Adversarial machine learning
Adversarial machine learning is a research field that lies at the intersection of machine learning and computer security. It aims to enable the safe adoption of machine learning techniques in adversarial settings, such as spam filtering, malware detection, and biometric recognition.
Analysis
Machine learning techniques were originally designed for stationary environments in which the training and test data are assumed to be generated from the same (although possibly unknown) distribution. In the presence of intelligent and adaptive adversaries, however, this working hypothesis is likely to be violated to at least some degree (depending on the adversary). In fact, a malicious adversary can carefully manipulate the input data, exploiting specific vulnerabilities of learning algorithms to compromise the whole system security.
Examples
Examples include attacks in spam filtering, where spam messages are obfuscated through misspelling of "bad" words or insertion of "good" words;[1][2] attacks in computer security to, for instance, obfuscate malware code within network packets or mislead signature detection; attacks in biometric recognition, where fake biometric traits may be exploited to impersonate a legitimate user[3] or to compromise users' template galleries that are adaptively updated over time.
In 2017, researchers at the Massachusetts Institute of Technology 3-D printed a toy turtle with a texture engineered to make Google's object detection AI classify it as a rifle, no matter the angle the turtle was viewed from.[4] Creating the turtle required only low-cost commercially available 3-D printing technology.[5] In 2018, Google Brain published a machine-tweaked image of a dog that looked like a cat both to computers and to humans.[6]
Security evaluation
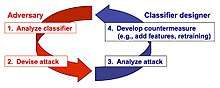
To understand the security properties of learning algorithms in adversarial settings, one should address the following main issues:[7][8][9][10]
- identifying potential vulnerabilities of machine learning algorithms during learning and classification;
- devising appropriate attacks that correspond to the identified threats and evaluating their impact on the targeted system;
- proposing countermeasures to improve the security of machine learning algorithms against the considered attacks.
This process amounts to simulating a proactive arms race (instead of a reactive one, as depicted in Figures 1 and 2), where system designers try to anticipate the adversary in order to understand whether there are potential vulnerabilities that should be fixed in advance; for instance, by means of specific countermeasures such as additional features or different learning algorithms. However proactive approaches are not necessarily superior to reactive ones. For instance, is was shown that under some circumstances, reactive approaches are more suitable for improving system security.[11]

Attacks against machine learning algorithms (supervised)
The first step of the above-sketched arms race is identifying potential attacks against machine learning algorithms. A substantial amount of work has been done in this direction.[7][8][9][12]
A taxonomy of potential attacks against machine learning
Attacks against (supervised) machine learning algorithms have been categorized along three primary axes:[12] their influence on the classifier, the security violation they cause, and their specificity.
- Attack influence. It can be causative, if the attack aims to introduce vulnerabilities (to be exploited at classification phase) by manipulating training data; or exploratory, if the attack aims to find and subsequently exploit vulnerabilities at classification phase.
- Security violation. It can be an integrity violation, if it aims to get malicious samples misclassified as legitimate; or an availability violation, if the goal is to increase the misclassification rate of legitimate samples, making the classifier unusable (e.g., a denial of service).
- Attack specificity. It can be targeted, if specific samples are considered (e.g., the adversary aims to allow a specific intrusion or he/she wants a given spam email to get past the filter); or indiscriminate.
This taxonomy has been extended into a more comprehensive threat model that allows one to make explicit assumptions on the adversary's goal, knowledge of the attacked system, capability of manipulating the input data and/or the system components, and on the corresponding (potentially, formally-defined) attack strategy. Details can be found here.[7][8] Two of the main attack scenarios identified according to this threat model are sketched below.
