Dependency inversion principle
| SOLID |
|---|
| Principles |
In object-oriented design, the dependency inversion principle refers to a specific form of decoupling software modules. When following this principle, the conventional dependency relationships established from high-level, policy-setting modules to low-level, dependency modules are reversed, thus rendering high-level modules independent of the low-level module implementation details. The principle states:[1]
- High-level modules should not depend on low-level modules. Both should depend on abstractions.
- Abstractions should not depend on details. Details should depend on abstractions.
By dictating that both high-level and low-level objects must depend on the same abstraction this design principle inverts the way some people may think about object-oriented programming.[2]
The idea behind points A and B of this principle is that when designing the interaction between a high-level module and a low-level one, the interaction should be thought of as an abstract interaction between them. This not only has implications on the design of the high-level module, but also on the low-level one: the low-level one should be designed with the interaction in mind and it may be necessary to change its usage interface.
In many cases, thinking about the interaction in itself as an abstract concept allows the coupling of the components to be reduced without introducing additional coding patterns, allowing only a lighter and less implementation dependent interaction schema.
When the discovered abstract interaction schema(s) between two modules is/are generic and generalization makes sense, this design principle also leads to the following dependency inversion coding pattern.
Traditional layers pattern
In conventional application architecture, lower-level components (e.g. Utility Layer) are designed to be consumed by higher-level components (e.g. Policy Layer) which enable increasingly complex systems to be built. In this composition, higher-level components depend directly upon lower-level components to achieve some task. This dependency upon lower-level components limits the reuse opportunities of the higher-level components.[1]
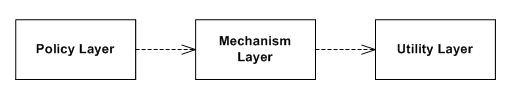
The goal of the dependency inversion pattern is to avoid this highly coupled distribution with the mediation of an abstract layer, and to increase the re-usability of higher/policy layers.
Dependency inversion pattern
With the addition of an abstract layer, both high- and lower-level layers reduce the traditional dependencies from top to bottom. Nevertheless, the "inversion" concept does not mean that lower-level layers depend on higher-level layers. Both layers should depend on abstractions that draw the behavior needed by higher-level layers.
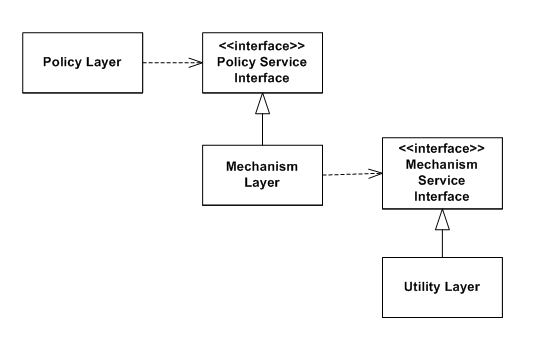
In a direct application of dependency inversion, the abstracts are owned by the upper/policy layers. This architecture groups the higher/policy components and the abstractions that define lower services together in the same package. The lower-level layers are created by inheritance/implementation of these abstract classes or interfaces.[1]
The inversion of the dependencies and ownership encourages the re-usability of the higher/policy layers. Upper layers could use other implementations of the lower services. When the lower-level layer components are closed or when the application requires the reuse of existing services, it is common that an Adapter mediates between the services and the abstractions.
Dependency inversion pattern generalization
In many projects the dependency inversion principle and pattern are considered as a single concept that should be generalized. There are at least two reasons for that:
- It is simpler to see a good thinking principle as a coding pattern. Once an abstract class or an interface has been coded, the programmer may say: "I have done the job of abstraction".
- Because many unit testing tools rely on inheritance to accomplish mocking, the usage of generic interfaces between classes (not only between modules when it makes sense to use generality) became the rule.
If the mocking tool used relies only on inheritance, generalizing the dependency inversion pattern may become a necessity. This has major drawbacks:
- Simply implementing an interface over a class isn't sufficient and generally does not reduce coupling, only thinking about the potential abstraction of interactions can lead to a less coupled design.
