Chemical biology
Chemical biology is a scientific discipline spanning the fields of chemistry and biology. The discipline involves the application of chemical techniques, analysis, and often small molecules produced through synthetic chemistry, to the study and manipulation of biological systems. In contrast to biochemistry, which involves the study of the chemistry of biomolecules and regulation of biochemical pathways within and between cells, chemical biology deals with chemistry applied to biology.
Introduction
Some forms of chemical biology attempt to answer biological questions by directly probing living systems at the chemical level. In contrast to research using biochemistry, genetics, or molecular biology, where mutagenesis can provide a new version of the organism, cell, or biomolecule of interest, chemical biology probes systems in vitro and in vivo with small molecules that have been designed for a specific purpose or identified on the basis of biochemical or cell-based screening (see chemical genetics).
Chemical biology is one of several interdisciplinary sciences that tend to differ from older, reductionist fields and whose goals are to achieve a description of scientific holism. Chemical biology has scientific, historical and philosophical roots in medicinal chemistry, supramolecular chemistry, bioorganic chemistry, pharmacology, genetics, biochemistry, and metabolic engineering.
Systems of interest
Proteomics
Proteomics investigates the proteome, the set of expressed proteins at a given time under defined conditions. As a discipline, proteomics has moved past rapid protein identification and has developed into a biological assay for quantitative analysis of complex protein samples by comparing protein changes in differently perturbed systems.[1] Current goals in proteomics include determining protein sequences, abundance and any post-translational modifications. Also of interest are protein–protein interactions, cellular distribution of proteins and understanding protein activity. Another important aspect of proteomics is the advancement of technology to achieve these goals.
Protein levels, modifications, locations, and interactions are complex and dynamic properties. With this complexity in mind, experiments need to be carefully designed to answer specific questions especially in the face of the massive amounts of data that are generated by these analyses. The most valuable information comes from proteins that are expressed differently in a system being studied. These proteins can be compared relative to each other using quantitative proteomics, which allows a protein to be labeled with a mass tag. Proteomic technologies must be sensitive and robust; for these reasons, the mass spectrometer has been the workhorse of protein analysis. The high precision of mass spectrometry can distinguish between closely related species and species of interest can be isolated and fragmented within the instrument. Its applications to protein analysis was only possible in the late 1980s with the development of protein and peptide ionization with minimal fragmentation. These breakthroughs were ESI and MALDI. Mass spectrometry technologies are modular and can be chosen or optimized to the system of interest.
Chemical biologists are poised to impact proteomics through the development of techniques, probes and assays with synthetic chemistry for the characterization of protein samples of high complexity. These approaches include the development of enrichment strategies, chemical affinity tags and probes.
Enrichment techniques
Samples for Proteomics contain a myriad of peptide sequences, the sequence of interest may be highly represented or of low abundance. However, for successful MS analysis the peptide should be enriched within the sample. Reduction of sample complexity is achieved through selective enrichment using affinity chromatography techniques. This involves targeting a peptide with a distinguishing feature like a biotin label or a post translational modification.[2] Methods have been developed that include the use of antibodies, lectins to capture glycoproteins, immobilized metal ions to capture phosphorylated peptides and suicide enzyme substrates to capture specific enzymes. Here, chemical biologists can develop reagents to interact with substrates, specifically and tightly, to profile a targeted functional group on a proteome scale. Development of new enrichment strategies is needed in areas like non-ser/thr/tyr phosphorylation sites and other post translational modifications. Other methods of decomplexing samples relies on upstream chromatographic separations.
Affinity tags
Chemical synthesis of affinity tags has been crucial to the maturation of quantitative proteomics. iTRAQ, Tandem mass tags (TMT) and Isotope-coded affinity tag (ICAT) are protein mass-tags that consist of a covalently attaching group, a mass (isobaric or isotopic) encoded linker and a handle for isolation. Varying mass-tags bind to different proteins as a sort of footprint such that when analyzing cells of differing perturbations, the levels of each protein can be compared relatively after enrichment by the introduced handle. Other methods include SILAC and heavy isotope labeling. These methods have been adapted to identify complexing proteins by labeling a bait protein, pulling it down and analyzing the proteins it has complexed.[3] Another method creates an internal tag by introducing novel amino acids that are genetically encoded in prokaryotic and eukaryotic organisms. These modifications create a new level of control and can facilitate photocrosslinking to probe protein–protein interactions.[4] In addition, keto, acetylene, azide, thioester, boronate, and dehydroalanine- containing amino acids can be used to selectively introduce tags, and novel chemical functional groups into proteins.[5]
Enzyme probes
To investigate enzymatic activity as opposed to total protein, activity-based reagents have been developed to label the enzymatically active form of proteins (see Activity-based proteomics). For example, serine hydrolase- and cysteine protease-inhibitors have been converted to suicide inhibitors.[6] This strategy enhances the ability to selectively analyze low abundance constituents through direct targeting. Structures that mimic these inhibitors could be introduced with modifications that will aid proteomic analysis- like an identification handle or mass tag.[7] Enzyme activity can also be monitored through converted substrate.[8] This strategy relies on using synthetic substrate conjugates that contain moieties that are acted upon by specific enzymes. The product conjugates are then captured by an affinity reagent and analyzed. The measured concentration of product conjugate allow the determination of the enzyme velocity. Other factors such as temperature, enzyme concentration and substrate concentration can be visualized.[9] Identification of enzyme substrates (of which there may be hundreds or thousands, many of which unknown) is a problem of significant difficulty in proteomics and is vital to the understanding of signal transduction pathways in cells; techniques for labelling cellular substrates of enzymes is an area chemical biologists can address. A method that has been developed uses "analog-sensitive" kinases to label substrates using an unnatural ATP analog, facilitating visualization and identification through a unique handle.[10]
Glycobiology
While DNA, RNA and proteins are all encoded at the genetic level, there exists a separate system of trafficked molecules in the cell that are not encoded directly at any direct level: sugars. Thus, glycobiology is an area of dense research for chemical biologists. For instance, live cells can be supplied with synthetic variants of natural sugars in order to probe the function of the sugars in vivo. Carolyn Bertozzi, previously at University of California, Berkeley, has developed a method for site-specifically reacting molecules the surface of cells that have been labeled with synthetic sugars.
