TMEM63A
| TMEM63A | |||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Identifiers | |||||||||||||||||||||||||
| Aliases | TMEM63A, KIAA0792, transmembrane protein 63A | ||||||||||||||||||||||||
| External IDs | MGI: 2384789 HomoloGene: 101673 GeneCards: TMEM63A | ||||||||||||||||||||||||
| |||||||||||||||||||||||||
| |||||||||||||||||||||||||
| |||||||||||||||||||||||||
| |||||||||||||||||||||||||
| Orthologs | |||||||||||||||||||||||||
| Species | Human | Mouse | |||||||||||||||||||||||
| Entrez | |||||||||||||||||||||||||
| Ensembl | |||||||||||||||||||||||||
| UniProt | |||||||||||||||||||||||||
| RefSeq (mRNA) | |||||||||||||||||||||||||
| RefSeq (protein) | |||||||||||||||||||||||||
| Location (UCSC) | Chr 1: 225.85 – 225.88 Mb | Chr 1: 180.94 – 180.98 Mb | |||||||||||||||||||||||
| PubMed search | [3] | [4] | |||||||||||||||||||||||
| Wikidata | |||||||||||||||||||||||||
| |||||||||||||||||||||||||


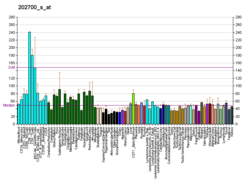
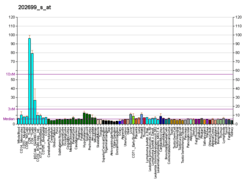
Transmembrane protein 63A is a protein that in humans is encoded by the TMEM63A gene.[5][6][7] The mature human protein is approximately 92.1 kilodaltons (kDa), with a relatively high conservation of mass in orthologs.[8] The protein contains eleven transmembrane domains and is inserted into the membrane of the lysosome.[9][10] BioGPS analysis for TMEM63A in humans shows that the gene is ubiquitously expressed, with the highest levels of expression found in T-cells and dendritic cells.[11]
Gene
Overview
TMEM63A is located on the negative DNA strand of chromosome 1 at location 1q42.12, spanning base pairs 226,033,237 to 226,070,069.[7] Aliases include KIAA0489 and KIAA0792. The human gene product is a 4,469 base pair mRNA with 25 predicted exons.[12] There are 9 predicted splice isoforms of the gene, three of which are protein coding. Promoter analysis was carried out using El Dorado[13] through the Genomatix software page. The predicted promoter region spans 971 base pairs, from 226,070,920 to 226,069,950 on the negative strand of chromosome 1.
Gene neighborhood
TMEM63A is located adjacent to the EPHX1 gene on the positive sense strand of DNA on chromosome 1, as well as the LEFTY1 gene on the negative sense strand.[7] Other genes in the same area on chromosome 1 include SRP9 and LEFTY3 on the positive strand, and MIR6741 and PYCR2 on the negative strand.
Expression
TMEM63 is ubiquitously expressed throughout the human body at varying levels, occurring with the highest relative prevalence in CD 8+ T cells and CD 4+ T cells.[11][14] Moderate relative levels of expression are also observed throughout the brain, particularly in the occipital lobe, parietal lobe, and pancreas.[14] Analysis of TMEM63A expression in the mouse using BioGPS revealed more variable expression patterns, with the highest expression being seen in the stomach and large intestine.[11] Using the El Dorado program from Genomatix, transcription factor regulation was predicted, which found that ‘’TMEM63A’’ is highly regulated by E2F cell cycle regulators and EGR1, a factor believed to be a tumor suppressor gene with expression in the brain.[13] The 3’ UTR is predicted to be bound by the regulatory element miR-9/9ab.[15]
Protein
Properties and characteristics
The mature form of the human TMEM63A protein has 807 amino acid residues with an isoelectric point of 6.925.[8] This is fairly conserved across orthologs. A BLAST alignment revealed that the protein contains three domains: RSN1_TM and two domains of unknown function (DUF4463 and DUF221).[16] RSN1_TM is predicted to be involved in Golgi vesicle transport and exocytosis. DUF4463 is cytosolic and distantly homologous to RNA-binding proteins. This domain can be used to determine the orientation of the protein in the membrane, with the N-terminus of the protein being within the lysosome and the C-terminus located in the cytosol.
