Cache prefetching
Cache prefetching is a technique used by computer processors to boost execution performance by fetching instructions or data from their original storage in slower memory to a faster local memory before it is actually needed (hence the term 'prefetch').[1] Most modern computer processors have fast and local cache memory in which prefetched data is held until it is required. The source for the prefetch operation is usually main memory. Because of their design, accessing cache memories is typically much faster than accessing main memory, so prefetching data and then accessing it from caches is usually many orders of magnitude faster than accessing it directly from main memory.
Data vs. instruction cache prefetching
Cache prefetching can either fetch data or instructions into cache.
- Data prefetching fetches data before it is needed. Because data access patterns show less regularity than instruction patterns, accurate data prefetching is generally more challenging than instruction prefetching.
- Instruction prefetching fetches instructions before they need to be executed. The first mainstream microprocessors to use some form of instruction prefetch were the Intel 8086 (six bytes) and the Motorola 68000 (four bytes). In recent years, all high-performance processors use prefetching techniques.
Hardware vs. software cache prefetching
Cache prefetching can be accomplished either by hardware or by software.[2]
- Hardware based prefetching is typically accomplished by having a dedicated hardware mechanism in the processor that watches the stream of instructions or data being requested by the executing program, recognizes the next few elements that the program might need based on this stream and prefetches into the processor's cache.[3]
- Software based prefetching is typically accomplished by having the compiler analyze the code and insert additional "prefetch" instructions in the program during compilation itself.[4]
Methods of hardware prefetching
Stream buffers
- Stream buffers were developed based on the concept of "one block lookahead (OBL) scheme" proposed by Alan Jay Smith.[1]
- Stream buffers are one of the most common hardware based prefetching techniques in use.[5] This technique was originally proposed by Norman Jouppi in 1990[6] and many variations of this method have been developed since.[7][8][9] The basic idea is that the cache miss address (and subsequent addresses) are fetched into a separate buffer of depth . This buffer is called a stream buffer and is separate from cache. The processor then consumes data/instructions from the stream buffer if the address associated with the prefetched blocks match the requested address generated by the program executing on the processor. The figure below illustrates this setup:

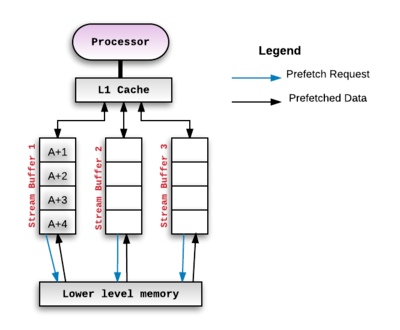
- Whenever the prefetch mechanism detects a miss on a memory block, say A, it allocates a stream to begin prefetching successive blocks from the missed block onward. If the stream buffer can hold 4 blocks, then we would prefetch A+1, A+2, A+3, A+4 and hold those in the allocated stream buffer. If the processor consumes A+1 next, then it shall be moved "up" from the stream buffer to the processor's cache. The first entry of the stream buffer would now be A+2 and so on. This pattern of prefetching successive blocks is called Sequential Prefetching. It is mainly used when contiguous locations are to be prefetched. For example, it is used when prefetching instructions.
- This mechanism can be scaled up by adding multiple such 'stream buffers' - each of which would maintain a separate prefetch stream. For each new miss, there would be a new stream buffer allocated and it would operate in a similar way as described above.
- The ideal depth of the stream buffer is something that is subject to experimentation against various benchmarks[6] and depends on the rest of the microarchitecture involved.
Another pattern of prefetching instructions is to prefetch addresses that are addresses ahead in the sequence. It is mainly used when the consecutive blocks that are to be prefetched are addresses apart.[2] This is termed as Strided Prefetching.

Methods of software prefetching
Compiler directed prefetching
Compiler directed prefetching is widely used within loops with a large number of iterations. In this technique, the compiler predicts future cache misses and inserts a prefetch instruction based on the miss penalty and execution time of the instructions.
These prefetches are non-blocking memory operations, i.e. these memory accesses do not interfere with actual memory accesses. They do not change the state of the processor or cause page faults.
One main advantage of software prefetching is that it reduces the number of compulsory cache misses.[2]
The following example shows the how a prefetch instruction will be added into a code to improve cache performance.
Consider a for loop as shown below:
for (int i=0; i<1024; i++) {
array1[i] = 2 * array1[i];
}
At each iteration, the ith element of the array "array1" is accessed. Therefore, we can prefetch the elements that are going to be accessed in future iterations by inserting a "prefetch" instruction as shown below:
for (int i=0; i<1024; i++) {
prefetch (array1 [i + k]);
array1[i] = 2 * array1[i];
}
Here, the prefetch stride, depends on two factors, the cache miss penalty and the time it takes to execute a single iteration of the for loop. For instance, if one iteration of the loop takes 7 cycles to execute, and the cache miss penalty is 49 cycles then we should have - which means that we prefetch 7 elements ahead. With the first iteration, i will be 0, so we prefetch the 7th element. Now, with this arrangement, the first 7 accesses (i=0->6) will still be misses (under the simplifying assumption that each element of array1 is in a separate cache line of its own).

