SpaCy
|
| |
| Original author(s) | Matthew Honnibal |
|---|---|
| Developer(s) | Explosion AI, various |
| Initial release | February 2015[1] |
| Stable release |
2.0
/ 7 November 2017 |
| Repository |
github |
| Written in | Python, Cython |
| Operating system | Linux, Windows, macOS, OS X |
| Platform | cross-platform |
| Type | Natural language processing |
| License | MIT |
| Website |
spacy |
spaCy (/speɪˈsiː/ spay-SEE) is an open-source software library for advanced Natural Language Processing, written in the programming languages Python and Cython.[2][3] The library is published under the MIT license and currently offers statistical neural network models for English, German, Spanish, Portuguese, French, Italian, Dutch and multi-language NER, as well as tokenization for various other languages.[4]
Unlike NLTK, which is widely used for teaching and research, spaCy focuses on providing software for production usage.[5][6] As of version 1.0, spaCy also supports deep learning workflows[7] that allow connecting statistical models trained by popular machine learning libraries like TensorFlow, Keras, Scikit-learn or PyTorch.[8] spaCy's machine learning library, Thinc, is also available as a separate open-source Python library.[9] On November 7, 2017, version 2.0 was released.[10] It features convolutional neural network models for part-of-speech tagging, dependency parsing and named entity recognition, as well as API improvements around training and updating models, and constructing custom processing pipelines.
Main features
- Non-destructive tokenization
- Named entity recognition
- "Alpha tokenization" support for over 25 languages[11]
- Statistical models models for 8 languages[12]
- Pre-trained word vectors
- Part-of-speech tagging
- Labelled dependency parsing
- Syntax-driven sentence segmentation
- Text classification
- Built-in visualizers for syntax and named entities
- Deep learning integration
Extensions and visualizers
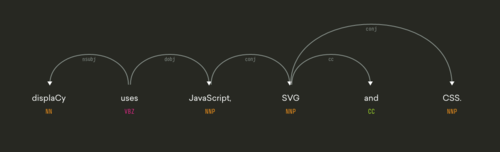
spaCy comes with several extensions and visualizations that are available as free, open-source libraries:
- Thinc: A machine learning library optimized for CPU usage and deep learning with text input.
- sense2vec: A library for computing word similarities, based on Word2vec and sense2vec.[13]
- displaCy: An open-source dependency parse tree visualizer built with JavaScript, CSS and SVG.
- displaCyENT: An open-source named entity visualizer built with JavaScript and CSS.
See also
References
- ↑ "Introducing spaCy". explosion.ai. Retrieved 2016-12-18.
- ↑ Choi et al. (2015). It Depends: Dependency Parser Comparison Using A Web-based Evaluation Tool.
- ↑ "Google's new artificial intelligence can't understand these sentences. Can you?". Washington Post. Retrieved 2016-12-18.
- ↑ "Models & Languages | spaCy Usage Documentation". spacy.io. Retrieved 2017-11-08.
- ↑ "Facts & Figures - spaCy". spacy.io. Retrieved 2017-11-08.
- ↑ Bird, Steven; Klein, Ewan; Loper, Edward; Baldridge, Jason (2008). "Multidisciplinary instruction with the Natural Language Toolkit" (PDF). Proceedings of the Third Workshop on Issues in Teaching Computational Linguistics, ACL.
- ↑ "explosion/spaCy". GitHub. Retrieved 2016-12-18.
- ↑ "Facts & Figures | spaCy Usage Documentation". spacy.io. Retrieved 2017-11-08.
- ↑ "explosion/thinc". GitHub. Retrieved 2016-12-30.
- ↑ spaCy: 💫 Industrial-strength Natural Language Processing (NLP) with Python and Cython, Explosion AI, 2017-11-08, retrieved 2017-11-08
- ↑ "Models & Languages - spaCy". spacy.io. Retrieved 2017-11-08.
- ↑ "Models & Languages | spaCy Usage Documentation". spacy.io. Retrieved 2017-11-08.
- ↑ Trask et al. (2015). sense2vec - A Fast and Accurate Method for Word Sense Disambiguation In Neural Word Embeddings.
External links
- Official website
- spaCy source code on GitHub
- Official blog by the creators
- spaCy author Matthew Honnibal on the origin of the name