Combinatorial chemistry
Chemical biologists used automated synthesis of many diverse compounds in order to experiment with effects of small molecules on biological processes. More specifically, they observe changes in the behaviors of proteins when small molecules bind to them. Such experiments may supposedly lead to discovery of small molecules with antibiotic or chemotherapeutic properties. These approaches are identical to those employed in the discipline of pharmacology.
Molecular sensing
Chemical biologists are also interested in developing new small-molecule and biomolecule-based tools to study biological processes, often by molecular imaging techniques.[11] The field of molecular sensing was popularized by Roger Tsien's work developing calcium-sensing fluorescent compounds as well as pioneering the use of GFP, for which he was awarded the 2008 Nobel Prize in Chemistry.[12] Today, researchers continue to utilize basic chemical principles to develop new compounds for the study of biological metabolites and processes.
Employing biology
Many research programs are also focused on employing natural biomolecules to perform biological tasks or to support a new chemical method or material. In this regard, researchers have shown that DNA can serve as a template for synthetic chemistry, self-assembling proteins can serve as a structural scaffold for new materials, and RNA can be evolved in vitro to produce new catalytic function. Additionally, heterobifunctional (two-sided) synthetic small molecules such as dimerizers or PROTACs bring two proteins together inside cells, which can synthetically induce important new biological functions such as targeted protein degradation.[13]
Protein misfolding and aggregation as a cause of disease
A common form of aggregation is long, ordered spindles called amyloid fibrils that are implicated in Alzheimer’s disease and that have been shown to consist of cross-linked beta sheet regions perpendicular to the backbone of the polypeptide.[14] Another form of aggregation occurs with prion proteins, the glycoproteins found with Creutzfeldt–Jakob disease and bovine spongiform encephalopathy. In both structures, aggregation occurs through hydrophobic interactions and water must be excluded from the binding surface before aggregation can occur.[15] A movie of this process can be seen in "Chemical and Engineering News".[16] The diseases associated with misfolded proteins are life-threatening and extremely debilitating, which makes them an important target for chemical biology research.
Through the transcription and translation process, DNA encodes for specific sequences of amino acids. The resulting polypeptides fold into more complex secondary, tertiary, and quaternary structures to form proteins. Based on both the sequence and the structure, a particular protein is conferred its cellular function. However, sometimes the folding process fails due to mutations in the genetic code and thus the amino acid sequence or due to changes in the cell environment (e.g. pH, temperature, reduction potential, etc.). Misfolding occurs more often in aged individuals or in cells exposed to a high degree of oxidative stress, but a fraction of all proteins misfold at some point even in the healthiest of cells.
Normally when a protein does not fold correctly, molecular chaperones in the cell can encourage refolding back into its active form. When refolding is not an option, the cell can also target the protein for degradation back into its component amino acids via proteolytic, lysosomal, or autophagic mechanisms. However, under certain conditions or with certain mutations, the cells can no longer cope with the misfolded protein(s) and a disease state results. Either the protein has a loss-of-function, such as in cystic fibrosis, in which it loses activity or cannot reach its target, or the protein has a gain-of-function, such as with Alzheimer's disease, in which the protein begins to aggregate causing it to become insoluble and non-functional.
Protein misfolding has previously been studied using both computational approaches as well as in vivo biological assays in model organisms such as Drosophila melanogaster and C. elegans. Computational models use a de novo process to calculate possible protein structures based on input parameters such as amino acid sequence, solvent effects, and mutations. This method has the shortcoming that the cell environment has been drastically simplified, which limits the factors that influence folding and stability. On the other hand, biological assays can be quite complicated to perform in vivo with high-throughput like efficiency and there always remains the question of how well lower organism systems approximate human systems.
Dobson et al. propose combining these two approaches such that computational models based on the organism studies can begin to predict what factors will lead to protein misfolding.[17] Several experiments have already been performed based on this strategy. In experiments on Drosophila, different mutations of beta amyloid peptides were evaluated based on the survival rates of the flies as well as their motile ability. The findings from the study show that the more a protein aggregates, the more detrimental the neurological dysfunction.[17][18][19] Further studies using transthyretin, a component of cerebrospinal fluid that binds to beta amyloid peptide deterring aggregation but can itself aggregate especially when mutated, indicate that aggregation prone proteins may not aggregate where they are secreted and rather are deposited in specific organs or tissues based on each mutation.[20] Kelly et al. have shown that the more stable, both kinetically and thermodynamically, a misfolded protein is the more likely the cell is to secrete it from the endoplasmic reticulum rather than targeting the protein for degradation.[21] In addition, the more stress that a cell feels from misfolded proteins the more probable new proteins will misfold.[22] These experiments as well as others having begun to elucidate both the intrinsic and extrinsic causes of misfolding as well as how the cell recognizes if proteins have folded correctly.
