C11orf16
| C11orf16 | |||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Identifiers | |||||||||||||||||||||||||
| Aliases | C11orf16, chromosome 11 open reading frame 16 | ||||||||||||||||||||||||
| External IDs | MGI: 1928824 HomoloGene: 49631 GeneCards: C11orf16 | ||||||||||||||||||||||||
| |||||||||||||||||||||||||
| |||||||||||||||||||||||||
| |||||||||||||||||||||||||
| Orthologs | |||||||||||||||||||||||||
| Species | Human | Mouse | |||||||||||||||||||||||
| Entrez | |||||||||||||||||||||||||
| Ensembl | |||||||||||||||||||||||||
| UniProt | |||||||||||||||||||||||||
| RefSeq (mRNA) | |||||||||||||||||||||||||
| RefSeq (protein) | |||||||||||||||||||||||||
| Location (UCSC) | Chr 11: 8.92 – 8.93 Mb | Chr 7: 109.71 – 109.72 Mb | |||||||||||||||||||||||
| PubMed search | [3] | [4] | |||||||||||||||||||||||
| Wikidata | |||||||||||||||||||||||||
| |||||||||||||||||||||||||


Gene C11orf16, chromosome 11 open reading frame 16, is a protein in humans that is encoded by the C11orf16 gene.[5][6] It has 7 exons, and the size of 467 amino acids.
Gene
Location
The gene C11orf16 is located on chromosome 11(p15.4), starting at 8,920,076bp and ending at 8,933,006bp.
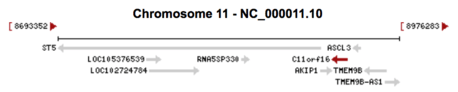
Gene Neighborhood
Gene ASCL3 and AKIP1 are the neighbor genes of C11orf16 on Chromosome 11.
Expression
Human
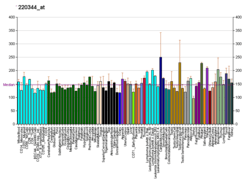
The gene does not have high expression throughout the body tissues. The percentile rank within the sample are higher in pancreas, ovary, and appendix.

Mouse Brain
Even though the gene does not have a significant high expression in the mouse brain, it is most expressed in midbrain, isocortex, olfactory areas, and medulla.
Transcription Factors
Some transcription factors that have the higher martix similarity are Kruppel-like zinc finger protein 219, Zinc finger protein 263, ZKSCAN12 (zinc finger protein with KRAB and SCAN domains 12), chorion-specific transcription factor GCMa, and Ras-responsive element binding protein 1.[7]
mRNA
Isoform
The predicted C11orf16 transcript variant X1 is 2386bp long and has NCBI accession number of XM_017018013.1.[8]
Homology
Paralogs
No paralogs were found for the C11orf16 gene through NCBI BLAST.
Orthologs
| Description | Common Name | NCBI accession ID | Query Cover | E value | Identity | Date of Divergent (MYA) |
|---|---|---|---|---|---|---|
| Homo sapiens | Human | NP_065694.2 | 100 % | 0 | 100% | N/A |
| Pongo abelii | Sumatran orangutan | PNJ24628 | 84% | 0 | 95% | 15.2 |
| Aotus nancymaae | Nancy Ma's night monkey | XP_012312127.1 | 88% | 0 | 84% | 42.6 |
| Chinchilla lanigera | Long-tailed chinchilla | XP_013367496.1 | 97% | 0 | 68% | 88 |
| Equus przewalskii | Przewalski's horse | XP_008512245.1 | 98% | 0 | 73% | 94 |
| Cervus elaphus hippelaphus | Central European red deer | OWK17675.1 | 99% | 0 | 67% | 94 |
| Hipposideros armiger | Great roundleaf bat | XP_019511755.1 | 99% | 0 | 65% | 94 |
| Neomonachus schauinslandi | Hawaiian monk seal | XP_021541375.1 | 99% | 0 | 66% | 94 |
| Lipotes vexillifer | Baiji | XP_007459933.1 | 98% | 0 | 68% | 94 |
| Myotis brandtii | Brandt's bat | XP_005874017.1 | 98% | 1e-174 | 67% | 94 |
| Chelonia mydas | Green sea turtle | XP_007057171.1 | 83% | 1e-57 | 37% | 320 |
| Balearica regulorum gibbericeps | Grey crowned crane | XP_010311948.1 | 70% | 6e-5 | 40% | 320 |
Conservation
The gene C11orf16 is conserved in many animal species including mammals, avians, and reptiles.

