Hamming distance
In information theory, the Hamming distance between two strings of equal length is the number of positions at which the corresponding symbols are different. In other words, it measures the minimum number of substitutions required to change one string into the other, or the minimum number of errors that could have transformed one string into the other. In a more general context, the Hamming distance is one of several string metrics for measuring the edit distance between two sequences. It is named after the American mathematician Richard Hamming.
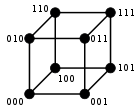
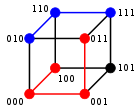
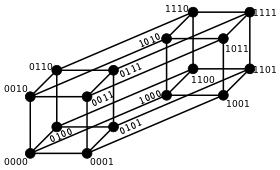
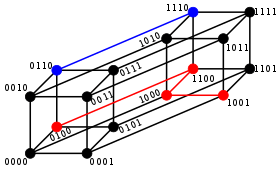
A major application is in coding theory, more specifically to block codes, in which the equal-length strings are vectors over a finite field.
Examples
The Hamming distance between:
- "karolin" and "kathrin" is 3.
- "karolin" and "kerstin" is 3.
- 1011101 and 1001001 is 2.
- 2173896 and 2233796 is 3.
Properties
For a fixed length n, the Hamming distance is a metric on the set of the words of length n (also known as a Hamming space), as it fulfills the conditions of non-negativity, identity of indiscernibles and symmetry, and it can be shown by complete induction that it satisfies the triangle inequality as well.[1] The Hamming distance between two words a and b can also be seen as the Hamming weight of a − b for an appropriate choice of the − operator, much as the difference between two integers can be seen as a distance from zero on the number line.
For binary strings a and b the Hamming distance is equal to the number of ones (population count) in a XOR b.[2] The metric space of length-n binary strings, with the Hamming distance, is known as the Hamming cube; it is equivalent as a metric space to the set of distances between vertices in a hypercube graph. One can also view a binary string of length n as a vector in by treating each symbol in the string as a real coordinate; with this embedding, the strings form the vertices of an n-dimensional hypercube, and the Hamming distance of the strings is equivalent to the Manhattan distance between the vertices.

Error detection and error correction
The minimum Hamming distance is used to define some essential notions in coding theory, such as error detecting and error correcting codes. In particular, a code C is said to be k error detecting if, and only if, the minimum Hamming distance between any two of its codewords is at least k+1.[1]
For example, consider the code consisting of two codewords "000" and "111". The hamming distance between these two words is 3, and therefore it is k=2 error detecting. Which means that if one bit is flipped or two bits are flipped, the error can be detected. If three bits are flipped, then "000" becomes "111" and the error can not be detected.
A code C is said to be k-errors correcting if, for every word w in the underlying Hamming space H, there exists at most one codeword c (from C) such that the Hamming distance between w and c is at most k. In other words, a code is k-errors correcting if, and only if, the minimum Hamming distance between any two of its codewords is at least 2k+1. This is more easily understood geometrically as any closed balls of radius k centered on distinct codewords being disjoint.[1] These balls are also called Hamming spheres in this context.[3]
For example, consider the same 3 bit code consisting of two codewords "000" and "111". The Hamming space consists of 8 words 000, 001, 010, 011, 100, 101, 110 and 111. The codeword "000" and the single bit error words "001","010","100" are all less than or equal to the Hamming distance of 1 to "000". Likewise, codeword "111" and its single bit error words "110","101" and "011" are all within 1 Hamming distance of the original "111". In this code, a single bit error is always within 1 Hamming distance of the original codes, and the code can be 1-error correcting, that is k=1. The minimum Hamming distance between "000" and "111" is 3, which satisfies 2k+1 = 3.
Thus a code with minimum Hamming distance d between its codewords can detect at most d-1 errors and can correct ⌊(d-1)/2⌋ errors.[1] The latter number is also called the packing radius or the error-correcting capability of the code.[3]
History and applications
The Hamming distance is named after Richard Hamming, who introduced the concept in his fundamental paper on Hamming codes, Error detecting and error correcting codes, in 1950.[4] Hamming weight analysis of bits is used in several disciplines including information theory, coding theory, and cryptography.
It is used in telecommunication to count the number of flipped bits in a fixed-length binary word as an estimate of error, and therefore is sometimes called the signal distance.[5] For q-ary strings over an alphabet of size q ≥ 2 the Hamming distance is applied in case of the q-ary symmetric channel, while the Lee distance is used for phase-shift keying or more generally channels susceptible to synchronization errors because the Lee distance accounts for errors of ±1.[6] If or both distances coincide because any pair of elements from or differ by 1, but the distances are different for larger .