As more information is obtained on how the cell copes with misfolded proteins, new therapeutic strategies begin to emerge. An obvious path would be prevention of misfolding. However, if protein misfolding cannot be avoided, perhaps the cell's natural mechanisms for degradation can be bolstered to better deal with the proteins before they begin to aggregate.[23] Before these ideas can be realized, many more experiments need to be done to understand the folding and degradation machinery as well as what factors lead to misfolding. More information about protein misfolding and how it relates to disease can be found in the recently published book by Dobson, Kelly, and Rameriz-Alvarado entitled Protein Misfolding Diseases Current and Emerging Principles and Therapies.[24]
Chemical synthesis of peptides
In contrast to the traditional biotechnological practice of obtaining peptides or proteins by isolation from cellular hosts through cellular protein production, advances in chemical techniques for the synthesis and ligation of peptides has allowed for the total synthesis of some peptides and proteins. Chemical synthesis of proteins is a valuable tool in chemical biology as it allows for the introduction of non-natural amino acids as well as residue specific incorporation of "posttranslational modifications" such as phosphorylation, glycosylation, acetylation, and even ubiquitination. These capabilities are valuable for chemical biologists as non-natural amino acids can be used to probe and alter the functionality of proteins, while post translational modifications are widely known to regulate the structure and activity of proteins. Although strictly biological techniques have been developed to achieve these ends, the chemical synthesis of peptides often has a lower technical and practical barrier to obtaining small amounts of the desired protein. Given the widely recognized importance of proteins as cellular catalysts and recognition elements, the ability to precisely control the composition and connectivity of polypeptides is a valued tool in the chemical biology community and is an area of active research.
While chemists have been making peptides for over 100 years,[25] the ability to efficiently and quickly synthesize short peptides came of age with the development of Bruce Merrifield's solid phase peptide synthesis (SPPS). Prior to the development of SPPS, the concept of step-by-step polymer synthesis on an insoluble support was without chemical precedent.[26] The use of a covalently bound insoluble polymeric support greatly simplified the process of peptide synthesis by reducing purification to a simple "filtration and wash" procedure and facilitated a boom in the field of peptide chemistry. The development and "optimization" of SPPS took peptide synthesis from the hands of the specialized peptide synthesis community and put it into the hands of the broader chemistry, biochemistry, and now chemical biology community. SPPS is still the method of choice for linear synthesis of polypeptides up to 50 residues in length[26] and has been implemented in commercially available automated peptide synthesizers. One inherent shortcoming in any procedure that calls for repeated coupling reactions is the buildup of side products resulting from incomplete couplings and side reactions. This places the upper bound for the synthesis of linear polypeptide lengths at around 50 amino acids, while the "average" protein consists of 250 amino acids.[25] Clearly, there was a need for development of "non-linear" methods to allow synthetic access to the average protein.
Although the shortcomings of linear SPPS were recognized not long after its inception, it took until the early 1990s for effective methodology to be developed to ligate small peptide fragments made by SPPS, into protein sized polypeptide chains (for recent review of peptide ligation strategies, see review by Dawson et al.[27]). The oldest and best developed of these methods is termed native chemical ligation. Native chemical ligation was unveiled in a 1994 paper from the laboratory of Stephen B. H. Kent.[28] Native chemical ligation involves the coupling of a C-terminal thioester and an N-terminal cysteine residue, ultimately resulting in formation of a "native" amide bond. Further refinements in native chemical ligation have allowed for kinetically controlled coupling of multiple peptide fragments, allowing access to moderately sized peptides such as an HIV-protease dimer[29] and human lysozyme.[30] Even with the successes and attractive features of native chemical ligation, there are still some drawbacks in the utilization of this technique. Some of these drawbacks include the installation and preservation of a reactive C-terminal thioester, the requirement of an N-terminal cysteine residue (which is the second-least-common amino acid in proteins),[31] and the requirement for a sterically unincumbering C-terminal residue.
Other strategies that have been used for the ligation of peptide fragments using the acyl transfer chemistry first introduced with native chemical ligation include expressed protein ligation,[32] sulfurization/desulfurization techniques,[33] and use of removable thiol auxiliaries.[34]
Expressed protein ligation allows for the biotechnological installation of a C-terminal thioester using intein biochemistry, thereby allowing the appendage of a synthetic N-terminal peptide to the recombinantly produced C-terminal portion. This technique allows for access to much larger proteins, as only the N-terminal portion of the resulting protein has to be chemically synthesized. Both sulfurization/desulfurization techniques and the use of removable thiol auxiliaries involve the installation of a synthetic thiol moiety to carry out the standard native chemical ligation chemistry, followed by removal of the auxiliary/thiol. These techniques help to overcome the requirement of an N-terminal cysteine needed for standard native chemical ligation, although the steric requirements for the C-terminal residue are still limiting.
A final category of peptide ligation strategies include those methods not based on native chemical ligation type chemistry. Methods that fall in this category include the traceless Staudinger ligation,[35] azide-alkyne dipolar cycloadditions,[36] and imine ligations.[37]
Major contributors in this field today include Stephen B. H. Kent, Philip E. Dawson, and Tom W. Muir, as well as many others involved in methodology development and applications of these strategies to biological problems.
Protein design by directed evolution
One of the primary goals of protein engineering is the design of novel peptides or proteins with a desired structure and chemical activity. Because our knowledge of the relationship between primary sequence, structure, and function of proteins is limited, rational design of new proteins with enzymatic activity is extremely challenging. Directed evolution, repeated cycles of genetic diversification followed by a screening or selection process, can be used to mimic Darwinian evolution in the laboratory to design new proteins with a desired activity.[38]
Several methods exist for creating large libraries of sequence variants. Among the most widely used are subjecting DNA to UV radiation or chemical mutagens, error-prone PCR, degenerate codons, or recombination.[39][40] Once a large library of variants is created, selection or screening techniques are used to find mutants with a desired attribute. Common selection/screening techniques include fluorescence-activated cell sorting (FACS),[41] mRNA display,[42] phage display, or in vitro compartmentalization.[43] Once useful variants are found, their DNA sequence is amplified and subjected to further rounds of diversification and selection. Since only proteins with the desired activity are selected, multiple rounds of directed evolution lead to proteins with an accumulation beneficial traits.