Evasion attacks
Evasion attacks[7][8][13] are the most prevalent type of attack that may be encountered in adversarial settings during system operation. For instance, spammers and hackers often attempt to evade detection by obfuscating the content of spam emails and malware code. In the evasion setting, malicious samples are modified at test time to evade detection; that is, to be misclassified as legitimate. No influence over the training data is assumed. A clear example of evasion is image-based spam in which the spam content is embedded within an attached image to evade the textual analysis performed by anti-spam filters. Another example of evasion is given by spoofing attacks against biometric verification systems.[3]
Poisoning attacks
Machine learning algorithms are often re-trained on data collected during operation to adapt to changes in the underlying data distribution. For instance, intrusion detection systems (IDSs) are often re-trained on a set of samples collected during network operation. Within this scenario, an attacker may poison the training data by injecting carefully designed samples to eventually compromise the whole learning process. Poisoning may thus be regarded as an adversarial contamination of the training data. Examples of poisoning attacks against machine learning algorithms (including learning in the presence of worst-case adversarial label flips in the training data) can be found in.[7][8][12][14][15]
Attacks against clustering algorithms
Clustering algorithms have been increasingly adopted in security applications to find dangerous or illicit activities. For instance, clustering of malware and computer viruses aims to identify and categorize different existing malware families, and to generate specific signatures for their detection by anti-viruses, or signature-based intrusion detection systems like Snort. However, clustering algorithms have not been originally devised to deal with deliberate attack attempts that are designed to subvert the clustering process itself. Whether clustering can be safely adopted in such settings thus remains questionable. Preliminary work reporting some vulnerability of clustering can be found in.[16]
Secure learning in adversarial settings
A number of defense mechanisms against evasion, poisoning and privacy attacks have been proposed in the field of adversarial machine learning, including:
- The definition of secure learning algorithms;[2][17][18]
- The use of multiple classifier systems;[1][19]
- The study of privacy-preserving learning.[8][20]
- Ladder algorithm for Kaggle-style competitions.
- Game theoretic models for adversarial machine learning and data mining.[21]
- Sanitizing training data from adversarial poisoning attacks.
Software
Some software libraries are available, mainly for testing purposes and research.
- AdversariaLib (includes implementation of evasion attacks from).
- AdLib. A python library with a scikit-style interface which includes implementations of a number of published evasion attacks and defenses.
- AlfaSVMLib. Adversarial Label Flip Attacks against Support Vector Machines.[22]
- Poisoning Attacks against Support Vector Machines, and Attacks against Clustering Algorithms
- deep-pwning Metasploit for deep learning which currently has attacks on deep neural networks using Tensorflow[23]
- Cleverhans A Tensorflow Library to test existing deep learning models versus known attacks
Past events
- NIPS 2007 Workshop on Machine Learning in Adversarial Environments for Computer Security
- Special Issue on "Machine Learning in Adversarial Environments" in the journal of Machine Learning
- Dagsthul Perspectives Workshop on "Machine Learning Methods for Computer Security"[24]
- Workshop on Artificial Intelligence and Security, (AISec) Series
See also
References
- 1 2 B. Biggio, G. Fumera, and F. Roli. "Multiple classifier systems for robust classifier design in adversarial environments". International Journal of Machine Learning and Cybernetics, 1(1):27–41, 2010.
- 1 2 M. Bruckner, C. Kanzow, and T. Scheffer. "Static prediction games for adversarial learning problems". J. Mach. Learn. Res., 13:2617–2654, 2012.
- 1 2 R. N. Rodrigues, L. L. Ling, and V. Govindaraju. "Robustness of multimodal biometric fusion methods against spoof attacks". J. Vis. Lang. Comput., 20(3):169–179, 2009.
- ↑ "Single pixel change fools AI programs". BBC News. 3 November 2017. Retrieved 12 February 2018.
- ↑ Athalye, A., & Sutskever, I. (2017). Synthesizing robust adversarial examples. arXiv preprint arXiv:1707.07397.
- ↑ "AI Has a Hallucination Problem That's Proving Tough to Fix". WIRED. 2018. Retrieved 10 March 2018.
- 1 2 3 4 5 6 7 B. Biggio, G. Fumera, and F. Roli. "Security evaluation of pattern classifiers under attack". IEEE Transactions on Knowledge and Data Engineering, 26(4):984–996, 2014.
