bfloat16 floating-point format
| Floating-point formats |
|---|
| IEEE 754 |
| Other |
The bfloat16 floating-point format is a computer number format occupying 16 bits in computer memory; it represents a wide dynamic range of numeric values by using a floating radix point. This format is a truncated (16-bit) version of the 32-bit IEEE 754 single-precision floating-point format (binary32) with the intent of accelerating machine learning. It preserves the approximate dynamic range of 32-bit floating-point numbers by retaining 8 exponent bits, but supports only a 8-bit precision rather than the 24-bit significand of the binary32 format. More so than single-precision 32-bit floating-point numbers, bfloat16 numbers are unsuitable for integer calculations, but this is not their intended use.
The bfloat16 format is utilized in upcoming Intel AI processors, such as Nervana NNP-L1000, Xeon processors, and Intel FPGAs,[1][2][3] Google Cloud TPUs,[4][5][6] and TensorFlow.[6][7]
bfloat16 floating-point format
bfloat16 has the following format:
- Sign bit: 1 bit
- Exponent width: 8 bits
- Significand precision: 8 bits (7 explicitly stored), as opposed to 24 bits in a classical single-precision floating-point format
The bfloat16 format, being a truncated IEEE 754 single-precision 32-bit float, allows for fast conversion to and from an IEEE 754 single-precision 32-bit float, and preserves the exponent bits while reducing the significand. Preserving the exponent bits maintains the 32-bit float's range of ~1e-38 to ~3e38.[8]
The bits are laid out as follows:

Contrast to a IEEE 754 single-precision 32-bit float:
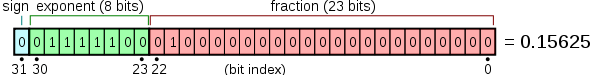
Exponent encoding
The bfloat16 binary floating-point exponent is encoded using an offset-binary representation, with the zero offset being 127; also known as exponent bias in the IEEE 754 standard.
- Emin = 01H−7FH = −126
- Emax = FEH−7FH = 127
- Exponent bias = 7FH = 127
Thus, in order to get the true exponent as defined by the offset-binary representation, the offset of 127 has to be subtracted from the value of the exponent field.
The minimum and maximum values of the exponent field (00H and FFH) are interpreted specially, like in the IEEE 754 standard formats.
| Exponent | Significand zero | Significand non-zero | Equation |
|---|---|---|---|
| 00H | zero, −0 | subnormal numbers | (−1)signbit×2−126× 0.significandbits |
| 01H, ..., FEH | normalized value | (−1)signbit×2exponentbits−127× 1.significandbits | |
| FFH | ±infinity | NaN (quiet, signaling) | |
The minimum positive normal value is 2−126 ≈ 1.18 × 10−38 and the minimum positive (subnormal) value is 2−126−7 = 2−133 ≈ 9.2 × 10−41.
Encoding of special values
Positive and negative infinity
Just as in IEEE 754, positive and negative infinity are represented with their corresponding sign bits, all 8 exponent bits set (FFhex) and all significand bits zero. Explicitly,
val s_exponent_signcnd
+inf = 0_11111111_0000000
-inf = 1_11111111_0000000
NaN
Just as in IEEE 754, NaN values are represented with either sign bit, all 8 exponent bits set (FFhex) and not all significand bits zero. Explicitly,
val s_exponent_signcnd
+NaN = 0_11111111_klmnopq
-NaN = 1_11111111_klmonpq
where at least one of k, l, m, n, o, p, or q is 1. As with IEEE 754, NaN values can be quiet or signaling, although there are no known uses of signaling bfloat16 NaNs as of September 2018.
Examples
These examples are given in bit representation, in hexadecimal and binary, of the floating-point value. This includes the sign, (biased) exponent, and significand.