There are two general strategies for choosing the starting sequence for a directed evolution experiment: de novo design and redesign. In a protein design experiment, an initial sequence is chosen at random and subjected to multiple rounds of directed evolution. For example, this has been employed successfully to create a family of ATP-binding proteins with a new folding pattern not found in nature.[44] Random sequences can also be biased towards specific folds by specifying the characteristics (such as polar vs. nonpolar) but not the specific identity of each amino acid in a sequence. Among other things, this strategy has been used to successfully design four-helix bundle proteins.[45][46] Because it is often thought that a well-defined structure is required for activity, biasing a designed protein towards adopting a specific folded structure is likely to increase the frequency of desirable variants in constructed libraries.
In a protein redesign experiment, an existing sequence serves as the starting point for directed evolution. In this way, old proteins can be redesigned for increased activity or new functions. Protein redesign has been used for protein simplification, creation of new quaternary structures, and topological redesign of a chorismate mutase.[39][47][48] To develop enzymes with new activities, one can take advantage of promiscuous enzymes or enzymes with significant side reactions. In this regard, directed evolution has been used on γ-humulene synthase, an enzyme that creates over 50 different sesquiterpenes, to create enzymes that selectively synthesize individual products.[49] Similarly, completely new functions can be selected for from existing protein scaffolds. In one example of this, an RNA ligase was created from a zinc finger scaffold after 17 rounds of directed evolution. This new enzyme catalyzes a chemical reaction not known to be catalyzed by any natural enzyme.[50]
Computational methods, when combined with experimental approaches, can significantly assist both the design and redesign of new proteins through directed evolution. Computation has been used to design proteins with unnatural folds, such as a right-handed coiled coil.[51] These computational approaches could also be used to redesign proteins to selectively bind specific target molecules. By identifying lead sequences using computational methods, the occurrence of functional proteins in libraries can be dramatically increased before any directed evolution experiments in the laboratory.
Manfred T. Reetz, Frances Arnold, Donald Hilvert, and Jack W. Szostak are significant researchers in this field.
Biocompatible click cycloaddition reactions in chemical biology
Recent advances in technology have allowed scientists to view substructures of cells at levels of unprecedented detail. Unfortunately these "aerial" pictures offer little information about the mechanics of the biological system in question. To be fully effective, precise imaging systems require a complementary technique that better elucidates the machinery of a cell. By attaching tracking devices (optical probes) to biomolecules in vivo, one can learn far more about cell metabolism, molecular transport, cell-cell interactions and many other processes[52]
Bioorthogonal reactions
Successful labeling of a molecule of interest requires specific functionalization of that molecule to react chemospecifically with an optical probe. For a labeling experiment to be considered robust, that functionalization must minimally perturb the system.[53] Unfortunately, these requirements can often be extremely hard to meet. Many of the reactions normally available to organic chemists in the laboratory are unavailable in living systems. Water- and redox- sensitive reactions would not proceed, reagents prone to nucleophilic attack would offer no chemospecificity, and any reactions with large kinetic barriers would not find enough energy in the relatively low-heat environment of a living cell. Thus, chemists have recently developed a panel of bioorthogonal chemistry that proceed chemospecifically, despite the milieu of distracting reactive materials in vivo.
Design of bioorthogonal reagents and bioorthogonal chemical reporters
The coupling of an optical probe to a molecule of interest must occur within a reasonably short time frame; therefore, the kinetics of the coupling reaction should be highly favorable. Click chemistry is well suited to fill this niche, since click reactions are, by definition, rapid, spontaneous, selective, and high-yielding.[54] Unfortunately, the most famous "click reaction," a [3+2] cycloaddition between an azide and an acyclic alkyne, is copper-catalyzed, posing a serious problem for use in vivo due to copper's toxicity.[55]
The issue of copper toxicity can be alleviated using copper-chelating ligands, enabling copper-catalyzed labeling of the surface of live cells.[56]
To bypass the necessity for a catalyst, the lab of Dr. Carolyn Bertozzi introduced inherent strain into the alkyne species by using a cyclic alkyne. In particular, cyclooctyne reacts with azido-molecules with distinctive vigor.[57] Further optimization of the reaction led to the use of difluorinated cyclooctynes (DIFOs), which increased yield and reaction rate.[58] Other coupling partners discovered by separate labs to be analogous to cyclooctynes include trans cyclooctene,[59] norbornene,[60] and a cyclobutene-functionalized molecule.[61]
Use in biological systems
As mentioned above, the use of bioorthogonal reactions to tag biomolecules requires that one half of the reactive "click" pair is installed in the target molecule, while the other is attached to an optical probe. When the probe is added to a biological system, it will selectively conjugate with the target molecule.
The most common method of installing bioorthogonal reactivity into a target biomolecule is through metabolic labeling. Cells are immersed in a medium where access to nutrients is limited to synthetically modified analogues of standard fuels such as sugars. As a consequence, these altered biomolecules are incorporated into the cells in the same manner as their wild-type brethren. The optical probe is then incorporated into the system to image the fate of the altered biomolecules. Other methods of functionalization include enzymatically inserting azides into proteins,[62] and synthesizing phospholipids conjugated to cyclooctynes.[63]
Future directions
As these bioorthogonal reactions are further optimized, they will likely be used for increasingly complex interactions involving multiple different classes of biomolecules. More complex interactions have a smaller margin for error, so increased reaction efficiency is paramount to continued success in optically probing cellular machinery. Also, by minimizing side reactions, the experimental design of a minimally perturbed living system is closer to being realized.
