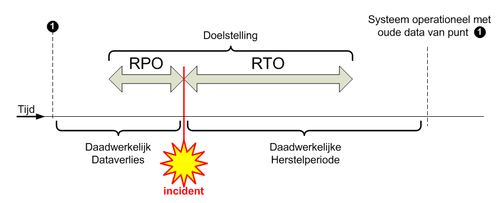
Recovery Point Objective
Recovery Point Objective (RPO) betekent herstelpuntdoelstelling en is een begrip uit de wereld van de informatietechnologie. RPO is het streven om te voldoen aan de afgesproken maximaal toelaatbare hoeveelheid dataverlies na een computercrash, door de afdeling ICT en/of een ICT-dienstverlener. RPO is verwant aan RTO, beide zijn tijdsintervallen.
Haalbare waarden
Zero RPO
Een RPO van nul in een End-to-end keten is niet haalbaar.[1]
Minimaal haalbare waarden
Verstoringen binnen een computernetwerk leiden altijd tot gegevensverlies. Onderstaande tabel geeft een globaal overzicht van de dienstverleningscijfers die in veel 'SLA's' worden afgesproken.
| Item | Voldoende kostenfactor 0,5 |
Ruim voldoende kostenfactor 1 |
Goed kostenfactor 10* |
Zeer goed kostenfactor 100* |
Uitmuntend kostenfactor 1000* |
| Openstelling informatievoorziening | 05:00–03:00 | 7×24 | 7×24 | 7×24 | 7×24 |
| Geplande downtime | ≤ 5× / jaar | ≤ 3 weekend / jaar | ≤ 1 weekend / jaar | ≤ 1 zon-, feestdag / jaar | geen |
| Openstellingtijd servicedesk | 08:30-17:00 | 7×24 | 7×24 | 7×24 | 7×24 |
| Herstelvenster incidenten | 5× (08:30-17:00) | 7× (08:00-18:00) | 7×24 | 7×24 | 7×24 |
| dataverlies (RPO) | ≤ 2 uur | ≤ 1 uur | ≤ 30 min | ≤ 15 min | ≤ 1 min |
| Ongeplande downtime volledige ICT-infrastructuur (RTO) | ≤ 16 uur | ≤ 8 uur | ≤ 6 uur | ≤ 4 uur | ≤ 3 uur |
| Specifieke afspraak voor "applicatie X" (RTO App. X) | ≤ 8 uur (H) | ≤ 2 uur (H) | ≤ 30 sec (A) | 0(A) | 0(A) |
| Beschikbaarheid ICT-infrastructuur | 99,85% | 99,90% | 99,95% | 99,97% | 99,98% |
(H) Handmatig a.d.h.v. uitgewerkte procedures
(A) Automatisch
* vermeerderde kostenfactoren worden voor 50% bepaald door apparatuur- en licentiekosten en voor de overige 50% door manuren voor intensief testen en het uitwerken van noodprocedures.
Complicerende factoren
Gedistribueerde business logic
In de jaren 60 en 70 van de 20ste eeuw werd voor de zakelijke markt gebruikgemaakt van mainframe- en midrangecomputers (toen minicomputer genoemd). Alle dataverwerking was gecentraliseerd in één computer en de gebruiker werkte op een ‘domme’ terminal (ASCII-terminal). Programma’s werden geschreven in COBOL, Pascal, Fortran en C. Juist vanwege het niet-gedistribueerde karakter leidde dit (min of meer verplicht) tot bundeling van database, bedrijfslogica en gebruikersinterface in één machine. Moderne applicaties zijn gedistribueerd over een veelheid van systemen en samengesteld uit verscheidene platformen, producten en technologieën. Dit maakt het in de praktijk moeilijk om de bedrijfslogica op één plek te houden. Deze onbedoelde wildgroei wordt ook versterkt doordat applicaties worden doorontwikkeld over langere perioden, waarbij het inzicht ten aanzien van de softwarearchitectuur steeds weer wijzigt. Hierdoor komt (onbedoeld) de businesslogica op meerdere plaatsen in de keten terecht, op zowel de presentatie- als op de applicatie- en de databaselaag (als respectievelijk JavaScript, calculatiecode of 'stored procedure'), waardoor er steeds meer 'constraints' ontstaan om de database consistent te houden. Ook transacties krijgen een gedistribueerd karakter en daardoor een langere weg af te leggen over meerdere fysieke systemen. Het maken van een ‘momentopname’ (snapshot) wordt lastig (zo niet onmogelijk), simpelweg omdat het niet mogelijk is om van de gehele keten een gelijktijdige snapshot te maken. In theorie zou dit probleem verholpen kunnen worden door de volledige applicatieketen in één (virtuele) machine te draaien, maar dat is vanuit prestatieoogpunt niet uitvoerbaar. Nog steeds zal deze snapshot altijd in het verleden liggen, wat nooit zal leiden tot Zero RTO.