- Implementing generic interfaces everywhere in a project makes it by far harder to understand and maintain. At each step the reader will ask themself what are the other implementations of this interface and the response is generally: only mocks.
- The interface generalization requires more plumbing code, in particular factories that generally rely on a dependency-injection framework.
- Interface generalization also restricts the usage of the programming language.
Generalization restrictions
The presence of interfaces to accomplish the Dependency Inversion Pattern (DIP) have other design implications in an object-oriented program:
- All member variables in a class must be interfaces or abstracts.
- All concrete class packages must connect only through interface or abstract class packages.
- No class should derive from a concrete class.
- No method should override an implemented method.[1]
- All variable instantiation requires the implementation of a creational pattern such as the factory method or the factory pattern, or the use of a dependency-injection framework.
Interface mocking restrictions
Using inheritance-based mocking tools also introduce restrictions:
- Static externally visible members should systematically rely on dependency injection making them far harder to implement.
- All testable methods should become an interface implementation or an override of an abstract definition.
Future directions
Principles are ways of thinking, patterns are common ways to solve problems. Coding patterns may be seen as missing programming language features.
- Programming languages will continue to evolve to allow to enforce stronger and more precise usage contracts, in at least two directions: enforcing usage conditions (pre-, post- and invariant conditions), and state-based interfaces. This will probably encourage and potentially simplify a stronger application of the dependency inversion pattern in many situations.
- More and more mocking tools now use code injection to solve the problem of replacing static and non virtual members. Programming language will probably evolve to generate mocking-compatible bytecode. One direction will be to restrict the usage of non virtual members, the other one will be to generate, at least in test situations, a bytecode allowing non-inheritance based mocking.
Implementations
Two common implementations of DIP use similar logical architecture, with different implications.
A direct implementation packages the policy classes with service abstracts classes in one library. In this implementation high-level components and low-level components are distributed into separate packages/libraries, where the interfaces defining the behavior/services required by the high-level component are owned by, and exist within the high-level component's library. The implementation of the high-level component's interface by the low level component requires that the low-level component package depend upon the high-level component for compilation, thus inverting the conventional dependency relationship.
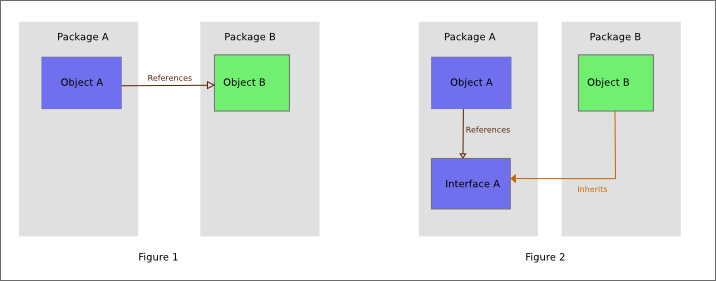
Figures 1 and 2 illustrate code with the same functionality, however in Figure 2, an interface has been used to invert the dependency. The direction of dependency can be chosen to maximize policy code reuse, and eliminate cyclic dependencies.
In this version of DIP, the lower layer component's dependency on the interfaces/abstracts in the higher-level layers makes re-utilization of the lower layer components difficult. This implementation instead ″inverts″ the traditional dependency from top-to-bottom to the opposite, from bottom-to-top.
