Perceptual-based 3D sound localization
Perceptual-based 3D sound localization is the application of knowledge of the human auditory system to develop 3D sound localization technology.
Motivation and Applications
Human listeners combine information from two ears to localize and separate sound sources originating in different locations in a process called binaural hearing. The powerful signal processing methods found in the neural systems and brains of humans and other animals are flexible, environmentally adaptable,[1] and take place rapidly and seemingly without effort.[2] Emulating the mechanisms of binaural hearing can improve recognition accuracy and signal separation in DSP algorithms, especially in noisy environments.[3] Furthermore, by understanding and exploiting biological mechanisms of sound localization, virtual sound scenes may be rendered with more perceptually relevant methods, allowing listeners to accurately perceive the locations of auditory events.[4] One way to obtain the perceptual-based sound localization is from the sparse approximations of the anthropometric features. Perceptual-based sound localization may be used to enhance and supplement robotic navigation and environment recognition capability.[1] In addition, it is also used to create virtual auditory spaces which is widely implemented in hearing aids.
Problem Statement and Basic Concepts
While the relationship between human perception of sound and various attributes of the sound field is not yet well understood,[2] DSP algorithms for sound localization are able to employ several mechanisms found in neural systems, including the interaural time difference (ITD, the difference in arrival time of a sound between two locations), the interaural intensity difference (IID, the difference in intensity of a sound between two locations), artificial pinnae, the precedence effect, and head-related transfer functions (HRTF) . When localizing 3D sound in spatial domain, one could take into account that the incoming sound signal could be reflected, defracted and scattered by the upper torso of the human which consists of shoulders, head and pinnae.Localization also depends on the direction of the sound source.[5]
HATS: Head and Torso Simulator
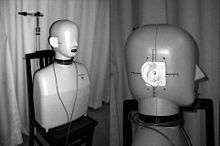
Brüel’s & Kjær’s Head And Torso Simulator (HATS) is a mannequin prototype with built-in ear and mouth simulators that provides a realistic reproduction of the acoustic properties of an average adult human head and torso. It is designed to be used in electro-acoustics tests, for example, headsets, audio conference devices, microphones, headphones and hearing aids. Various existing approaches are based on this structural model.[6]
Existing Approaches
Particle Based Tracking
It is essential to be able to analyze the distance and intensity of various sources in a spatial domain. We can track each such sound source, by using a probabilistic temporal integration, based on data obtained through a microphone array and a particle filtering tracker. Using this approach, the Probability Density Function(PDF) representing the location of each source is represented as a set of particles to which different weights (probabilities) are assigned. The choice of particle filtering over Kalman filtering is further justified by the non-gaussian probabilities arising from false detections and multiple sources.[7]
ITD, ILD, and IPD
According to the duplex theory, ITDs have a greater contribution to the localisation of low frequency sounds (below 1 kHz),[4] while ILDs are used in the localisation of high frequency sound. These approaches can be applied to selective reconstructions of spatialized signals, where spectrotemporal components believed to be dominated by the desired sound source are identified and isolated through the Short-time Fourier transform (STFT). Modern systems typically compute the STFT of the incoming signal from two or more microphones, and estimate the ITD or each spectrotemporal component by comparing the phases of the STFTs. An advantage to this approach is that it may be generalized to more than two microphones, which can improve accuracy in 3 dimensions and remove the front-back localization ambiguity that occurs with only two ears or microphones.[1] Another advantage is that the ITD is relatively strong and easy to obtain without biomimetic instruments such as dummy heads and artificial pinnae, though these may still be used to enhance amplitude disparities.[1] HRTF phase response is mostly linear and listeners are insensitive to the details of the interaural phase spectrum as long as the interaural time delay (ITD) of the combined low-frequency part of the waveform is maintained.
Interaural level differences (ILD) represents the difference in sound pressure level reaching the two ears. They provide salient cues for localizing high-frequency sounds in space, and populations of neurons that are sensitive to ILD are found at almost every synaptic level from brain stem to cortex. These cells are predominantly excited by stimulation of one ear and predominantly inhibited by stimulation of the other ear, such that the magnitude of their response is determined in large part by the intensities at the 2 ears. This gives rise to the concept of resonant damping.[8] Interaural level difference (ILD) is best for high frequency sounds because low frequency sounds are not attenuated much by the head. ILD (also known as Interaural Intensity Difference) arises when the sound source is not centred, the listener's head partially shadows the ear opposite to the source, diminishing the intensity of the sound in that ear (particularly at higher frequencies). The pinnae filters the sound in a way that is directionally dependent. This is particularly useful in determining if a sound comes from above, below, in front, or behind.
Interaural time and level differences (ITD, ILD) play a role in azimuth perception but can’t explain vertical localization. According to the duplex theory, ITDs have a greater contribution to the localisation of low frequency sounds (below 1 kHz),while ILDs are used in the localisation of high frequency sound.[8] The ILD arises from the fact that,a sound coming from a source located to one side of the head will have a higher intensity, or be louder, at the ear nearest the sound source. One can therefore create the illusion of a sound source emanating from one side of the head merely by adjusting the relative level of the sounds that are fed to two separated speakers or headphones. This is the basis of the commonly used pan control.