Discovery of biomolecules through metagenomics
The advances in modern sequencing technologies in the late 1990s allowed scientists to investigate DNA of communities of organisms in their natural environments, so-called "eDNA", without culturing individual species in the lab. This metagenomic approach enabled scientists to study a wide selection of organisms that were previously not characterized due in part to an incompetent growth condition. These sources of eDNA include, but are not limited to, soils, ocean, subsurface, hot springs, hydrothermal vents, polar ice caps, hypersaline habitats, and extreme pH environments.[64] Of the many applications of metagenomics, chemical biologists and microbiologists such as Jo Handelsman, Jon Clardy, and Robert M. Goodman who are pioneers of metagenomics, explored metagenomic approaches toward the discovery of biologically active molecules such as antibiotics.[65]
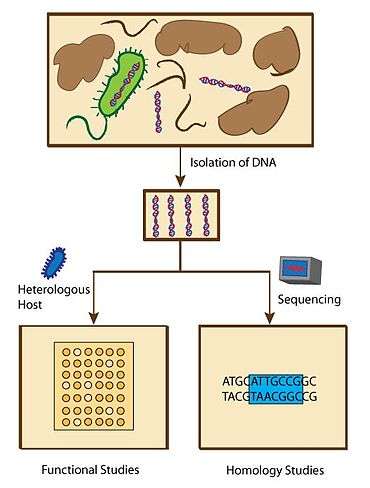
Functional or homology screening strategies have been used to identify genes that produce small bioactive molecules. Functional metagenomic studies are designed to search for specific phenotypes that are associated with molecules with specific characteristics. Homology metagenomic studies, on the other hand, are designed to examine genes to identify conserved sequences that are previously associated with the expression of biologically active molecules.[66]
Functional metagenomic studies enable scientists to discover novel genes that encode biologically active molecules. These assays include top agar overlay assays where antibiotics generate zones of growth inhibition against test microbes, and pH assays that can screen for pH change due to newly synthesized molecules using pH indicator on an agar plate.[67] Substrate-induced gene expression screening (SIGEX), a method to screen for the expression of genes that are induced by chemical compounds, has also been used to search genes with specific functions.[67] These led to the discovery and isolation of several novel proteins and small molecules. For example, the Schipper group identified three eDNA derived AHL lactonases that inhibit biofilm formation of Pseudomonas aeruginosa via functional metagenomic assays.[68] However, these functional screening methods require a good design of probes that detect molecules being synthesized and depend on the ability to express metagenomes in a host organism system.[67]
In contrast, homology metagenomic studies led to a faster discovery of genes that have homologous sequences as the previously known genes that are responsible for the biosynthesis of biologically active molecules. As soon as the genes are sequenced, scientists can compare thousands of bacterial genomes simultaneously.[66] The advantage over functional metagenomic assays is that homology metagenomic studies do not require a host organism system to express the metagenomes, thus this method can potentially save the time spent on analyzing nonfunctional genomes. These also led to the discovery of several novel proteins and small molecules. For example, Banik et al. screened for clones containing genes associated with the synthesis of teicoplanin and vancomycin-like glycopeptide antibiotics and found two new biosynthetic gene clusters.[69] In addition, an in silico examination from the Global Ocean Metagenomic Survey found 20 new lantibiotic cyclases.[70]
There are challenges to metagenomic approaches to discover new biologically active molecules. Only 40% of enzymatic activities present in a sample can be expressed in E. coli..[71] In addition, the purification and isolation of eDNA is essential but difficult when the sources of obtained samples are poorly understood. However, collaborative efforts from individuals from diverse fields including bacterial genetics, molecular biology, genomics, bioinformatics, robots, synthetic biology, and chemistry can solve this problem together and potentially lead to the discovery of many important biologically active molecules.[66]
Protein phosphorylation
Posttranslational modification of proteins with phosphate groups has proven to be a key regulatory step throughout all biological systems. Phosphorylation events, either phosphorylation by protein kinases or dephosphorylation by phosphatases, result in protein activation or deactivation. These events have an immense impact on the regulation of physiological pathways, which makes the ability to dissect and study these pathways integral to understanding the details of cellular processes. There exist a number of challenges—namely the sheer size of the phosphoproteome, the fleeting nature of phosphorylation events and related physical limitations of classical biological and biochemical techniques—that have limited the advancement of knowledge in this area. A recent review[72] provides a detailed examination of the impact of newly developed chemical approaches to dissecting and studying biological systems both in vitro and in vivo.
Through the use of a number of classes of small molecule modulators of protein kinases, chemical biologists have been able to gain a better understanding of the effects of protein phosphorylation. For example, nonselective and selective kinase inhibitors, such as a class of pyridinylimidazole compounds described by Wilson, et al.,[73] are potent inhibitors useful in the dissection of MAP kinase signaling pathways. These pyridinylimidazole compounds function by targeting the ATP binding pocket. Although this approach, as well as related approaches,[74][75] with slight modifications, has proven effective in a number of cases, these compounds lack adequate specificity for more general applications. Another class of compounds, mechanism-based inhibitors, combines detailed knowledge of the chemical mechanism of kinase action with previously utilized inhibition motifs. For example, Parang, et al. describe the development of a "bisubstrate analog" that inhibits kinase action by binding both the conserved ATP binding pocket and a protein/peptide recognition site on the specific kinase.[76] While there is no published in vivo data on compounds of this type, the structural data acquired from in vitro studies have expanded the current understanding of how a number of important kinases recognize target substrates. Many research groups utilized ATP analogs as a chemical probe to study kinases and identify their substrates.[77][78][79]
The development of novel chemical means of incorporating phosphomimetics into proteins has provided important insight into the effects of phosphorylation events. Historically, phosphorylation events have been studied by mutating an identified phosphorylation site (serine, threonine or tyrosine) to an amino acid, such as alanine, that cannot be phosphorylated. While this approach has been successful in some cases, mutations are permanent in vivo and can have potentially detrimental effects on protein folding and stability. Thus, chemical biologists have developed new ways of investigating protein phosphorylation. By installing phospho-serine, phospho-threonine or analogous phosphonate mimics into native proteins, researchers are able to perform in vivo studies to investigate the effects of phosphorylation by extending the amount of time a phosphorylation event occurs while minimizing the often-unfavorable effects of mutations. Protein semisynthesis, or more specifically expressed protein ligation (EPL), has proven to be successful techniques for synthetically producing proteins that contain phosphomimetic molecules at either the C- or the N-terminus.[32] In addition, researchers have built upon an established technique in which one can insert an unnatural amino acid into a peptide sequence by charging synthetic tRNA that recognizes a nonsense codon with an unnatural amino acid.[80] Recent developments indicate that this technique can also be employed in vivo, although, due to permeability issues, these in vivo experiments using phosphomimetic molecules have not yet been possible.[81]
Advances in chemical biology have also improved upon classical techniques of imaging kinase action. For example, the development of peptide biosensors—peptides containing incorporated fluorophore molecules—allowed for improved temporal resolution in in vitro binding assays.[82] Experimental limitations, however, prevent this technique from being effectively used in vivo. One of the most useful techniques to study kinase action is Fluorescence Resonance Energy Transfer (FRET). To utilize FRET for phosphorylation studies, fluorescent proteins are coupled to both a phosphoamino acid binding domain and a peptide that can by phosphorylated. Upon phosphorylation or dephosphorylation of a substrate peptide, a conformational change occurs that results in a change in fluorescence.[83] FRET has also been used in tandem with Fluorescence Lifetime Imaging Microscopy (FLIM)[84] or fluorescently conjugated antibodies and flow cytometry[85] to provide a detailed, specific, quantitative results with excellent temporal and spatial resolution.
