Pan-genome
In molecular biology a pan-genome (or supra-genome) describes the full complement of genes in a clade (originally applied to species in bacteria and archaea, but also to plant species), which can have large variation in gene content among closely related strains or ecotypes. It is the union of the gene sets of all the strains of a clade (e.g. species).[1] The significance of the pan-genome arises in an evolutionary context, especially with relevance to metagenomics,[2] but is also used in a broader genomics context.[3] Plant studies have shown that pan-genome dynamics is linked to transposable elements.[4][5][6]
The pan-genome includes the "core genome" containing genes present in all individuals, an accessory or dispensable genome containing shell genes present in two or more strains, and finally unique cloud genes specific to single strains.[1][7] [8] Soft-core genes have also been found in most (95%) strains or ecotypes analyzed, leaving some room for assembly/annotation errors.[9]
These distinctions are not completely objective, since they depend on which genomes are included in the analysis. Moreover, the term "dispensable" has been questioned.[10]
There are two generalised types of pan-genomes, categorised by the number of new genes added to the pan-genome per sequenced genome. Species with a closed pan-genome would have very few genes added per sequenced genome after sequencing many strains, and the size of the full pan-genome could theoretically be predicted. Species with an open pan-genome have enough genes added per additional sequenced genome that predicting the size of the full pan-genome is not possible.[8] Population size and niche versatility have been suggested as the most influential factors in determining pan-genome size.[11]
Examples
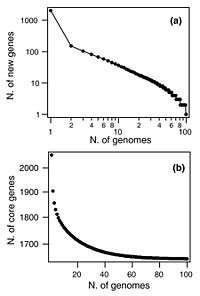
The original pan-genome concept was developed by Tettelin et al.[13] when they sequenced six strains of Streptococcus agalactiae which could be described as a core genome shared by all isolates, accounting for approximately 80% of any single genome, plus a dispensable genome consisting of partially shared and strain-specific genes. Extrapolation suggested that the gene reservoir in the S. agalactiae pan-genome is vast and that new unique genes will continue to be identified even after sequencing hundreds of genomes.[13]
A similar pattern was found in Streptococcus pneumoniae when 44 strains were sequenced (see figure). With each new genome sequenced fewer new genes were discovered. In fact, the predicted number of new genes dropped to zero when the number of genomes exceeds 50 (note, however, that this is not a pattern found in all species). The main source of new genes in S. pneumoniae was Streptococcus mitis from which genes were transferred horizontally. The pan-genome size of S. pneumoniae increased logarithmically with the number of strains and linearly with the number of polymorphic sites of the sampled genomes, suggesting that acquired genes accumulate proportionately to the age of clones.[12]
Another example for the latter can be seen in a comparison of the sizes of the core and the pan-genome of Prochlorococcus. The core genome set is logically much smaller than the pan-genome, which is used by different ecotypes of Prochlorococcus.[14] A 2015 study on Prevotella bacteria isolated from humans, compared the gene repertoires of its species derived from different body sites of human. It also reported an open pan- genome showing vast diversity of gene pool.[15]
Software tools
As interest in pan-genomes increased, there have been a number of software tools developed to help analyze this kind of data. In 2015, a group reviewed the different kinds of analyses and tools a researcher may have available.[16] There are seven kinds of analyses software developed to analyze pangenomes: cluster homologous genes; identify SNPs; plot pangenomic profiles; build phylogenetic relationships of orthologous genes/families of strains/isolates; function-based searching; annotation and/or curation; and visualizations.[16]
The two most cited software tools at the end of 2014[16] were Panseq[17] and the pan-genomes analysis pipeline (PGAP).[18] Other options include BPGA – A Pan-Genome Analysis Pipeline for prokaryotic genomes,[19] GET_HOMOLOGUES [20] or Roary.[21]
A similar review focused on plant pan-genomes was published also in 2015.[22] The first software designed for plant pan-genomes is GET_HOMOLOGUES-EST.[6]
See also
References
- 1 2 Medini, Duccio; Donati, Claudio; Tettelin, Hervé; Masignani, Vega; Rappuoli, Rino (2005). "The microbial pan-genome". Current Opinion in Genetics & Development. 15 (6): 589–594. doi:10.1016/j.gde.2005.09.006. PMID 16185861.
