Biological database

Biological databases are libraries of life sciences information, collected from scientific experiments, published literature, high-throughput experiment technology, and computational analysis.[2] They contain information from research areas including genomics, proteomics, metabolomics, microarray gene expression, and phylogenetics.[3] Information contained in biological databases includes gene function, structure, localization (both cellular and chromosomal), clinical effects of mutations as well as similarities of biological sequences and structures.
Biological databases can be broadly classified into sequence, structure and functional databases. Nucleic acid and protein sequences are stored in sequence databases and structure databases store solved structures of RNA and proteins. Functional databases provide information on the physiological role of gene products, for example enzyme activities, mutant phenotypes, or biological pathways. Model Organism Databases are functional databases that provide species-specific data. Databases are important tools in assisting scientists to analyze and explain a host of biological phenomena from the structure of biomolecules and their interaction, to the whole metabolism of organisms and to understanding the evolution of species. This knowledge helps facilitate the fight against diseases, assists in the development of medications, predicting certain genetic diseases and in discovering basic relationships among species in the history of life.
Biological knowledge is distributed among many different general and specialized databases. This sometimes makes it difficult to ensure the consistency of information. Integrative bioinformatics is one field attempting to tackle this problem by providing unified access. One solution is how biological databases cross-reference to other databases with accession numbers to link their related knowledge together.
Relational database concepts of computer science and Information retrieval concepts of digital libraries are important for understanding biological databases. Biological database design, development, and long-term management is a core area of the discipline of bioinformatics.[4] Data contents include gene sequences, textual descriptions, attributes and ontology classifications, citations, and tabular data. These are often described as semi-structured data, and can be represented as tables, key delimited records, and XML structures.
Types of Biological Databases

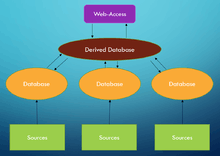
There are two common concepts of biological databases: Primary Databases and Secondary Databases. These two differ in their archive structure. Primary databases often hold only one type of specific data which is stored in their own archive. They upload new data explored in experiments and update entries to ensure the quality of the data.
Secondary databases are databases, which use other databases as their source of information, thus they get their data by requesting other databases. They often already process or analyze the data matching the corresponding request to get new results.
Nucleic Acids Research Database Issue
An important resource for finding biological databases is a special yearly issue of the journal Nucleic Acids Research (NAR). The Database Issue of NAR is freely available, and categorizes many of the publicly available on line databases related to biology and bioinformatics. A companion database to the issue called the Online Molecular Biology Database Collection lists 1,380 online databases.[5] Other collections of databases exist such as MetaBase and the Bioinformatics Links Collection.[6][7]
Access
Most biological databases are available through web sites that organise data such that users can browse through the data online. In addition the underlying data is usually available for download in a variety of formats. Biological data comes in many formats. These formats include text, sequence data, protein structure and links. Each of these can be found from certain sources, for example:
Species-specific databases
Species-specific databases are available for some species, mainly those that are often used in research (Model Organisms). For example, EcoCyc is an E. coli database. Other popular Model Organism Databases include Mouse Genome Informatics for the laboratory mouse, Mus musculus, the Rat Genome Database for Rattus, ZFIN for Danio Rerio (zebrafish), PomBase for the fission yeast Schizosaccharomyces pombe, FlyBase for Drosophila, WormBase for the nematodes Caenorhabditis elegans and Caenorhabditis briggsae, and Xenbase for Xenopus tropicalis and Xenopus laevis frogs.
See also
- Model Organism Databases
- Gene Disease Database
- Biobank
- Biological data
- Chemical database
- European Bioinformatics Institute
- Integrative bioinformatics
- List of biological databases
- MetaBase (a database of biological databases)
- NCBI
- PubMed (a database of biomedical literature)
- Death Domain database
References
- ↑ Szklarczyk D; Franceschini A; Kuhn M; et al. (January 2011). "The STRING database in 2011: functional interaction networks of proteins, globally integrated and scored". Nucleic Acids Res. 39 (Database issue): D561–8. doi:10.1093/nar/gkq973. PMC 3013807. PMID 21045058.
- ↑ Attwood T.K., Gisel A.; Eriksson N-E. & Bongcam-Rudloff E. (2011). "Concepts, Historical Milestones and the Central Place of Bioinformatics in Modern Biology: A European Perspective". Bioinformatics - Trends and Methodologies. InTech. Retrieved 8 Jan 2012.
- ↑ Altman RB (March 2004). "Building successful biological databases". Brief. Bioinformatics. 5 (1): 4–5. doi:10.1093/bib/5.1.4. PMID 15153301.
- ↑ Bourne P (August 2005). "Will a biological database be different from a biological journal?". PLoS Comput. Biol. 1 (3): 179–81. doi:10.1371/journal.pcbi.0010034. PMC 1193993. PMID 16158097.
- ↑ Galperin MY; Fernández-Suárez XM (January 2012). "The 2012 Nucleic Acids Research Database Issue and the online Molecular Biology Database Collection". Nucleic Acids Res. 40 (Database issue): D1–8. doi:10.1093/nar/gkr1196. PMC 3245068. PMID 22144685.
- ↑ Bolser DM; Chibon PY; Palopoli N; et al. (January 2012). "MetaBase--the wiki-database of biological databases". Nucleic Acids Res. 40 (Database issue): D1250–4. doi:10.1093/nar/gkr1099. PMC 3245051. PMID 22139927.
- ↑ Brazas MD; Yim DS; Yamada JT; Ouellette BF (July 2011). "The 2011 Bioinformatics Links Directory update: more resources, tools and databases and features to empower the bioinformatics community". Nucleic Acids Res. 39 (Web Server issue): W3–7. doi:10.1093/nar/gkr514. PMC 3125814. PMID 21715385.
External links
- Interactive list of biological databases, classified by categories, from Nucleic Acids Research, 2010
- DBD: Database of Biological Databases
- Lecture notes for Databases in bioinformatics course
- Biosharing (a database of biological databases)