Lasso (statistics)
In statistics and machine learning, lasso (least absolute shrinkage and selection operator; also Lasso or LASSO) is a regression analysis method that performs both variable selection and regularization in order to enhance the prediction accuracy and interpretability of the statistical model it produces. It was originally introduced in geophysics literature in 1986,[1] and later independently rediscovered and popularized in 1996 by Robert Tibshirani,[2] who coined the term and provided further insights into the observed performance.
Lasso was originally formulated for linear regression models and this simple case reveals a substantial amount about the behavior of the estimator, including its relationship to ridge regression and best subset selection and the connections between lasso coefficient estimates and so-called soft thresholding. It also reveals that (like standard linear regression) the coefficient estimates do not need to be unique if covariates are collinear.
Though originally defined for linear regression, lasso regularization is easily extended to a wide variety of statistical models including generalized linear models, generalized estimating equations, proportional hazards models, and M-estimators, in a straightforward fashion.[2][3] Lasso’s ability to perform subset selection relies on the form of the constraint and has a variety of interpretations including in terms of geometry, Bayesian statistics, and convex analysis.
The LASSO is closely related to basis pursuit denoising.
Motivation
Lasso was introduced in order to improve the prediction accuracy and interpretability of regression models by altering the model fitting process to select only a subset of the provided covariates for use in the final model rather than using all of them.[2][4] It was developed independently in geophysics, based on prior work that used the penalty for both fitting and penalization of the coefficients, and by the statistician, Robert Tibshirani based on Breiman’s nonnegative garrote.[4][5]

Prior to lasso, the most widely used method for choosing which covariates to include was stepwise selection, which only improves prediction accuracy in certain cases, such as when only a few covariates have a strong relationship with the outcome. However, in other cases, it can make prediction error worse. Also, at the time, ridge regression was the most popular technique for improving prediction accuracy. Ridge regression improves prediction error by shrinking large regression coefficients in order to reduce overfitting, but it does not perform covariate selection and therefore does not help to make the model more interpretable.
Lasso is able to achieve both of these goals by forcing the sum of the absolute value of the regression coefficients to be less than a fixed value, which forces certain coefficients to be set to zero, effectively choosing a simpler model that does not include those coefficients. This idea is similar to ridge regression, in which the sum of the squares of the coefficients is forced to be less than a fixed value, though in the case of ridge regression, this only shrinks the size of the coefficients, it does not set any of them to zero.
Basic form
Lasso was originally introduced in the context of least squares, and it can be instructive to consider this case first, since it illustrates many of lasso’s properties in a straightforward setting.
Consider a sample consisting of N cases, each of which consists of p covariates and a single outcome. Let be the outcome and be the covariate vector for the ith case. Then the objective of lasso is to solve



Here is a prespecified free parameter that determines the amount of regularisation. Letting be the covariate matrix, so that and is the ith row of , the expression can be written more compactly as





where is the standard norm, and is an vector of ones.




Denoting the scalar mean of the data points by and the mean of the response variables by , the resulting estimate for will end up being , so that






and therefore it is standard to work with variables that have been centered (made zero-mean). Additionally, the covariates are typically standardized so that the solution does not depend on the measurement scale.

It can be helpful to rewrite

in the so-called Lagrangian form

where the exact relationship between and is data dependent.

Orthonormal covariates
Some basic properties of the lasso estimator can now be considered.
Assuming first that the covariates are orthonormal so that , where is the inner product and is the Kronecker delta, or, equivalently, , then using subgradient methods it can be shown that





is referred to as the soft thresholding operator, since it translates values towards zero (making them exactly zero if they are small enough) instead of setting smaller values to zero and leaving larger ones untouched as the hard thresholding operator, often denoted , would.


This can be compared to ridge regression, where the objective is to minimize

yielding

So ridge regression shrinks all coefficients by a uniform factor of and does not set any coefficients to zero.

It can also be compared to regression with best subset selection, in which the goal is to minimize

where is the " norm", which is defined as if exactly m components of z are nonzero. In this case, it can be shown that




where is the so-called hard thresholding function and is an indicator function (it is 1 if its argument is true and 0 otherwise).