Post-translational modification has been determined both experimentally and using bioinformatic analysis. There are two likely sites of glycosylation on the protein: N38 and N450.[17] These were predicted using the NetNGlyc program from ExPASy and the TMEM63A amino acid sequence, as well as the inferred orientation of the protein in the membrane.[18] There are three likely sites of phosphorylation on the protein: S85, S98, and S735, which were predicted using the NetPhos program.[19]
The protein has three isoforms. The mature protein is designated isoform CRA. The other two isoforms are X1 and X2, which are 630 amino acid residues and 468 amino acid residues long, respectively. Isoform X1 is missing the N-terminus of the mature protein, while isoform 2 is missing the C-terminus.[8]
Interactions
Using text-based information, TMEM63A is thought to potentially interact with six other proteins: EEF1D,[20] FAM163B, CPNE9, TMEM90A, STAC2, HEATR3, and WDR67.[21]
Function
The function of TMEM63A is not known, although one study found it was in a region likely regulated by mir-200a, linked to epithelial homeostasis.[22] Another found it to be in a quantitative trait locus linked to haloperidol-induced catalepsy.[23]
Evolutionary history
Paralogs
TMEM63A has two paralogs: TMEM63B, which is located at 6p21.1, and TMEM63C, which is located at C14orf171.[24] Alignment between them shows that TMEM63C is more closely related to TMEM63B than TMEM63A.[8] A BLAST alignment showed homology of TMEM63A and TMEM63B to proteins as distantly related as plants, while TMEM63C was homologous only as distantly as in drosophila.[16] This indicates that TMEM63C likely diverged from the two early in invertebrates.
Ortholog space
TMEM63A has a large ortholog space, with homologs present in organisms as distantly related as plants.
| Genus and species | Common name | Class | Accession | Percent identity |
|---|---|---|---|---|
| Otolemur garnettii | Bush baby | Mammalia | XP_003791028.1 | 91% |
| Vicugna pacos | Alpaca | Mammalia | XP_006198896.1 | 92% |
| Mus musculus | Mouse | Mammalia | NP_659043.1 | 90% |
| Trichechus manatus latirostris | West Indian manatee | Mammalia | XP_004375949.1 | 89% |
| Canis lupis familiaris | Dog | Mammalia | NP_001274088.1 | 89% |
| Myotis davidii | Mouse-eared bat | Mammalia | XP_006761379.1 | 80% |
| Pelodiscus sinensis | Chinese softshell turtle | Sauropsida | XP_006118107.1 | 71% |
| Alligator sinensis | Chinese alligator | Reptilia | XP_006016630.1 | 70% |
| Ficedula albicollis | Collared flycatcher | Aves | XP_005043078.1 | 69% |
| Gallus gallus | Red junglefowl | Aves | XP_419384.3 | 68% |
| Xenopus tropicalis | Western clawed frog | Amphibia | NP_001072343.1 | 65% |
| Ictalurus punctatus | Channel catfish | Actinopterygii | AHH42519.1 | 54% |
| Culex quinquefasciatus | Southern house mosquito | Insecta | XP_001861445.1 | 34% |
| Clonorchis sinensis | Chinese liver fluke | Trematoda | GAA53916.1 | 23% |
| Oryza sativa | Asian rice | Liliopsida | NP_001065504.1 | 20% |
References
- 1 2 3 GRCh38: Ensembl release 89: ENSG00000196187 - Ensembl, May 2017
- 1 2 3 GRCm38: Ensembl release 89: ENSMUSG00000026519 - Ensembl, May 2017
- ↑ "Human PubMed Reference:".
- ↑ "Mouse PubMed Reference:".
- ↑ Nagase T, Ishikawa K, Suyama M, Kikuno R, Miyajima N, Tanaka A, Kotani H, Nomura N, Ohara O (Apr 1999). "Prediction of the coding sequences of unidentified human genes. XI. The complete sequences of 100 new cDNA clones from brain which code for large proteins in vitro". DNA Res. 5 (5): 277–86. doi:10.1093/dnares/5.5.277. PMID 9872452.
- ↑ Seki N, Ohira M, Nagase T, Ishikawa K, Miyajima N, Nakajima D, Nomura N, Ohara O (Feb 1998). "Characterization of cDNA clones in size-fractionated cDNA libraries from human brain". DNA Res. 4 (5): 345–9. doi:10.1093/dnares/4.5.345. PMID 9455484.
- 1 2 3 "Entrez Gene: TMEM63A transmembrane protein 63A".
- 1 2 3 4 "TMEM63A Analysis". Biology Workbench. San Diego Supercomputing Center- University of California San Diego. Retrieved 8 May 2014.