- ↑ Reno ML, Held NL, Fields CJ, Burke PV, Whitaker RJ (May 2009). "Biogeography of the Sulfolobus islandicus pan-genome". Proc. Natl. Acad. Sci. U.S.A. 106 (21): 8605–10. doi:10.1073/pnas.0808945106. PMC 2689034. PMID 19435847.
- ↑ Reinhardt JA, Baltrus DA, Nishimura MT, Jeck WR, Jones CD, Dangl JL (February 2009). "De novo assembly using low-coverage short read sequence data from the rice pathogen Pseudomonas syringae pv. oryzae". Genome Res. 19 (2): 294–305. doi:10.1101/gr.083311.108. PMC 2652211. PMID 19015323.
- ↑ Morgante M, De Paoli E, Radovic S (April 2007). "Transposable elements and the plant pan-genomes". Curr Opin Plant Biol. 10 (2): 149–155. doi:10.1016/j.pbi.2007.02.001. PMID 17300983.
- ↑ Gordon SP, Contreras-Moreira B, Woods DP, Des Marais DL, Burgess D, Shu S, Stritt C, Roulin AC, Schackwitz W, Tyler L, Martin J, Lipzen A, Dochy N, Phillips J, Barry K, Geuten K, Budak H, Juenger TE, Amasino R, Caicedo AL, Goodstein D, Davidson P, Mur LA, Figueroa M, Freeling M, Catalan P, Vogel JP (December 2017). "Extensive gene content variation in the Brachypodium distachyon pan-genome correlates with population structure". Nature Communications. 8 (1): 2184. doi:10.1038/s41467-017-02292-8. PMC 5736591. PMID 29259172.
- 1 2 Contreras-Moreira B, Cantalapiedra CP, García-Pereira MJ, Gordon SP, Vogel JP, Igartua E, Casas AM, Vinuesa P (February 2017). "Analysis of Plant Pan-Genomes and Transcriptomes with GET_HOMOLOGUES-EST, a Clustering Solution for Sequences of the Same Species". Front. Plant Sci. 8: 184. doi:10.3389/fpls.2017.00184. PMC 5306281. PMID 28261241.
- ↑ Wolf YI, Makarova KS, Yutin N, Koonin EV (December 2012). "Updated clusters of orthologous genes for Archaea: a complex ancestor of the Archaea and the byways of horizontal gene transfer". Biol Direct. 7: 46. doi:10.1186/1745-6150-7-46. PMC 3534625. PMID 23241446.
- 1 2 Vernikos, George; Medini, Duccio; Riley, David R; Tettelin, Hervé (2015). "Ten years of pan-genome analyses". Current Opinion in Microbiology. 23: 148–154. doi:10.1016/j.mib.2014.11.016.
- ↑ Kaas RS, Friis C, Ussery DW, Aarestrup FM (October 2012). "Estimating variation within the genes and inferring the phylogeny of 186 sequenced diverse Escherichia coli genomes". BMC Genomics. 13: 577. doi:10.1186/1471-2164-13-577. PMC 3575317. PMID 23114024.
- ↑ Marroni F, Pinosio S, Morgante M (April 2014). "Structural variation and genome complexity: is dispensable really dispensable?". Curr Opin Plant Biol. 18: 31–36. doi:10.1016/j.pbi.2014.01.003.
- ↑ McInerney, James O.; McNally, Alan; O'Connell, Mary J. (2017-03-28). "Why prokaryotes have pangenomes". Nature Microbiology. 2 (4). doi:10.1038/nmicrobiol.2017.40. ISSN 2058-5276.
- 1 2 Donati, C; Hiller, N. L.; Tettelin, H; Muzzi, A; Croucher, N. J.; Angiuoli, S. V.; Oggioni, M; Dunning Hotopp, J. C.; Hu, F. Z.; Riley, D. R.; Covacci, A; Mitchell, T. J.; Bentley, S. D.; Kilian, M; Ehrlich, G. D.; Rappuoli, R; Moxon, E. R.; Masignani, V (2010). "Structure and dynamics of the pan-genome of Streptococcus pneumoniae and closely related species". Genome Biology. 11 (10): R107. doi:10.1186/gb-2010-11-10-r107. PMC 3218663. PMID 21034474.