Protein
Molecular Weight
The predicted molecular weight of the protein encoded by C11orf16 is 51 kiloDaltons.[9][10]
Domains and Motifs
Several protein domains and motifs were found including CHD5-like protein, Tyrosine kinase phosphorylation site, Protein kinase C phosphorylation site, N-myristoylation site, Casein kinase II phosphorylation site, and cGMP-dependent protein kinase phosphorylation site.[11] The picture indicates the location of the motifs.
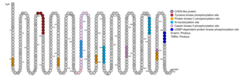
Secondary Structure
The protein is predicted to be made up with 21.2% of alpha helix, 15.2% of extended strand, and 63% of random coil.

Post-translational Modifications
No transmembrane helices[12], potential GPI-modification site, and TM-protein were found. There were 7 predicted sumoylation sites[13], multiple phosporylation cites with most of them being unsp[14], and 9 glycosylation cites[15].
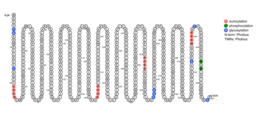
Subcellular Localization Predictor
The protein is predicted to be localized to the nucleus with the probability of 47.8%; mitochondria with the probability of 26.1%.[17]
Protein Interaction
Proteins C1orf105(Chromosome 1 open reading frame105 ), PWWP2A, and SMYD1(SET and MYND domain containing 1) were found to be interacting with C11orf16[18].
Clinical Significance
Disease Association
Protein coded by C11orf16 gene is also predicted to have 19.61% sequence identity to tumor suppressor p53-binding protein suggesting that this gene might be involved with tumor suppressing process[19].
References
- 1 2 3 GRCh38: Ensembl release 89: ENSG00000176029 - Ensembl, May 2017
- 1 2 3 GRCm38: Ensembl release 89: ENSMUSG00000031022 - Ensembl, May 2017
- ↑ "Human PubMed Reference:".
- ↑ "Mouse PubMed Reference:".
- ↑ Amid C, Bahr A, Mujica A, Sampson N, Bikar SE, Winterpacht A, Zabel B, Hankeln T, Schmidt ER (Aug 2001). "Comparative genomic sequencing reveals a strikingly similar architecture of a conserved syntenic region on human chromosome 11p15.3 (including gene ST5) and mouse chromosome 7". Cytogenet Cell Genet. 93 (3–4): 284–90. doi:10.1159/000056999. PMID 11528127.
- ↑ "Entrez Gene: C11orf16 chromosome 11 open reading frame 16".
- ↑ "Genomatix".
- ↑ "NCBI Nucleotide".
- ↑ "Expasy".
- ↑ "Sigma Antibodies".
- ↑ "Motif Scan".
- ↑ "TMHMM".
- ↑ "SUMOplot".
- ↑ "NetPhos".
- ↑ "YingOYang".
- ↑ "PROTTER".
- ↑ "PSORTII".
- ↑ "STRING".
- ↑ "SWISS-MODEL".
External links
- Human C11orf16 genome location and C11orf16 gene details page in the UCSC Genome Browser.
- C11orf16 information on GeneCards
Further reading
- Kimura K, Wakamatsu A, Suzuki Y, et al. (2006). "Diversification of transcriptional modulation: Large-scale identification and characterization of putative alternative promoters of human genes". Genome Res. 16 (1): 55–65. doi:10.1101/gr.4039406. PMC 1356129. PMID 16344560.
- Rual JF, Venkatesan K, Hao T, et al. (2005). "Towards a proteome-scale map of the human protein-protein interaction network". Nature. 437 (7062): 1173–8. doi:10.1038/nature04209. PMID 16189514.
- Bonaldo MF, Lennon G, Soares MB (1997). "Normalization and subtraction: two approaches to facilitate gene discovery". Genome Res. 6 (9): 791–806. doi:10.1101/gr.6.9.791. PMID 8889548.
- Maruyama K, Sugano S (1994). "Oligo-capping: a simple method to replace the cap structure of eukaryotic mRNAs with oligoribonucleotides". Gene. 138 (1–2): 171–4. doi:10.1016/0378-1119(94)90802-8. PMID 8125298.