- 1 2 3 4 5 6 7 8 B. Biggio, I. Corona, B. Nelson, B. Rubinstein, D. Maiorca, G. Fumera, G. Giacinto, and F. Roli. "Security evaluation of support vector machines in adversarial environments". In Y. Ma and G. Guo, editors, Support Vector Machines Applications, pp. 105–153. Springer, 2014.
- 1 2 3 4 B. Biggio, G. Fumera, and F. Roli. "Pattern recognition systems under attack: Design issues and research challenges". Int'l J. Patt. Recogn. Artif. Intell., 28(7):1460002, 2014.
- ↑ L. Huang, A. D. Joseph, B. Nelson, B. Rubinstein, and J. D. Tygar. "Adversarial machine learning". In 4th ACM Workshop on Artificial Intelligence and Security (AISec 2011), pages 43–57, Chicago, IL, USA, October 2011.
- ↑ A. Barth, B. I. P. Rubinstein, M. Sundararajan, J. C. Mitchell, D. Song, and P. L. Bartlett. "A learning-based approach to reactive security. IEEE Transactions on Dependable and Secure Computing", 9(4):482–493, 2012.
- 1 2 3 M. Barreno, B. Nelson, A. Joseph, and J. Tygar. "The security of machine learning". Machine Learning, 81:121–148, 2010
- ↑ B. Nelson, B. I. Rubinstein, L. Huang, A. D. Joseph, S. J. Lee, S. Rao, and J. D. Tygar. "Query strategies for evading convex-inducing classifiers". J. Mach. Learn. Res., 13:1293–1332, 2012
- ↑ B. Biggio, B. Nelson, and P. Laskov. "Support vector machines under adversarial label noise". In Journal of Machine Learning Research - Proc. 3rd Asian Conf. Machine Learning, volume 20, pp. 97–112, 2011.
- ↑ M. Kloft and P. Laskov. "Security analysis of online centroid anomaly detection". Journal of Machine Learning Research, 13:3647–3690, 2012.
- ↑ D. B. Skillicorn. "Adversarial knowledge discovery". IEEE Intelligent Systems, 24:54–61, 2009.
- ↑ O. Dekel, O. Shamir, and L. Xiao. "Learning to classify with missing and corrupted features". Machine Learning, 81:149–178, 2010.
- ↑ W. Liu and S. Chawla. "Mining adversarial patterns via regularized loss minimization". Machine Learning, 81(1):69–83, 2010.
- ↑ B. Biggio, G. Fumera, and F. Roli. "Evade hard multiple classifier systems". In O. Okun and G. Valentini, editors, Supervised and Unsupervised Ensemble Methods and Their Applications, volume 245 of Studies in Computational Intelligence, pages 15–38. Springer Berlin / Heidelberg, 2009.
- ↑ B. I. P. Rubinstein, P. L. Bartlett, L. Huang, and N. Taft. "Learning in a large function space: Privacy- preserving mechanisms for svm learning". Journal of Privacy and Confidentiality, 4(1):65–100, 2012.
- ↑ M. Kantarcioglu, B. Xi, C. Clifton. "Classifier Evaluation and Attribute Selection against Active Adversaries". Data Min. Knowl. Discov., 22:291–335, January 2011.
- ↑ H. Xiao, B. Biggio, B. Nelson, H. Xiao, C. Eckert, and F. Roli. "Support vector machines under adversarial label contamination". Neurocomputing, Special Issue on Advances in Learning with Label Noise, In Press.
- ↑ "cchio/deep-pwning". GitHub. Retrieved 2016-08-08.
- ↑ A. D. Joseph, P. Laskov, F. Roli, J. D. Tygar, and B. Nelson. "Machine Learning Methods for Computer Security" (Dagstuhl Perspectives Workshop 12371). Dagstuhl Manifestos, 3(1):1–30, 2013.