Interaural Phase Difference (IPD) refers to the difference in the phase of a wave that reaches each ear, and is dependent on the frequency of the sound wave and the interaural time differences (ITD).[8]
Once the brain has analyzed IPD, ITD, and ILD, the location of the sound source can be determined with relative accuracy.
Precedence Effect
The precedence effect is the observation that sound localization can be dominated by the components of a complex sound that are the first to arrive. By allowing the direct field components (those that arrive directly from the sound source) to dominate while suppressing the influence of delayed reflected components from other directions, the precedence effect may improve the accuracy of perceived sound location in a reverberant environment.Processing of the precedence effect involves enhancing the leading edge of sound envelopes of the signal after dividing it into frequency bands via bandpass filtering. This approach can be done at the monaural level as well as the binaural level, and improves accuracy in reverberant environments in both cases.However, the benefits of using the precedence effect can break down in an anechoic environment.
HRTFs
The body of a human listener obstructs incoming sound waves, causing linear filtering of the sound signal due to interference from the head, ears, and body. Humans use dynamic cues to reinforce localization. These arise from active, sometimes unconscious, motions of the listener, which change the relative position of the source. It is reported that front/back confusions which are common in static listening tests disappear when listeners are allowed to slightly turn their heads to help them in localization. However, if the sound scene is presented through headphones without compensation for head motion, the scene does not change with the user’s motion, and dynamic cues are absent.[9]
Head-related transfer functions contain all the descriptors of localization cues such as ITD and IID as well as monaural cues. Every HRTF uniquely represents the transfer of sound from a specific position in 3D space to the ears of a listener. The decoding process performed by the auditory system can be imitated using an artificial setup consisting of two microphones, two artificial ears and a HRTF database.[10] To determine the position of an audio source in 3D space, the ear input signals are convolved with the inverses of all possible HRTF pairs, where the correct inverse maximizes cross-correlation between the convolved right and left signals. In the case of multiple simultaneous sound sources, the transmission of sound from source to ears can be considered a multiple-input and multiple-output. Here, the HRTFs the source signals were filtered with en route to the microphones can be found using methods such as convolutive blind source separation, which has the advantage of efficient implementation in real-time systems. Overall, these approaches using HRTFs can be well optimized to localize multiple moving sound sources.[10] The average human has the remarkable ability to locate a sound source with better than 5◦ accuracy in both azimuth and elevation, in challenging environments.
References
- Huang; Ohnishi, Sugie (1997). "Building ears for robots: Sound localization and separation". Artificial Life and Robotics. 1 (4): 157–163. doi:10.1007/bf02471133.
- Karam; Kleijn, Maclean (September 2013). "Scanning the Issue: Perception-Based Media Processing". Proceedings of the IEEE. 101 (9): 1900–1904. doi:10.1109/jproc.2013.2270898.
- Hermansky; Cohen, Stern (September 2013). "Perceptual Properties of Current Speech Recognition Technology". Proceedings of the IEEE. 101 (9): 1–18. doi:10.1109/JPROC.2013.2252316.
- Spors, Sascha; Wierstorf, Hagen; Raake, Alexander; Melchior, Frank; Frank, Matthias; Zotter, Franz (2013). "Spatial Sound With Loudspeakers and Its Perception: A Review of the Current State". Proceedings of the IEEE. 101 (9): 1920–1938. doi:10.1109/JPROC.2013.2264784. ISSN 0018-9219.
- Martin Rothbucher; David Kronmüller; Marko Durkovic; Tim Habigt; Klaus Diepold. "HRTF sound Localization,Institute for Data Processing, Technische Universität München,Germany". Cite journal requires
|journal=(help) - Bilinski,Piotr; Ahrens, Jens; Thomas, Mark R.P; Tashev, Ivan; Platt,John C (2004). "HRTF magnitude synthesis via sparse representation of anthropometric features" (PDF) (Microsoft Research, One Microsoft Way, Redmond, WA 98052, USA). Cite journal requires
|journal=(help) - Jean,Marc; Francois, Michuad; Jean,Rouat (2006). "Robust 3D localization and tracking of sound sources using Beamforming and Particle Filtering". 2006 IEEE International Conference on Acoustics Speed and Signal Processing Proceedings. 4. pp. IV-841–IV-844. arXiv:1604.01642. doi:10.1109/ICASSP.2006.1661100. ISBN 1-4244-0469-X.
- Bilinski,Piotr; Ahrens, Jens; Thomas, Mark R.P; Tashev, Ivan; Platt,John C (2004). "HRTF magnitude synthesis via sparse representation of anthropometric features" (PDF) (Microsoft Research, One Microsoft Way, Redmond, WA 98052, USA). Cite journal requires
|journal=(help) - Zotkin, Dmitry N; Duraiswami, Ramani; Davis, Larry S (2002). "Creation of virtual auditory spaces". IEEE International Conference on Acoustics Speech and Signal Processing. pp. II-2113–II-2116. doi:10.1109/ICASSP.2002.5745052. ISBN 978-0-7803-7402-7.
- Keyrouz; Maier, Diepold (4–6 December 2006). "A Novel Humanoid Binaural 3D Sound Localization and Separation Algorithm". 2006 6th IEEE-RAS International Conference on Humanoid Robots. pp. 296–301. doi:10.1109/ICHR.2006.321400. ISBN 1-4244-0199-2.