Therefore, the lasso estimates share features of the estimates from both ridge and best subset selection regression since they both shrink the magnitude of all the coefficients, like ridge regression, but also set some of them to zero, as in the best subset selection case. Additionally, while ridge regression scales all of the coefficients by a constant factor, lasso instead translates the coefficients towards zero by a constant value and sets them to zero if they reach it.
Correlated covariates
Returning to the general case, in which the different covariates may not be independent, a special case may be considered in which two of the covariates, say j and k, are identical for each case, so that , where . Then the values of and that minimize the lasso objective function are not uniquely determined. In fact, if there is some solution in which , then if replacing by and by , while keeping all the other fixed, gives a new solution, so the lasso objective function then has a continuum of valid minimizers.[6] Several variants of the lasso, including the Elastic Net, have been designed to address this shortcoming, which are discussed below.












General form
Lasso regularization can be extended to a wide variety of objective functions such as those for generalized linear models, generalized estimating equations, proportional hazards models, and M-estimators in general, in the obvious way.[2][3] Given the objective function

the lasso regularized version of the estimator will be the solution to

where only is penalized while is free to take any allowed value, just as was not penalized in the basic case.


Interpretations
Geometric interpretation
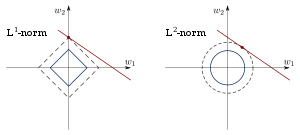
As discussed above, lasso can set coefficients to zero, while ridge regression, which appears superficially similar, cannot. This is due to the difference in the shape of the constraint boundaries in the two cases. Both lasso and ridge regression can be interpreted as minimizing the same objective function

but with respect to different constraints: for lasso and for ridge. From the figure, one can see that the constraint region defined by the norm is a square rotated so that its corners lie on the axes (in general a cross-polytope), while the region defined by the norm is a circle (in general an n-sphere), which is rotationally invariant and, therefore, has no corners. As seen in the figure, a convex object that lies tangent to the boundary, such as the line shown, is likely to encounter a corner (or a higher-dimensional equivalent) of a hypercube, for which some components of are identically zero, while in the case of an n-sphere, the points on the boundary for which some of the components of are zero are not distinguished from the others and the convex object is no more likely to contact a point at which some components of are zero than one for which none of them are.



Making easy to interpret with an accuracy-simplicity tradeoff [7]
The lasso can be rescaled so that it becomes easy to anticipate and influence what degree of shrinkage is associated with a given value of (Hoornweg, 2018). It is assumed that is standardized with z-scores and that is centered so that it has a mean of zero. Let represent the hypothesized regression coefficients and let refer to the data-optimized ordinary least squares solutions. We can then define the Lagrangian as a tradeoff between the in-sample accuracy of the data-optimized solutions and the simplicity of sticking to the hypothesized values. This results in



where is specified below. The first fraction represents relative accuracy, the second fraction relative simplicity, and balances between the two.

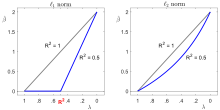




If there is a single regressor, then relative simplicity can be defined by specifying as , which is the maximum amount of deviation from when . Assuming that , the solution path can then be defined in terms of the famous accuracy measure called :




If , the OLS solution is used. The hypothesized value of is selected if is bigger than . Furthermore, if , then represents the proportional influence of . In other words, measures in percentage terms what the minimal amount of influence is of the hypothesized value relative to the data-optimized OLS solution.


If an -norm is used to penalize deviations from zero when there is a single regressor, the solution path is given by . Like , moves in the direction of the point when is close to zero; but unlike , the influence of diminishes in if increases (see figure).




When there are multiple regressors, the moment that a parameter is activated (i.e. allowed to deviate from ) is also determined by a regressor's contribution to accuracy. First, we define

An of 75% means that the in-sample accuracy improves by 75% if the unrestricted OLS solutions are used instead of the hypothesized values. The individual contribution of deviating from each hypothesis can be computed with the times matrix


where . If when is computed, then the diagonal elements of sum to . The diagonal values may be smaller than 0 and, in more exceptional cases, larger than 1. If regressors are uncorrelated, then the diagonal element of simply corresponds to the value between and .