Through the augmentation of classical biochemical methods as well as the development of new tools and techniques, chemical biologists have improved accuracy and precision in the study of protein phosphorylation.
Chemical approaches to stem-cell biology
Advances in stem-cell biology have typically been driven by discoveries in molecular biology and genetics. These have included optimization of culture conditions for the maintenance and differentiation of pluripotent and multipotent stem-cells and the deciphering of signaling circuits that control stem-cell fate. However, chemical approaches to stem-cell biology have recently received increased attention due to the identification of several small molecules capable of modulating stem-cell fate in vitro.[86] A small molecule approach offers particular advantages over traditional methods in that it allows a high degree of temporal control, since compounds can be added or removed at will, and tandem inhibition/activation of multiple cellular targets.
Small molecules that modulate stem-cell behavior are commonly identified in high-throughput screens. Libraries of compounds are screened for the induction of a desired phenotypic change in cultured stem-cells. This is usually observed through activation or repression of a fluorescent reporter or by detection of specific cell surface markers by FACS or immunohistochemistry. Hits are then structurally optimized for activity by the synthesis and screening of secondary libraries. The cellular targets of the small molecule can then be identified by affinity chromatography, mass spectrometry, or DNA microarray.
A trademark of pluripotent stem-cells, such as embryonic stem-cells (ESCs), is the ability to self-renew indefinitely. The conventional use of feeder cells and various exogenous growth factors in the culture of ESCs presents a problem in that the resulting highly variable culture conditions make the long-term expansion of un-differentiated ESCs challenging.[87] Ideally, chemically defined culture conditions could be developed to maintain ESCs in a pluripotent state indefinitely. Toward this goal, the Schultz and Ding labs at the Scripps Research Institute identified a small molecule that can preserve the long-term self-renewal of ESCs in the absence of feeder cells and other exogenous growth factors.[88] This novel molecule, called pluripotin, was found to simultaneously inhibit multiple differentiation inducing pathways.
The utility of stem-cells is in their ability to differentiate into all cell types that make up an organism. Differentiation can be achieved in vitro by favoring development toward a particular cell type through the addition of lineage specific growth factors, but this process is typically non-specific and generates low yields of the desired phenotype. Alternatively, inducing differentiation by small molecules is advantageous in that it allows for the development of completely chemically defined conditions for the generation of one specific cell type. A small molecule, neuropathiazol, has been identified which can specifically direct differentiation of multipotent neural stem cells into neurons.[89] Neuropathiazol is so potent that neurons develop even in conditions that normally favor the formation of glial cells, a powerful demonstration of controlling differentiation by chemical means.
Because of the ethical issues surrounding ESC research, the generation of pluripotent cells by reprogramming existing somatic cells into a more "stem-like" state is a promising alternative to the use of standard ESCs. By genetic approaches, this has recently been achieved in the creation of ESCs by somatic cell nuclear transfer[90] and the generation of induced pluripotent stem-cells by viral transduction of specific genes.[91] From a therapeutic perspective, reprogramming by chemical means would be safer than genetic methods because induced stem-cells would be free of potentially dangerous transgenes.[92] Several examples of small molecules that can de-differentiate somatic cells have been identified. In one report, lineage-committed myoblasts were treated with a compound, named reversine, and observed to revert to a more stem-like phenotype.[93] These cells were then shown to be capable of differentiating into osteoblasts and adipocytes under appropriate conditions.[94]
Stem-cell therapies are currently the most promising treatment for many degenerative diseases. Chemical approaches to stem-cell biology support the development of cell-based therapies by enhancing stem-cell growth, maintenance, and differentiation in vitro. Small molecules that have been shown to modulate stem-cell fate are potential therapeutic candidates and provide a natural lean-in to pre-clinical drug development. Small molecule drugs could promote endogenous stem-cells to differentiate, replacing previously damaged tissues and thereby enhancing the body's own regenerative ability. Further investigation of molecules that modulate stem-cell behavior will only unveil new therapeutic targets.