A more flexible solution extracts the abstract components into an independent set of packages/libraries:
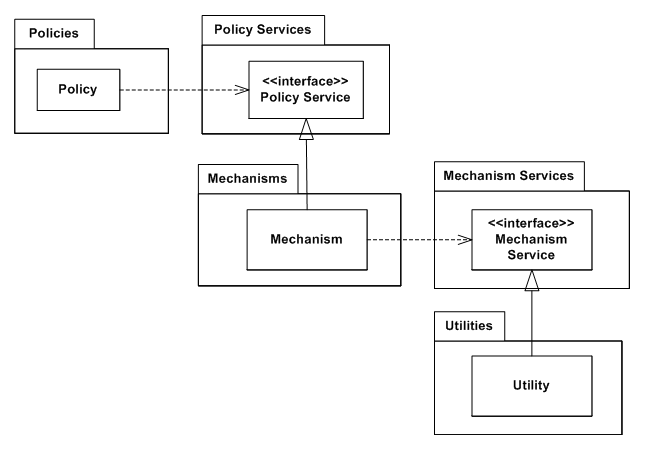
The separation of all layers into their own package encourages re-utilization of any layer, providing robustness and mobility.[1]
Examples
Genealogical module
A genealogical system may represent relationship between people as a graph of first level relationships between them (father/son, father/daughter, mother/son, mother/daughter, husband/wife, wife/husband...). This is very efficient (and extensible: ex-husband/ex-wife, legal guardian...)
But the high level modules may require a simpler way to browse the system: a person may have children, a father, a mother, brothers and sisters (including or not half brothers and sisters), grandfathers, grandmothers, uncles, aunts, cousins ...
Depending on the usage of the genealogical module, presenting common relationships as distinct direct properties (hiding the graph) will make the coupling between the high-level module and the genealogical module by far lighter and allow one to change the internal representation completely without any effect on the using modules. It also allows one to embed in the genealogical module the exact definition of brother and sisters (including or not half ones), uncles ... allowing one to enforce the single responsibility principle.
Finally, if the first extensible generalized graph approach seems the most extensible, the usage of the genealogical module may show that a more specialized and simpler relationship implementation is sufficient for the application(s) and helps you to make a more efficient system.
In this example abstracting the interaction between the modules leads to a simplified interface of the low-level module and may lead to a simpler implementation of it.
Remote file server client
Imagine you have to implement a client to a remote file server (FTP, cloud storage ...). You may think of it as a set of abstract interfaces:
- Connection/Disconnection (a connection persistence layer may be needed)
- Folder/tags creation/rename/delete/list interface
- File creation/replacement/rename/delete/read interface
- File searching
- Concurrent replacement or delete resolution
- File history management ...
If both local files and remote files offers the same abstract interfaces, any high-level module using local files and fully implementing the dependency inversion pattern will be able to access local and remote files indiscriminately.
Local disk will generally use folder, remote storage may use folder and/or tags. You have to decide how to unify them if possible.
On remote file we may have to use only create or replace: remote files update do not necessarily make sense because random update is too slow comparing local file random update and may be very complicated to implement). On remote file we may need partial read and write (at least inside the remote file module to allow download or upload to resume after a communication interruption), but random read isn't adapted (except if a local cache is used).
File searching may be pluggable : file searching can rely on the OS or in particular for tag or full text search, be implemented with distinct systems (OS embedded, or available separately).
Concurrent replacement or delete resolution detection may impact the other abstract interfaces.
When designing the remote file server client for each conceptual interface you have to ask yourself the level of service your high level modules require (not necessary all of them) and not only how to implement the remote file server functionalities but maybe how to make the file services in your application compatible between already implemented file services (local files, existing cloud clients) and your new remote file server client.
Once you have designed the abstract interfaces required, your remote file server client should implement these interfaces. And because you probably restricted some local functionalities existing on local file (for example file update), you may have to write adapters for local or other existing used remote file access modules each offering the same abstract interfaces. You also have to write your own file access enumerator allowing to retrieve all file compatible systems available and configured on your computer.
Once you do that, your application will be able to save its documents locally or remotely transparently. Or simpler, the high level module using the new file access interfaces can be used indistinctly in local or remote file access scenarios making it reusable.
Remark : many OSes have started to implement these kind of functionalities and your work may be limited to adapt your new client to this already abstracted models.
In this example, thinking of the module as a set of abstract interfaces, and adapting other modules to this set of interfaces, allows you to provide a common interface for many file storage systems.