Now, we can obtain a rescaled version of the adaptive lasso of Zou (2006) by setting . If regressors are uncorrelated, the moment that the parameter is activated is given by the diagonal element of . If we also assume for convenience that is a vector of zeros, we get


That is, if regressors are uncorrelated, again specifies what the minimal influence of is. Even when regressors are correlated, moreover, the first time that a regression parameter is activated occurs when is equal to the highest diagonal element of .
These results can be compared to a rescaled version of the lasso if we define , which is the average absolute deviation of from . If we assume that regressors are uncorrelated, then the moment of activation of the regressor is given by


For , the moment of activation is again given by . Moreover, if is a vector of zeros and there is a subset of relevant parameters that are equally responsible for a perfect fit of , then this subset will be activated at a value of . After all, the moment of activation of a relevant regressor then equals . In other words, the inclusion of irrelevant regressors delays the moment that relevant regressors are activated by this rescaled lasso. The adaptive lasso and the lasso are special cases of a '1ASTc' estimator. The latter only groups parameters together if the absolute correlation among regressors is larger than a user-specified value. For further details, see Hoornweg (2018).[7]





Bayesian interpretation
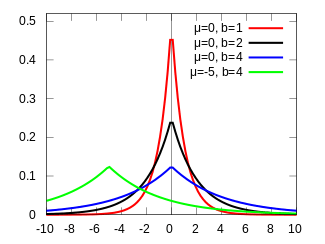
Just as ridge regression can be interpreted as linear regression for which the coefficients have been assigned normal prior distributions, lasso can be interpreted as linear regression for which the coefficients have Laplace prior distributions. The Laplace distribution is sharply peaked at zero (its first derivative is discontinuous) and it concentrates its probability mass closer to zero than does the normal distribution. This provides an alternative explanation of why lasso tends to set some coefficients to zero, while ridge regression does not.[2]
Convex relaxation interpretation
Lasso can also be viewed as a convex relaxation of the best subset selection regression problem, which is to find the subset of covariates that results in the smallest value of the objective function for some fixed , where n is the total number of covariates. The " norm", , which gives the number of nonzero entries of a vector, is the limiting case of " norms", of the form (where the quotation marks signify that these are not really norms for since is not convex for , so the triangle inequality does not hold). Therefore, since p = 1 is the smallest value for which the " norm" is convex (and therefore actually a norm), lasso is, in some sense, the best convex approximation to the best subset selection problem, since the region defined by is the convex hull of the region defined by for .







Generalizations
A number of lasso variants have been created in order to remedy certain limitations of the original technique and to make the method more useful for particular problems. Almost all of these focus on respecting or utilizing different types of dependencies among the covariates. Elastic net regularization adds an additional ridge regression-like penalty which improves performance when the number of predictors is larger than the sample size, allows the method to select strongly correlated variables together, and improves overall prediction accuracy.[6] Group lasso allows groups of related covariates to be selected as a single unit, which can be useful in settings where it does not make sense to include some covariates without others.[8] Further extensions of group lasso to perform variable selection within individual groups (sparse group lasso) and to allow overlap between groups (overlap group lasso) have also been developed.[9][10] Fused lasso can account for the spatial or temporal characteristics of a problem, resulting in estimates that better match the structure of the system being studied.[11] Lasso regularized models can be fit using a variety of techniques including subgradient methods, least-angle regression (LARS), and proximal gradient methods. Determining the optimal value for the regularization parameter is an important part of ensuring that the model performs well; it is typically chosen using cross-validation.
Elastic net
In 2005, Zou and Hastie introduced the elastic net to address several shortcomings of lasso.[6] When p > n (the number of covariates is greater than the sample size) lasso can select only n covariates (even when more are associated with the outcome) and it tends to select only one covariate from any set of highly correlated covariates. Additionally, even when n > p, if the covariates are strongly correlated, ridge regression tends to perform better.
The elastic net extends lasso by adding an additional penalty term giving

which is equivalent to solving

Somewhat surprisingly, this problem can be written in a simple lasso form

letting
- , ,



Then , which, when the covariates are orthogonal to each other, gives


So the result of the elastic net penalty is a combination of the effects of the lasso and Ridge penalties.
Returning to the general case, the fact that the penalty function is now strictly convex means that if , , which is a change from lasso.[6] In general, if



is the sample correlation matrix because the 's are normalized.

Therefore, highly correlated covariates will tend to have similar regression coefficients, with the degree of similarity depending on both and , which is very different from lasso. This phenomenon, in which strongly correlated covariates have similar regression coefficients, is referred to as the grouping effect and is generally considered desirable since, in many applications, such as identifying genes associated with a disease, one would like to find all the associated covariates, rather than selecting only one from each set of strongly correlated covariates, as lasso often does.[6] In addition, selecting only a single covariate from each group will typically result in increased prediction error, since the model is less robust (which is why ridge regression often outperforms lasso).