Fluorescence for assessing protein location and function
Fluorophores and techniques to tag proteins
Organisms are composed of cells that, in turn, are composed of macromolecules, e.g. proteins, ribosomes, etc. These macromolecules interact with each other, changing their concentration and suffering chemical modifications. The main goal of many biologists is to understand these interactions, using MRI, ESR, electrochemistry, and fluorescence among others. The advantages of fluorescence reside in its high sensitivity, non-invasiveness, safe detection, and ability to modulate the fluorescence signal. Fluorescence was observed mainly from small organic dyes attached to antibodies to the protein of interest. Later, fluorophores could directly recognize organelles, nucleic acids, and important ions in living cells. In the past decade, the discovery of green fluorescent protein (GFP), by Roger Y. Tsien, hybrid system and quantum dots have enable assessing protein location and function more precisely.[95] Three main types of fluorophores are used: small organic dyes, green fluorescent proteins, and quantum dots. Small organic dyes usually are less than 1 kD, and have been modified to increase photostability, enhance brightness, and reduce self-quenching. Quantum dots have very sharp wavelength, high molar absorptivity and quantum yield. Both organic dyes and quantum dyes do not have the ability to recognize the protein of interest without the aid of antibodies, hence they must use immunolabeling. Since the size of the fluorophore-targeting complex typically exceeds 200 kD, it might interfere with multiprotein recognition in protein complexes, and other methods should be use in parallel. An advantage includes diversity of properties and a limitation is the ability of targeting in live cells. Green fluorescent proteins are genetically encoded and can be covalently fused to your protein of interest. A more developed genetic tagging technique is the tetracysteine biarsenical system, which requires modification of the targeted sequence that includes four cysteines, which binds membrane-permeable biarsenical molecules, the green and the red dyes "FlAsH" and "ReAsH", with picomolar affinity. Both fluorescent proteins and biarsenical tetracysteine can be expressed in live cells, but present major limitations in ectopic expression and might cause lose of function. Giepmans shows parallel applications of targeting methods and fluorophores using GFP and tetracysteine with ReAsH for α-tubulin and β-actin, respectively. After fixation, cells were immunolabeled for the Golgi matrix with QD and for the mitochondrial enzyme cytochrome with Cy5.[95]
Protein dynamics
Fluorescent techniques have been used assess a number of protein dynamics including protein tracking, conformational changes, protein–protein interactions, protein synthesis and turnover, and enzyme activity, among others.
Three general approaches for measuring protein net redistribution and diffusion are single-particle tracking, correlation spectroscopy and photomarking methods. In single-particle tracking, the individual molecule must be both bright and sparse enough to be tracked from one video to the other. Correlation spectroscopy analyzes the intensity fluctuations resulting from migration of fluorescent objects into and out of a small volume at the focus of a laser. In photomarking, a fluorescent protein can be dequenched in a subcellular area with the use of intense local illumination and the fate of the marked molecule can be imaged directly. Michalet and coworkers used quantum dots for single-particle tracking using biotin-quantum dots in HeLa cells.[96]
One of the best ways to detect conformational changes in proteins is to sandwich said protein between two fluorophores. FRET will respond to internal conformational changes result from reorientation of the fluorophore with respect to the other. Dumbrepatil sandwiched an estrogen receptor between a CFP (cyan fluorescent protein) and a YFP (yellow fluorescent protein) to study conformational changes of the receptor upon binding of a ligand.[97]
Fluorophores of different colors can be applied to detect their respective antigens within the cell. If antigens are located close enough to each other, they will appear colocalized and this phenomenon is known as colocalization.[98] Specialized computer software, such as CoLocalizer Pro, can be used to confirm and characterize the degree of colocalization.
FRET can detect dynamic protein–protein interaction in live cells providing the fluorophores get close enough. Galperin et al. used three fluorescent proteins to study multiprotein interactions in live cells.[99]
Tetracysteine biarsenical systems can be used to study protein synthesis and turnover, which requires discrimination of old copies from new copies. In principle, a tetracysteine-tagged protein is labeled with FlAsH for a short time, leaving green labeled proteins. The protein synthesis is then carried out in the presence of ReAsH, labeling the new proteins as red.[100]
One can also use fluorescence to see endogenous enzyme activity, typically by using a quenched activity based proteomics (qABP). Covalent binding of a qABP to the active site of the targeted enzyme will provide direct evidence concerning if the enzyme is responsible for the signal upon release of the quencher and regain of fluorescence.[101]
The unique combination of high spatial and temporal resolution, nondestructive compatibility with living cells and organisms, and molecular specificity insure that fluorescence techniques will remain central in the analysis of protein networks and systems biology.[95]
See also
References
- ↑ Cox Jü, Mann M (2007). "Is Proteomics the New Genomics?". Cell. 130 (3): 395–8. doi:10.1016/j.cell.2007.07.032. PMID 17693247.
- ↑ Zhao Y, Jensen ON (October 2009). "Modification-specific proteomics: strategies for characterization of post-translational modifications using enrichment techniques". Proteomics. 9 (20): 4632–41. doi:10.1002/pmic.200900398. PMC 2892724. PMID 19743430.
- ↑ Gingras A-C, Gstaiger M, Raught B, Aebersold R (2007). "Analysis of protein complexes using mass spectrometry". Nature Reviews Molecular Cell Biology. 8 (8): 645–54. doi:10.1038/nrm2208. PMID 17593931.
- ↑ Chin JW, Schultz PG (November 2002). "In vivo photocrosslinking with unnatural amino Acid mutagenesis". Chembiochem. 3 (11): 1135–7. doi:10.1002/1439-7633(20021104)3:11<1135::AID-CBIC1135>3.0.CO;2-M. PMID 12404640.
- ↑ Liu W, Brock A, Chen S, Chen S, Schultz PG (2007). "Genetic incorporation of unnatural amino acids into proteins in mammalian cells". Nature Methods. 4 (3): 239–44. doi:10.1038/nmeth1016. PMID 17322890.
- ↑ López-Otín C, Overall CM (2002). "Protease degradomics: A new challenge for proteomics". Nature Reviews Molecular Cell Biology. 3 (7): 509–19. doi:10.1038/nrm858. PMID 12094217.
