LL grammar
In formal language theory, an LL grammar is a context-free grammar that can be parsed by an LL parser, which parses the input from Left to right, and constructs a Leftmost derivation of the sentence (hence LL, compared with LR parser that constructs a rightmost derivation). A language that has an LL grammar is known as an LL language. These form subsets of deterministic context-free grammars (DCFGs) and deterministic context-free languages (DCFLs), respectively. One says that a given grammar or language "is an LL grammar/language" or simply "is LL" to indicate that it is in this class.
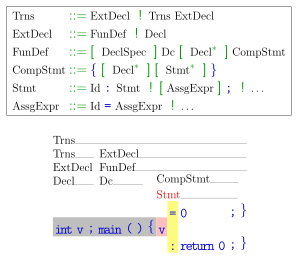
int v ;main(){" and is about choose a rule to derive the nonterminal "Stmt". Looking only at the first lookahead token "v", it cannot decide which of both alternatives for "Stmt" to choose, since two input continuations are possible. They can be discriminated by peeking at the second lookahead token (yellow background).LL parsers are table-based parsers, similar to LR parsers. LL grammars can alternatively be characterized as precisely those that can be parsed by a predictive parser – a recursive descent parser without backtracking – and these can be readily written by hand. This article is about the formal properties of LL grammars; for parsing, see LL parser or recursive descent parser.
Formal definition
Given a natural number , a context-free grammar is an LL(k) grammar if


- for each terminal symbol string of length up to symbols,
- for each nonterminal symbol , and
- for each terminal symbol string ,




there is at most one production rule such that for some terminal symbol strings ,


- the string can be derived from the start symbol ,
- can be derived from after first applying rule , and
- the first symbols of and of agree.[2]







Informally, when a parser has derived , with its leftmost nonterminal and already consumed from the input, then by looking at that and peeking at the next symbols of the current input, the parser can identify with certainty the production rule for .

When rule identification is possible even without considering the past input , then the grammar is called a strong LL(k) grammar.[3] In the formal definition of a strong LL(k) grammar, the universal quantifier for is omitted, and is added to the "for some" quantifier for . For every LL(k) grammar, a structurally equivalent strong LL(k) grammar can be constructed.[4]

An alternative, but equivalent, formal definition is the following: is an LL(k) grammar if, for arbitrary derivations

when the first symbols of agree with those of , then .[5][6]


Relation to other grammar classes
Allowing ε-rules increases the expressive power of a grammar: For every ε-free LL(k+1) grammar, there exists a LL(k) grammar with ε-rules that generates the same language.[7] Commonly, ε-free LL(k) grammars are used for LL(k) parsers.
The class of LL(k) languages forms a strictly increasing sequence of sets: LL(0) ⊊ LL(1) ⊊ LL(2) ⊊ ….[8] Since these are all DCFLs, a corollary is that for any fixed k, there are DCFLs that cannot be recognized by an LL(k) parser.
A generalization, called an LL(*) parser, is not restricted to a finite number k of tokens of lookahead, but can make parsing decisions by recognizing whether the following tokens belong to a regular language (for example by use of a Deterministic Finite Automaton). Accordingly there are the set of LL(*) grammars and the set of LL(*) languages.[9] It appears to be yet unclear where the latter set is located in the Chomsky hierarchy.
Every LL(k) grammar is also a LR(k) grammar. It is also decidable if a given LR(k) grammar is also an LL(m) grammar for some m.[10] An ε-free LL(1) grammar is also an SLR(1) grammar. An LL(1) grammar with symbols that have both empty and non-empty derivations is also an LALR(1) grammar. An LL(1) grammar with symbols that have only the empty derivation may or may not be LALR(1).[11]
LL grammars cannot have rules containing left recursion.[12] Each LL(k) grammar that is ε-free can be transformed into an equivalent LL(k) grammar in Greibach normal form (which by definition does not have rules with left recursion).[13]
Simple deterministic languages
A context-free grammar is called simple deterministic,[14] or just simple,[15] if
- it is in Greibach normal form (i.e. each rule has the form ), and
- different right hand sides for the same nonterminal always start with different terminals .