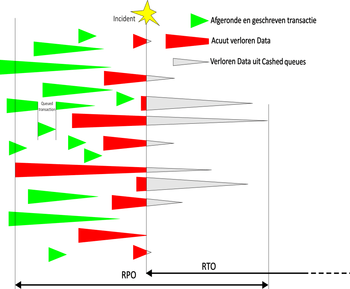
Uitgestelde databasetransacties
Relationele databases gebruiken bij het verwerken van transacties ‘wijzig-en-bevestigregels’. Een applicatie kan een aantal velden wijzigen, maar de completering van de transactie pas later bevestigen. Bij sommige databases wordt omwille van prestatieverbetering de bevestiging van een transactie alvast in het interne geheugen van de applicatieserver uitgevoerd, waardoor er transacties voor een relatief lange tijd onbevestigd blijven. Als in die tijd de database aborteert is deze niet langer consistent en moet een ‘roll back’ worden uitgevoerd.
Grote gebruikersaantallen in combinatie met lange ketens
Elke gebruikerstransactie kent bij de zogenaamde "meervoudige lagenarchitectuur", een lange weg van verwerking. Gerekend vanaf de bevestiging van de gebruiker tot het moment dat de gegevens daadwerkelijk zijn weggeschreven naar disk en de database in een consistente toestand verkeert kunnen er tientallen seconden verstreken zijn. De applicatie heeft honderden gebruikers tegelijkertijd en het blijft dus niet bij één enkelvoudige wijziging, maar een veelheid van transacties tegelijk moet doorgevoerd worden. Doorgaans wordt een deel van de aan te brengen wijzigingen tijdelijk in een wachtrij gezet (transactiewachtrij), omdat er relaties bestaan tussen gegevensverzamelingen, die eerst verzameld moeten worden om de samenhang vast te stellen. Hier komt nog bij dat de tussenliggende logische en fysieke techniek zelf ook mechanismen hanteert ter bevordering van de prestatie. Gegevens worden in een cache opgeslagen om alvast de bovenliggende component een bevestiging van afhandeling (commit) te kunnen sturen, wat zoiets betekent als: "beschouw dit maar als afgehandeld, dan kun je vast door met de volgende opdracht". Dit komt de prestaties ten goede, maar de keerzijde is meer dataverlies bij defecten. Tot slot is dit fenomeen ook nog eens verspreid over een lange keten van de personal computer, front-end-applicatie, LAN, applicatieserver, 'backbone' IT-infrastructuur, database server, SAN-infrastructuur, diskcontrollers met cache en uiteindelijk de harde schijven zelf.
Gedeelde en/of gecombineerde verantwoordelijkheid
Gecombineerde verantwoordelijkheid heeft onherroepelijk een nadelige invloed op de netto beschikbaarheid. Een bekend gegeven is dat de complexiteit van de applicatieondersteuning exponentieel groeit met het aantal verschillende partijen dat verantwoordelijkheden draagt en bevoegdheden heeft over één apparaat of systeem. Vanwege een exponentiële toename van de MLDT (Mean Logistics Delay Time) daalt de netto beschikbaarheid fors. Ondanks dat het probleem in kwestie eenvoudig van aard kan zijn gaat veel tijd verloren met doorverwijzen en langdurige discussies. Problemen die theoretisch in een uur verholpen kunnen worden nemen daardoor vaak dagen in beslag. In een ideale wereld zouden voor het oplossen van problemen alle verantwoordelijke en betrokken partijen direct ter plekke aanwezig zijn. De oplossing is dan ook alle verantwoordelijkheid bij één bekwame partij te beleggen. Deze partij mag dan zelf niet afhankelijk zijn van externe kennis.
Dataverminking en menselijk falen
Centraal opgeslagen bestanden en databases kunnen ook in zijn geheel verminkt raken door het falen van centrale apparatuur. In dit soort situaties lopen RPO- en RTO-waarden al snel op tot uren. Dat geldt ook bij menselijk falen waarbij per abuis bestanden of grote hoeveelheden databasegegevens onbedoeld gewist worden. In deze situatie moet er beroep worden gedaan op een backup, die doorgaans dateert van de nacht daarvoor. Bij databases kan men kiezen voor een ‘roll back’, waarbij de database tijdelijk geen nieuwe transacties kan verwerken. Vaak wordt gedacht dat het repliceren van de database een oplossing is om een RPO/RTO van nul te verwezenlijken, maar dit is in de praktijk geen oplossing voor bovengenoemd probleem, omdat de gegevens zijn gewist in zowel de originele als de gerepliceerde database. Wel kan deze techniek van dienst zijn voor een hogere beschikbaarheid, door een van beide databases te pauzeren voor nieuwe transacties en een ‘roll back’ uit te voeren. De andere database kan actief blijven voor leestransacties op de resterende gegevens. Voor volledig herstel zal in de praktijk de RTO oplopen tot een waarde gelijk aan het restant van de werkdag. De RPO echter zal binnen enkele minuten blijven, mits de DBA zijn vak verstaat.
Bronnen, noten en/of referenties
|