Group lasso
In 2006, Yuan and Lin introduced the group lasso in order to allow predefined groups of covariates to be selected into or out of a model together, where all the members of a particular group are either included or not included.[8] While there are many settings in which this is useful, perhaps the most obvious is when levels of a categorical variable are coded as a collection of binary covariates. In this case, it often doesn't make sense to include only a few levels of the covariate; the group lasso can ensure that all the variables encoding the categorical covariate are either included or excluded from the model together. Another setting in which grouping is natural is in biological studies. Since genes and proteins often lie in known pathways, an investigator may be more interested in which pathways are related to an outcome than whether particular individual genes are. The objective function for the group lasso is a natural generalization of the standard lasso objective

where the design matrix and covariate vector have been replaced by a collection of design matrices and covariate vectors , one for each of the J groups. Additionally, the penalty term is now a sum over norms defined by the positive definite matrices . If each covariate is in its own group and , then this reduces to the standard lasso, while if there is only a single group and , it reduces to ridge regression. Since the penalty reduces to an norm on the subspaces defined by each group, it cannot select out only some of the covariates from a group, just as ridge regression cannot. However, because the penalty is the sum over the different subspace norms, as in the standard lasso, the constraint has some non-differential points, which correspond to some subspaces being identically zero. Therefore, it can set the coefficient vectors corresponding to some subspaces to zero, while only shrinking others. However, it is possible to extend the group lasso to the so-called sparse group lasso, which can select individual covariates within a group, by adding an additional penalty to each group subspace.[9] Another extension, group lasso with Overlap allows covariates to be shared between different groups, e.g. if a gene were to occur in two pathways.[10]




Fused lasso
In some cases, the object being studied may have important spatial or temporal structure that must be accounted for during analysis, such as time series or image based data. In 2005, Tibshirani and colleagues introduced the fused lasso to extend the use of lasso to exactly this type of data.[11] The fused lasso objective function is

The first constraint is just the typical lasso constraint, but the second directly penalizes large changes with respect to the temporal or spatial structure, which forces the coefficients to vary in a smooth fashion that reflects the underlying logic of the system being studied. Clustered lasso[12] is a generalization to fused lasso that identifies and groups relevant covariates based on their effects (coefficients). The basic idea is to penalize the differences between the coefficients so that nonzero ones make clusters together. This can be modeled using the following regularization:

In contrast, one can first cluster variables into highly correlated groups, and then extract a single representative covariate from each cluster.[13]
Several algorithms exist that solve the fused lasso problem, and some generalizations of, in a direct form, i.e., there are algorithm that solve it exactly in a finite number of operations.[14]
Quasi-norms and bridge regression




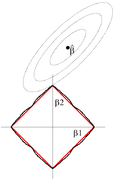
Lasso, elastic net, group and fused lasso construct the penalty functions from the and norms (with weights, if necessary). The bridge regression utilises general norms () and quasinorms ().[16] For example, for p=1/2 the analogue of lasso objective in the Lagrangian form is to solve



where

It is claimed that the fractional quasi-norms () provide more meaningful results in data analysis both from the theoretical and empirical perspective.[17] But non-convexity of these quasi-norms causes difficulties in solution of the optimization problem. To solve this problem, an expectation-minimization procedure is developed[18] and implemented[15] for minimization of function

where is an arbitrary concave monotonically increasing function (for example, gives the lasso penalty and gives the penalty).




The efficient algorithm for minimization is based on piece-wise quadratic approximation of subquadratic growth (PQSQ).[18]
Adaptive lasso
The adaptive lasso was introduced by Zou (2006, JASA) for linear regression and by Zhang and Lu (2007, Biometrika) for proportional hazards regression.
Prior lasso
The prior lasso was introduced by Jiang et al. (2016) for generalized linear models to incorporate prior information, such as the importance of certain covariates.[19] In prior lasso, such information is summarized into pseudo responses (called prior responses) and then an additional criterion function is added to the usual objective function of the generalized linear models with a lasso penalty. Without loss of generality, we use linear regression to illustrate prior lasso. In linear regression, the new objective function can be written as


which is equivalent to

the usual lasso objective function with the responses being replaced by a weighted average of the observed responses and the prior responses (called the adjusted response values by the prior information).