A set of strings is called a simple deterministic, or just simple, language, if it has a simple deterministic grammar.
The class of languages having an ε-free LL(1) grammar in Greibach normal form equals the class of simple deterministic languages.[16] This language class includes the regular sets not containing ε.[15] Equivalence is decidable for it, while inclusion is not.[14]
Applications
LL grammars, particularly LL(1) grammars, are of great practical interest, as they are easy to parse, either by LL parsers or by recursive descent parsers, and many computer languages are designed to be LL(1) for this reason. Languages based on grammars with a high value of k have traditionally been considered to be difficult to parse, although this is less true now given the availability and widespread use of parser generators supporting LL(k) grammars for arbitrary k.
See also
- Comparison of parser generators for a list of LL(k) and LL(*) parsers
Notes
- Brian W. Kernighan and Dennis M. Ritchie (Apr 1988). The C Programming Language. Prentice Hall Software Series (2nd ed.). Englewood Cliffs/NJ: Prentice Hall. ISBN 978-0131103627. Appendix A.13 "Grammar", p.193 ff. The top image part shows a simplified excerpt in an EBNF-like notation.
- Rosenkrantz & Stearns (1970, p. 227). Def.1. The authors do not consider the case k=0.
- Rosenkrantz & Stearns (1970, p. 235) Def.2
- Rosenkrantz & Stearns (1970, p. 235) Theorem 2
- where "" denotes derivability by leftmost derivations, and , , and
- Waite & Goos (1984, p. 123) Def. 5.22
- Rosenkrantz & Stearns (1970, p. 242)
- Rosenkrantz & Stearns (1970, p. 246-247): Using "" to denote "or", the string set has an , but no ε-free grammar, for each .
- Parr & Fisher (2011)
- Rozenkratz & Stearns (1970, pp. 254–255)
- Beaty (1982)
- Rozenkratz & Stearns (1970, pp. 241) Lemma 5
- Rozenkratz & Stearns (1970, p. 242) Theorem 4
- Korenjak & Hopcroft (1966)
- Hopcroft & Ullman (1979, p. 229) Exercise 9.3
- Rosenkrantz & Stearns (1970, p. 243)








References
- Beatty, J. C. (1982). "On the relationship between LL(1) and LR(1) grammars" (PDF). Journal of the ACM. 29 (4 (Oct)): 1007–1022. doi:10.1145/322344.322350.CS1 maint: ref=harv (link)
- Hopcroft, John E.; Ullman, Jeffrey D. (1979). Introduction to Automata Theory, Languages, and Computation. Addison-Wesley. ISBN 978-0-201-02988-8.
- Korenjak, A.J., Hopcroft, J.E. (1966). "Simple deterministic languages". IEEE Conf. Rec. 7th Ann. Symp. on Switching and Automata Theory (SWAT). IEEE Pub. No. 16-C-40. pp. 36–46. doi:10.1109/SWAT.1966.22.CS1 maint: multiple names: authors list (link) CS1 maint: ref=harv (link)
- Parr, T.; Fisher, K. (2011). "LL(*): The Foundation of the ANTLR Parser Generator" (PDF). ACM SIGPLAN Notices. 46 (6): 425–436. doi:10.1145/1993316.1993548.CS1 maint: ref=harv (link)
- Rosenkrantz, D. J.; Stearns, R. E. (1970). "Properties of Deterministic Top Down Grammars". Information and Control. 17 (3): 226–256. doi:10.1016/s0019-9958(70)90446-8.
- William M. Waite and Gerhard Goos (1984). Compiler Construction. Texts and Monographs in Computer Science. Heidelberg: Springer. ISBN 978-3-540-90821-0.CS1 maint: ref=harv (link)
Further reading
- Seppo Sippu; Eljas Soisalon-Soininen (1990). Parsing Theory: LR(k) and LL(k) Parsing. Springer Science & Business Media. ISBN 978-3-540-51732-0.