The Hamming distance is also used in systematics as a measure of genetic distance.[7]
However, for comparing strings of different lengths, or strings where not just substitutions but also insertions or deletions have to be expected, a more sophisticated metric like the Levenshtein distance is more appropriate.
In processor interconnects, the dynamic energy consumption depends on the number of transitions. With level-signaling scheme, the number of transitions depends on Hamming distance between consecutively transmitted buses.[8] Hence, by reducing this Hamming distance, the data-movement energy can be reduced.
Algorithm example
The following function, written in Python 3.7, returns the Hamming distance between two strings:
def hamming_distance(string1, string2):
dist_counter = 0
for n in range(len(string1)):
if string1[n] != string2[n]:
dist_counter += 1
return dist_counter
The function hamming_distance(), implemented in Python 2.3+, computes the Hamming distance between
two strings (or other iterable objects) of equal length by creating a sequence of Boolean values indicating mismatches and matches between corresponding positions in the two inputs and then summing the sequence with False and True values being interpreted as zero and one.
def hamming_distance(s1, s2) -> int:
"""Return the Hamming distance between equal-length sequences."""
if len(s1) != len(s2):
raise ValueError("Undefined for sequences of unequal length.")
return sum(el1 != el2 for el1, el2 in zip(s1, s2))
where the zip() function merges two equal-length collections in pairs.
The following C function will compute the Hamming distance of two integers (considered as binary values, that is, as sequences of bits). The running time of this procedure is proportional to the Hamming distance rather than to the number of bits in the inputs. It computes the bitwise exclusive or of the two inputs, and then finds the Hamming weight of the result (the number of nonzero bits) using an algorithm of Wegner (1960) that repeatedly finds and clears the lowest-order nonzero bit. Some compilers support the __builtin_popcount function which can calculate this using specialized processor hardware where available.
int hamming_distance(unsigned x, unsigned y)
{
int dist = 0;
// Count the number of bits set
for (unsigned val = x ^ y; val > 0; val = val >> 1)
{
// If A bit is set, so increment the count
if (val & 1)
dist++;
// Clear (delete) val's lowest-order bit
}
// Return the number of differing bits
return dist;
}
Or, a much faster hardware alternative (for compilers that support builtins) is to use popcount like so.
int hamming_distance(unsigned x, unsigned y)
{
return __builtin_popcount(x ^ y);
}
//if your compiler supports 64-bit integers
int hamming_distance(unsigned long long x, unsigned long long y)
{
return __builtin_popcountll(x ^ y);
}
See also
- Closest string
- Damerau–Levenshtein distance
- Euclidean distance
- Gap-Hamming problem
- Gray code
- Jaccard index
- Levenshtein distance
- Mahalanobis distance
- Sørensen similarity index
- Sparse distributed memory
- Word ladder
References
- Robinson, Derek J. S. (2003). An Introduction to Abstract Algebra. Walter de Gruyter. pp. 255–257. ISBN 978-3-11-019816-4.
- Warren, Jr., Henry S. (2013) [2002]. Hacker's Delight (2 ed.). Addison Wesley - Pearson Education, Inc. pp. 81–96. ISBN 978-0-321-84268-8. 0-321-84268-5.
- Cohen, G.; Honkala, I.; Litsyn, S.; Lobstein, A. (1997), Covering Codes, North-Holland Mathematical Library, 54, Elsevier, pp. 16–17, ISBN 9780080530079
- Hamming, R. W. (April 1950). "Error detecting and error correcting codes" (PDF). The Bell System Technical Journal. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. ISSN 0005-8580.
- Ayala, Jose (2012). Integrated Circuit and System Design. Springer. p. 62. ISBN 978-3-642-36156-2.
- Roth, Ron (2006). Introduction to Coding Theory. Cambridge University Press. p. 298. ISBN 978-0-521-84504-5.
- Pilcher, Christopher D.; Wong, Joseph K.; Pillai, Satish K. (2008-03-18). "Inferring HIV Transmission Dynamics from Phylogenetic Sequence Relationships". PLOS Medicine. 5 (3): e69. doi:10.1371/journal.pmed.0050069. ISSN 1549-1676. PMC 2267810. PMID 18351799.
- "A Survey of Encoding Techniques for Reducing Data-Movement Energy", JSA, 2018
Further reading
- Wegner, Peter (1960). "A technique for counting ones in a binary computer". Communications of the ACM. 3 (5): 322. doi:10.1145/367236.367286.
- MacKay, David J. C. (2003). Information Theory, Inference, and Learning Algorithms. Cambridge: Cambridge University Press. ISBN 0-521-64298-1.