In prior lasso, the parameter is called a balancing parameter, which balances the relative importance of the data and the prior information. In the extreme case of , prior lasso is reduced to lasso. If , prior lasso will solely rely on the prior information to fit the model. Furthermore, the balancing parameter has another appealing interpretation: it controls the variance of in its prior distribution from a Bayesian viewpoint.



Prior lasso is more efficient in parameter estimation and prediction (with a smaller estimation error and prediction error) when the prior information is of high quality, and is robust to the low quality prior information with a good choice of the balancing parameter .
Computing lasso solutions
The loss function of the lasso is not differentiable, but a wide variety of techniques from convex analysis and optimization theory have been developed to compute the solutions path of the lasso. These include coordinate descent,[20] subgradient methods, least-angle regression (LARS), and proximal gradient methods.[21] Subgradient methods, are the natural generalization of traditional methods such as gradient descent and stochastic gradient descent to the case in which the objective function is not differentiable at all points. LARS is a method that is closely tied to lasso models, and in many cases allows them to be fit very efficiently, though it may not perform well in all circumstances. LARS generates complete solution paths.[21] Proximal methods have become popular because of their flexibility and performance and are an area of active research. The choice of method will depend on the particular lasso variant being used, the data, and the available resources. However, proximal methods will generally perform well in most circumstances.
Choice of regularization parameter
Choosing the regularization parameter () is also a fundamental part of using the lasso. Selecting it well is essential to the performance of lasso since it controls the strength of shrinkage and variable selection, which, in moderation can improve both prediction accuracy and interpretability. However, if the regularization becomes too strong, important variables may be left out of the model and coefficients may be shrunk excessively, which can harm both predictive capacity and the inferences drawn. Cross-validation is often used to select the regularization parameter.
Information criteria such as the Bayesian information criterion (BIC) and the Akaike information criterion (AIC) might be preferable to cross-validation, because they are faster to compute while their performance is less volatile in small samples.[22] An information criterion selects the estimator's regularization parameter by maximizing a model's in-sample accuracy while penalizing its effective number of parameters/degrees of freedom. Zou et al. (2007) propose to measure the effective degrees of freedom by counting the number of parameters that deviate from zero.[23] The degrees of freedom approach was considered flawed by Kaufman and Rosset (2014)[24] and Janson et al. (2015),[25] because a model's degrees of freedom might increase even when it is penalized harder by the regularization parameter. As an alternative, one can use the relative simplicity measure defined above to count the effective number of parameters (Hoornweg, 2018).[22] For the lasso, this measure is given by
,

which monotonically increases from zero to as the regularization parameter decreases from to zero.