- ↑ Schroder BA, Wrocklage C, Hasilik A, Saftig P (19 October 2010). "The Proteome of Lysosomes". Proteomics. 10 (22): 4053–4076. doi:10.1002/pmic.201000196. Retrieved 6 May 2014.
- ↑ Schroder BA, Wrocklage C, Pan C, Jager R, Kosters B, Schafer H, Elsasser HP, Mann M, Hasilik A (28 August 2007). "Integral and Associated Lysosomal Membrane Proteins". Traffic. 8 (12): 1676–1686. doi:10.1111/j.1600-0854.2007.00643.x. Retrieved 8 May 2014.
- 1 2 3 "BioGPS: TMEM63A". Retrieved 12 May 2014.
- ↑ "Ensembl: TMEM63A". Retrieved 8 May 2014.
- 1 2 "El Dorado". Genomatix. Retrieved 17 April 2014.
- 1 2 "GDS596/214833_at/TMEM63A". NCBI.
- ↑ "TargetScanHuman 6.2". Whitehead Institute for Biomedical Research. Retrieved 23 April 2014.
- 1 2 Marchler-Bauer A, et al. (2011). "CDD: A Conserved Domain Database for the functional annotation of proteins". Nucleic Acids Res. 39 (D): 225–229. doi:10.1093/nar/gkq1189. PMC 3013737. PMID 21109532.
- ↑ "O94886 (TM63A_HUMAN)". UniProtKB. Retrieved 5 May 2014.
- ↑ Gupta R, Jung E, Brunak S (2004). "Prediction of N-glycosylation sites in human proteins".
- ↑ Blorn N, Gammeltoft S, Brunak S (1999). "Sequence- and structure-based prediction of eukaryotic protein phosphorylation sites". Journal of Molecular Biology. 294 (5): 1351–1362. doi:10.1006/jmbi.1999.3310. PMID 10600390.
- ↑ "GeneCards". Weizmann Institute of Science. Retrieved 16 May 2014.
- ↑ "String Database". Retrieved 16 May 2014.
- ↑ Bonnet E, Tatari M, Joshi A, et al. (2010). "Module network inference from a cancer gene expression data set identifies microRNA regulated modules". PLoS ONE. 5 (4). doi:10.1371/journal.pone.0010162.
- ↑ Hofstetter JR, Hitzemann RJ, Belknap JK, Walter NA, McWeeney SK, Mayeda AR (2008). "Characterization of the quantitative trait locus for haloperidol-induced catalepsy on distal mouse chromosome 1". Genes Brain Behavior. 7: 214–223. doi:10.1111/j.1601-183x.2007.00340.x.
- ↑ Altschul SF, Gish W, Miller W, Myers EW, Lipman DJ (October 1990). "Basic local alignment search tool". J. Mol. Biol. 215 (3): 403–10. doi:10.1016/S0022-2836(05)80360-2. PMID 2231712.
Further reading
- Gregory SG, Barlow KF, McLay KE, et al. (2006). "The DNA sequence and biological annotation of human chromosome 1". Nature. 441 (7091): 315–21. doi:10.1038/nature04727. PMID 16710414.
- Gerhard DS, Wagner L, Feingold EA, et al. (2004). "The status, quality, and expansion of the NIH full-length cDNA project: the Mammalian Gene Collection (MGC)". Genome Res. 14 (10B): 2121–7. doi:10.1101/gr.2596504. PMC 528928. PMID 15489334.
- Ota T, Suzuki Y, Nishikawa T, et al. (2004). "Complete sequencing and characterization of 21,243 full-length human cDNAs". Nat. Genet. 36 (1): 40–5. doi:10.1038/ng1285. PMID 14702039.
- Strausberg RL, Feingold EA, Grouse LH, et al. (2003). "Generation and initial analysis of more than 15,000 full-length human and mouse cDNA sequences". Proc. Natl. Acad. Sci. U.S.A. 99 (26): 16899–903. doi:10.1073/pnas.242603899. PMC 139241. PMID 12477932.
- Suzuki Y, Yoshitomo-Nakagawa K, Maruyama K, et al. (1997). "Construction and characterization of a full length-enriched and a 5'-end-enriched cDNA library". Gene. 200 (1–2): 149–56. doi:10.1016/S0378-1119(97)00411-3. PMID 9373149.
- Maruyama K, Sugano S (1994). "Oligo-capping: a simple method to replace the cap structure of eukaryotic mRNAs with oligoribonucleotides". Gene. 138 (1–2): 171–4. doi:10.1016/0378-1119(94)90802-8. PMID 8125298.