beste aanpassing. De introductie van de discontinuïteit bleek nuttig voor de analyse van neerslag gegevens in Noord Peru, waar het klimaat afhankelijk is van het gedrag van de oceaanstroming El Niño. Wanneer de Niño zich uitbreidt naar van Ecuador naar het noorden van Peru, dan wordt het klimaat aldaar tropisch nat. Echter wanneer de Niño Peru niet bereikt, is het klimaat semi–aride. Hierdoor volgen de hogere neerslagen een andere frequentieverdeling dan de lagere.
Zie ook
Bronnen, noten en/of referenties
|