Comparison of hardware and software prefetching
- While software prefetching requires programmer or compiler intervention, hardware prefetching requires special hardware mechanisms.[2]
- Software prefetching works well only with loops where there is regular array access as programmer has to hand code the prefetch instructions. Whereas, hardware prefetchers work dynamically based on the program's behavior at runtime.[2]
- Hardware prefetching also has less CPU overhead when compared to software prefetching.[10]
Metrics of cache prefetching
There are three main metrics to judge cache prefetching[2]
Coverage
Coverage is the fraction of total misses that are eliminated because of prefetching, i.e.
,

where,

Accuracy
Accuracy is the fraction of total prefetches that were useful - i.e. the ratio of the number of memory addresses prefetched were actually referenced by the program to the total prefetches done.

While it appears that having perfect accuracy might imply that there are no misses, this is not the case. The prefetches themselves might result in new misses if the prefetched blocks are placed directly into the cache. Although these may be a small fraction of the total number of misses we might see without any prefetching, this is a non-zero number of misses.
Timeliness
The qualitative definition of timeliness is how early a block is prefetched versus when it is actually referenced. An example to further explain timeliness is as follows :
Consider a for loop where each iteration takes 12 cycles to execute and the 'prefetch' operation takes 3 cycles. This implies that for the prefetched data to be useful, we must start the prefetch iterations prior to its usage to maintain timeliness.

See also
References
- 1 2 Smith, Alan Jay (1982-09-01). "Cache Memories". ACM Comput. Surv. 14 (3): 473–530. doi:10.1145/356887.356892. ISSN 0360-0300.
- 1 2 3 4 5 6 Solihin, Yan (2016). Fundamentals of parallel multicore architecture. Boca Raton, FL: CRC Press, Taylor & Francis Group. p. 163. ISBN 1482211181.
- ↑ Baer, Jean-Loup; Chen, Tien-Fu (1991-01-01). "An Effective On-chip Preloading Scheme to Reduce Data Access Penalty". Proceedings of the 1991 ACM/IEEE Conference on Supercomputing. Supercomputing '91. New York, NY, USA: ACM: 176–186. doi:10.1145/125826.125932. ISBN 0897914597.
- ↑ Kennedy, Porterfield, Allan (1989-01-01). Software methods for improvement of cache performance on supercomputer applications (Thesis). Rice University.
- ↑ Mittal, Sparsh (2016-08-01). "A Survey of Recent Prefetching Techniques for Processor Caches". ACM Comput. Surv. 49 (2): 35:1–35:35. doi:10.1145/2907071. ISSN 0360-0300.
- 1 2 3 "Improving Direct-Mapped Cache Performance by the Addition of a Small Fully-Associative Cache and Prefetch Buffers".
- ↑ Chen, Tien-Fu; Baer, Jean-Loup (1995-05-01). "Effective hardware-based data prefetching for high-performance processors". IEEE Transactions on Computers. 44 (5): 609–623. doi:10.1109/12.381947. ISSN 0018-9340.
- ↑ Palacharla, S.; Kessler, R. E. (1994-01-01). "Evaluating Stream Buffers As a Secondary Cache Replacement". Proceedings of the 21st Annual International Symposium on Computer Architecture. ISCA '94. Los Alamitos, CA, USA: IEEE Computer Society Press: 24–33. doi:10.1145/191995.192014. ISBN 0818655100.
- ↑ "Storage Efficient Hardware Prefetching using Delta-Correlating Prediction Tables".
- ↑ Callahan, David; Kennedy, Ken; Porterfield, Allan (1991-01-01). "Software Prefetching". Proceedings of the Fourth International Conference on Architectural Support for Programming Languages and Operating Systems. ASPLOS IV. New York, NY, USA: ACM: 40–52. doi:10.1145/106972.106979. ISBN 0897913809.