- 1 2 Tettelin, H; Masignani, V; Cieslewicz, M. J.; Donati, C; Medini, D; Ward, N. L.; Angiuoli, S. V.; Crabtree, J; Jones, A. L.; Durkin, A. S.; Deboy, R. T.; Davidsen, T. M.; Mora, M; Scarselli, M; Margarit y Ros, I; Peterson, J. D.; Hauser, C. R.; Sundaram, J. P.; Nelson, W. C.; Madupu, R; Brinkac, L. M.; Dodson, R. J.; Rosovitz, M. J.; Sullivan, S. A.; Daugherty, S. C.; Haft, D. H.; Selengut, J; Gwinn, M. L.; Zhou, L; et al. (2005). "Genome analysis of multiple pathogenic isolates of Streptococcus agalactiae: Implications for the microbial "pan-genome"". Proceedings of the National Academy of Sciences. 102 (39): 13950–5. doi:10.1073/pnas.0506758102. PMC 1216834. PMID 16172379.
- ↑ Kettler GC, Martiny AC, Huang K, Zucker J, Coleman ML, Rodrigue S, Chen F, Lapidus A, Ferriera S, Johnson J, Steglich C, Church GM, Richardson P, Chisholm SW (2007). "Patterns and Implications of Gene Gain and Loss in the Evolution of Prochlorococcus". PLoS Genetics. 3 (12): e231. doi:10.1371/journal.pgen.0030231. ISSN 1553-7390. PMC 2151091. PMID 18159947.
- ↑ Gupta VK, Chaudhari NM, Dutta C (2015). "Divergences in gene repertoire among the reference Prevotella genomes derived from distinct body sites of human". BMC Genomics. 16 (153). doi:10.1186/s12864-015-1350-6. PMC 4359502. PMID 25887946.
- 1 2 3 Xiao, Jingfa; Zhang, Zhewen; Wu, Jiayan; Yu, Jun (23 February 2015). "A brief review of software tools for pangenomics". Genomics, Proteomics & Bioinformatics. 13 (1): 73–76. doi:10.1016/j.gpb.2015.01.007. Retrieved 2017-01-28.
- ↑ Laing, Chad; Buchanan, Cody; Taboada, Eduardo; Zhang, Yongxiang; Kropinski, Andrew; Villegas, Andrea; Thomas, James; Gannon, Victor (15 September 2010). "Pan-genome sequence analysis using Panseq: an online tool for the rapid analysis of core and accessory genomic regions". BMC Bioinformatics. 11 (1): 461. doi:10.1186/1471-2105-11-461. Retrieved 2017-01-28.
- ↑ Zhao, Yongbing; Wu, Jiayan; Yang, Junhui; Sun, Shixiang; Xiao, Jingfa; Yu, Jun (29 November 2011). "PGAP: pan-genomes analysis pipeline". Bioinformatics. 28 (3): 416–418. doi:10.1093/bioinformatics/btr655. PMC 3268234. Retrieved 2017-01-28.
- ↑ Chaudhari NM, Gupta VK, Dutta C (2016). "BPGA- an ultra-fast pan-genome analysis pipeline". Scientific Reports. 6 (24373). doi:10.1038/srep24373. PMC 4829868. PMID 27071527.
- ↑ Contreras-Moreira B, Vinuesa P (October 2013). "GET_HOMOLOGUES, a versatile software package for scalable and robust microbial pangenome analysis". Appl Environ Microbiol. 79 (24): 7696–701. doi:10.1128/AEM.02411-13. PMC 3837814. PMID 24096415.
- ↑ Page AJ, Cummins CA, Hunt M, Wong VK, Reuter S, Holden MT, Fookes M, Falush D, Keane JA, Parkhill J (July 2015). "Roary: rapid large-scale prokaryote pan genome analysis". Bioinformatics. 31 (22): 3691–3693. doi:10.1093/bioinformatics/btv421. PMC 4817141. PMID 26198102.
- ↑ Golicz AA, Batley J, Edwards D (November 2015). "Towards plant pangenomics". Plant Biotechnol J. 14 (4): 1099–1105. doi:10.1111/pbi.12499. PMID 26593040.