Model View Controller
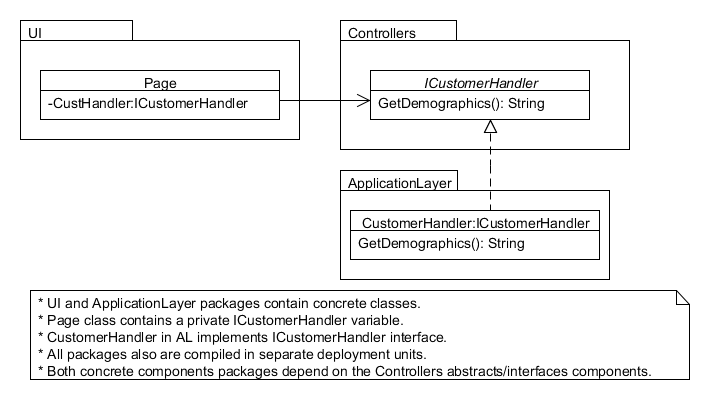
UI and ApplicationLayer packages contains mainly concrete classes. Controllers contains abstracts/interface types. UI has an instance of ICustomerHandler. All packages are physically separated. In the ApplicationLayer there is a concrete implementation that Page class will use. Instances of this interface are created dynamically by a Factory (possibly in the same Controllers package). The concrete types, Page and CustomerHandler, don't depend on each other; both depend on ICustomerHandler.
The direct effect is that the UI doesn't need to reference the ApplicationLayer or any concrete package that implements the ICustomerHandler. The concrete class will be loaded using reflection. At any moment the concrete implementation could be replaced by another concrete implementation without changing the UI class. Another interesting possibility is that the Page class implements an interface IPageViewer that could be passed as an argument to ICustomerHandler methods. Then the concrete implementation could communicate with UI without a concrete dependency. Again, both are linked by interfaces.
Related patterns
Applying the dependency inversion principle can also be seen as an example of the adapter pattern, i.e. the high-level class defines its own adapter interface which is the abstraction that the other high-level classes depend on. The adaptee implementation also depends on the adapter interface abstraction (of course, since it implements its interface) while it can be implemented by using code from within its own low-level module. The high-level has no dependency on the low-level module since it only uses the low-level indirectly through the adapter interface by invoking polymorphic methods to the interface which are implemented by the adaptee and its low-level module.
Various patterns such as Plugin, Service Locator, or Dependency Injection are employed to facilitate the run-time provisioning of the chosen low-level component implementation to the high-level component.
History
The dependency inversion principle was postulated by Robert C. Martin and described in several publications including the paper Object Oriented Design Quality Metrics: an analysis of dependencies,[3] an article appearing in the C++ Report in May 1996 entitled The Dependency Inversion Principle,[4] and the books Agile Software Development, Principles, Patterns, and Practices,[1] and Agile Principles, Patterns, and Practices in C#.
See also
- Adapter pattern
- Dependency injection
- Design by contract
- Interface
- Inversion of control
- Plug-in (computing)
- Service locator pattern
- SOLID – the "D" in "SOLID" stands for the dependency inversion principle
References
- 1 2 3 4 5 6 Martin, Robert C. (2003). Agile Software Development, Principles, Patterns, and Practices. Prentice Hall. pp. 127–131. ISBN 978-0135974445.
- ↑ Freeman, Eric; Freeman, Elisabeth; Kathy, Sierra; Bert, Bates (2004). Hendrickson, Mike; Loukides, Mike, eds. "Head First Design Patterns" (paperback). 1. O'REILLY. ISBN 978-0-596-00712-6. Retrieved 2012-06-21.
- ↑ Martin, Robert C. (October 1994). "Object Oriented Design Quality Metrics: An analysis of dependencies" (PDF). Retrieved 2016-10-15.
- ↑ Martin, Robert C. (May 1996). "The Dependency Inversion Principle" (PDF). C++ Report. Archived from the original (PDF) on 2011-07-14.
External links
- Object Oriented Design Quality Metrics: an analysis of dependencies Robert C. Martin, C++ Report, Sept/Oct 1995
- The Dependency Inversion Principle, Robert C. Martin, C++ Report, May 1996
- Examining the Dependency Inversion Principle, Derek Greer
- DIP in the Wild, Brett L. Schuchert, May 2013
- IoC Container for Unity3D – part 2