3f80 = 0 01111111 0000000 = 1 c000 = 1 10000000 0000000 = −2
7f7f = 0 11111110 1111111 = (28 − 1) × 2−7 × 2127 ≈ 3.38953139 × 1038 (max finite positive value in bfloat16 precision) 0080 = 0 00000001 0000000 = 2−126 ≈ 1.175494351 × 10−38 (min normalized positive value in bfloat16 precision and single-precision floating point)
The maximum positive finite value of a normal bfloat16 number is 3.38953139 × 1038, slightly below (224 − 1) × 2−23 × 2127 = 3.402823466 × 1038, the max finite positive value representable in single precision.
Zeros and infinities
0000 = 0 00000000 0000000 = 0 8000 = 1 00000000 0000000 = −0
7f80 = 0 11111111 0000000 = infinity ff80 = 1 11111111 0000000 = −infinity
Special values
4049 = 0 10000000 1001001 = 3.1415927410 ≈ π ( pi ) 3eaa = 0 01111101 0101010 ≈ 1/3
NaNs
ffc0 0001 = x 11111111 1000001 => qNaN (on x86 and ARM processors) ff80 0001 = x 11111111 0000001 => sNaN (on x86 and ARM processors)
See also
- Half-precision floating-point format: 16-bit float w/ 1-bit sign, 5-bit exponent, and 11-bit significand, as defined by IEEE 754
- ISO/IEC 10967, Language Independent Arithmetic
- Primitive data type
- Minifloat
References
- ↑ Khari Johnson (2018-05-23). "Intel unveils Nervana Neural Net L-1000 for accelerated AI training". VentureBeat. Retrieved 2018-05-23.
...Intel will be extending bfloat16 support across our AI product lines, including Intel Xeon processors and Intel FPGAs.
- ↑ Michael Feldman (2018-05-23). "Intel Lays Out New Roadmap for AI Portfolio". TOP500 Supercomputer Sites. Retrieved 2018-05-23.
Intel plans to support this format across all their AI products, including the Xeon and FPGA lines
- ↑ Lucian Armasu (2018-05-23). "Intel To Launch Spring Crest, Its First Neural Network Processor, In 2019". Tom's Hardware. Retrieved 2018-05-23.
Intel said that the NNP-L1000 would also support bfloat16, a numerical format that’s being adopted by all the ML industry players for neural networks. The company will also support bfloat16 in its FPGAs, Xeons, and other ML products. The Nervana NNP-L1000 is scheduled for release in 2019.
- ↑ "Available TensorFlow Ops | Cloud TPU | Google Cloud". Google Cloud. Retrieved 2018-05-23.
This page lists the TensorFlow Python APIs and graph operators available on Cloud TPU.
- ↑ Elmar Haußmann (2018-04-26). "Comparing Google's TPUv2 against Nvidia's V100 on ResNet-50". RiseML Blog. Retrieved 2018-05-23.
For the Cloud TPU, Google recommended we use the bfloat16 implementation from the official TPU repository with TensorFlow 1.7.0. Both the TPU and GPU implementations make use of mixed-precision computation on the respective architecture and store most tensors with half-precision.
- 1 2 Tensorflow Authors (2018-02-28). "ResNet-50 using BFloat16 on TPU". Google. Retrieved 2018-05-23.
- ↑ Joshua V. Dillon, Ian Langmore, Dustin Tran, Eugene Brevdo, Srinivas Vasudevan, Dave Moore, Brian Patton, Alex Alemi, Matt Hoffman, Rif A. Saurous (2017-11-28). TensorFlow Distributions (Report). arXiv:1711.10604. Bibcode:2017arXiv171110604D. Accessed 2018-05-23.
All operations in TensorFlow Distributions are numerically stable across half, single, and double floating-point precisions (as TensorFlow dtypes: tf.bfloat16 (truncated floating point), tf.float16, tf.float32, tf.float64). Class constructors have a validate_args flag for numerical asserts
- ↑ "Livestream Day 1: Stage 8 (Google I/O '18) - YouTube". Google. 2018-05-08. Retrieved 2018-05-23.
In many models this is a drop-in replacement for float-32