References
- Santosa, Fadil; Symes, William W. (1986). "Linear inversion of band-limited reflection seismograms". SIAM Journal on Scientific and Statistical Computing. SIAM. 7 (4): 1307–1330. doi:10.1137/0907087.
- Tibshirani, Robert (1996). "Regression Shrinkage and Selection via the lasso". Journal of the Royal Statistical Society. Series B (methodological). Wiley. 58 (1): 267–88. JSTOR 2346178.
- Tibshirani, Robert (1997). "The lasso Method for Variable Selection in the Cox Model". Statistics in Medicine. 16 (4): 385–395. CiteSeerX 10.1.1.411.8024. doi:10.1002/(SICI)1097-0258(19970228)16:4<385::AID-SIM380>3.0.CO;2-3. PMID 9044528.
- Santosa, Fadil; Symes, William W. (1986). "Linear inversion of band-limited reflection seismograms". SIAM Journal on Scientific and Statistical Computing. SIAM. 7 (4): 1307–1330. doi:10.1137/0907087.
- Breiman, Leo (1995). "Better Subset Regression Using the Nonnegative Garrote". Technometrics. 37 (4): 373–84. doi:10.1080/00401706.1995.10484371.
- Zou, Hui; Hastie, Trevor (2005). "Regularization and Variable Selection via the Elastic Net". Journal of the Royal Statistical Society. Series B (statistical Methodology). Wiley. 67 (2): 301–20. doi:10.1111/j.1467-9868.2005.00503.x. JSTOR 3647580.
- Hoornweg, Victor (2018). "Chapter 8". Science: Under Submission. Hoornweg Press. ISBN 978-90-829188-0-9.
- Yuan, Ming; Lin, Yi (2006). "Model Selection and Estimation in Regression with Grouped Variables". Journal of the Royal Statistical Society. Series B (statistical Methodology). Wiley. 68 (1): 49–67. doi:10.1111/j.1467-9868.2005.00532.x. JSTOR 3647556.
- Puig, Arnau Tibau, Ami Wiesel, and Alfred O. Hero. "A Multidimensional Shrinkage-Thresholding Operator". Proceedings of the 15th workshop on Statistical Signal Processing, SSP’09, IEEE, pp. 113–116.
- Jacob, Laurent, Guillaume Obozinski, and Jean-Philippe Vert. "Group Lasso with Overlap and Graph LASSO". Appearing in Proceedings of the 26th International Conference on Machine Learning, Montreal, Canada, 2009.
- Tibshirani, Robert, Michael Saunders, Saharon Rosset, Ji Zhu, and Keith Knight. 2005. “Sparsity and Smoothness via the Fused lasso”. Journal of the Royal Statistical Society. Series B (statistical Methodology) 67 (1). Wiley: 91–108. https://www.jstor.org/stable/3647602.
- She, Yiyuan (2010). "Sparse regression with exact clustering". Electronic Journal of Statistics. 4: 1055–1096. doi:10.1214/10-EJS578.
- Reid, Stephen (2015). "Sparse regression and marginal testing using cluster prototypes". Biostatistics. 17 (2): 364–76. arXiv:1503.00334. Bibcode:2015arXiv150300334R. doi:10.1093/biostatistics/kxv049. PMC 5006118. PMID 26614384.
- Bento, Jose (2018). "On the Complexity of the Weighted Fused Lasso". IEEE Letters in Signal Processing. 25 (10): 1595–1599. arXiv:1801.04987. Bibcode:2018ISPL...25.1595B. doi:10.1109/LSP.2018.2867800.
- Mirkes E.M. PQSQ-regularized-regression repository, GitHub.
- Fu, Wenjiang J. 1998. “The Bridge versus the Lasso”. Journal of Computational and Graphical Statistics 7 (3). Taylor & Francis: 397-416.
- Aggarwal C.C., Hinneburg A., Keim D.A. (2001) "On the Surprising Behavior of Distance Metrics in High Dimensional Space." In: Van den Bussche J., Vianu V. (eds) Database Theory — ICDT 2001. ICDT 2001. Lecture Notes in Computer Science, Vol. 1973. Springer, Berlin, Heidelberg, pp. 420-434.
- Gorban, A.N.; Mirkes, E.M.; Zinovyev, A. (2016) "Piece-wise quadratic approximations of arbitrary error functions for fast and robust machine learning." Neural Networks, 84, 28-38.
- Jiang, Yuan (2016). "Variable selection with prior information for generalized linear models via the prior lasso method". Journal of the American Statistical Association. 111 (513): 355–376. doi:10.1080/01621459.2015.1008363. PMC 4874534. PMID 27217599.
- Jerome Friedman, Trevor Hastie, and Robert Tibshirani. 2010. “Regularization Paths for Generalized Linear Models via Coordinate Descent”. Journal of Statistical Software 33 (1): 1-21. https://www.jstatsoft.org/article/view/v033i01/v33i01.pdf.
- Efron, Bradley, Trevor Hastie, Iain Johnstone, and Robert Tibshirani. 2004. “Least Angle Regression”. The Annals of Statistics 32 (2). Institute of Mathematical Statistics: 407–51. https://www.jstor.org/stable/3448465.
- Hoornweg, Victor (2018). "Chapter 9". Science: Under Submission. Hoornweg Press. ISBN 978-90-829188-0-9.
- Zou, Hui; Hastie, Trevor; Tibshirani, Robert (2007). "On the 'Degrees of Freedom' of the Lasso". The Annals of Statistics. 35 (5): 2173–2792. doi:10.1214/009053607000000127.
- Kaufman, S.; Rosset, S. (2014). "When does more regularization imply fewer degrees of freedom? Sufficient conditions and counterexamples". Biometrika. 101 (4): 771–784. doi:10.1093/biomet/asu034. ISSN 0006-3444.
- Janson, Lucas; Fithian, William; Hastie, Trevor J. (2015). "Effective degrees of freedom: a flawed metaphor". Biometrika. 102 (2): 479–485. doi:10.1093/biomet/asv019. ISSN 0006-3444. PMC 4787623. PMID 26977114.