- ↑ Adam GC, Cravatt BF, Sorensen EJ (January 2001). "Profiling the specific reactivity of the proteome with non-directed activity-based probes". Chem. Biol. 8 (1): 81–95. doi:10.1016/S1074-5521(00)90060-7. PMID 11182321.
- ↑ Tureček F (2002). "Mass spectrometry in coupling with affinity capture-release and isotope-coded affinity tags for quantitative protein analysis". Journal of Mass Spectrometry. 37 (1): 1–14. Bibcode:2002JMSp...37....1T. doi:10.1002/jms.275. PMID 11813306.
- ↑ Warmerdam A, Boom RM, Janssen AE (2013-08-27). "β-galactosidase stability at high substrate concentrations". SpringerPlus. 2: 402. doi:10.1186/2193-1801-2-402. PMC 3765595. PMID 24024090.
- ↑ Blethrow J, Zhang C, Shokat KM, Weiss EL (May 2004). "Design and use of analog-sensitive protein kinases". Curr Protoc Mol Biol. Chapter 18: Unit 18.11. doi:10.1002/0471142727.mb1811s66. PMID 18265343.
- ↑ Lavis LD (2008). "Bright Ideas for Chemical Biology". ACS Chemical Biology. 3: 142–155. doi:10.1021/cb700248m.
- ↑ The Nobel Prize in Chemistry 2008
- ↑ Cermakova K, Hodges HC (August 2018). "Next-Generation Drugs and Probes for Chromatin Biology: From Targeted Protein Degradation to Phase Separation". Molecules. 23 (8). doi:10.3390/molecules23081958. PMC 6102721. PMID 30082609.
- ↑ Jordens S, Adamcik J, Amar-Yuli I, Mezzenga R (2011). "Disassembly and Reassembly of Amyloid Fibrils in Water−Ethanol Mixtures". Biomacromolecules. 12 (1): 187–93. doi:10.1021/bm101119t. PMID 21142059.
- ↑ Reddy G, Straub JE, Thirumalai D (December 2010). "Dry amyloid fibril assembly in a yeast prion peptide is mediated by long-lived structures containing water wires". Proc. Natl. Acad. Sci. USA. 107 (50): 21459–64. Bibcode:2010PNAS..10721459R. doi:10.1073/pnas.1008616107. PMC 3003024. PMID 21098298.
- ↑ Borman SA (2010). "Water Factors in on Amyloid And Prion Aggregation Rates". Chemical & Engineering News. 88 (49): 37.
- 1 2 Luheshi LM, Crowther DC, Dobson CM (2008). "Protein misfolding and disease: from the test tube to the organism". Current Opinion in Chemical Biology. 12 (1): 25–31. doi:10.1016/j.cbpa.2008.02.011. PMID 18295611.
- ↑ Luheshi LM, Tartaglia GG, Brorsson A-C, Pawar AP, Watson IE, Chiti F, Vendruscolo M, Lomas DA, Dobson CM (2007). "Systematic in Vivo Analysis of the Intrinsic Determinants of Amyloid β Pathogenicity". PLoS Biology. 5 (11): e290. doi:10.1371/journal.pbio.0050290. PMC 2043051. PMID 17973577.
- ↑ Crowther DC, Kinghorn KJ, Miranda E, Page R, Curry JA, Duthie FAI, Gubb DC, Lomas DA (2005). "Intraneuronal Aβ, non-amyloid aggregates and neurodegeneration in a Drosophila model of Alzheimer's disease". Neuroscience. 132 (1): 123–35. doi:10.1016/j.neuroscience.2004.12.025. PMID 15780472.
- ↑ Hammarström P, Sekijima Y, White JT, Wiseman RL, Lim A, Costello CE, Altland K, Garzuly F, Budka H (2003). "D18G Transthyretin is Monomeric, Aggregation Prone, and Not Detectable in Plasma and Cerebrospinal Fluid: A Prescription for Central Nervous System Amyloidosis?†". Biochemistry. 42 (22): 6656–63. doi:10.1021/bi027319b. PMID 12779320.
- ↑ Sekijima Y, Wiseman RL, Matteson J, Hammarström P, Miller SR, Sawkar AR, Balch WE, Kelly JW (2005). "The Biological and Chemical Basis for Tissue-Selective Amyloid Disease". Cell. 121 (1): 73–85. doi:10.1016/j.cell.2005.01.018. PMID 15820680.
- ↑ Gidalevitz T, Ben-Zvi A, Ho KH, Brignull HR, Morimoto RI (2006). "Progressive Disruption of Cellular Protein Folding in Models of Polyglutamine Diseases". Science. 311 (5766): 1471–1474. Bibcode:2006Sci...311.1471G. doi:10.1126/science.1124514. PMID 16469881.
- ↑ Cohen E, Bieschke J, Perciavalle RM, Kelly JW, Dillin A (2006). "Opposing Activities Protect Against Age-Onset Proteotoxicity". Science. 313 (5793): 1604–1610. Bibcode:2006Sci...313.1604C. doi:10.1126/science.1124646. PMID 16902091.
- ↑ Ramirez-Alvarado, M., Kelly, J. W., and Dobson, C. M., (Eds.) (2010) Protein Misfolding Diseases Current and Emerging Principles and Therapies, John Wiley and Sons, Hoboken
- 1 2 Kimmerlin T, Seebach D (2005). "'100 years of peptide synthesis': ligation methods for peptide and protein synthesis with applications to beta-peptide assemblies". J Pept Res. 65 (2): 229–260. doi:10.1111/j.1399-3011.2005.00214.x. PMID 15705167.
- 1 2 Kent S (June 2006). "Obituary: Bruce Merrifield (1921–2006)". Nature. 441 (7095): 824. Bibcode:2006Natur.441..824K. doi:10.1038/441824a. PMID 16778881.
- ↑ Dirksen A, Dawson PE (2008). "Expanding the scope of chemoselective peptide ligations in chemical biology". Current Opinion in Chemical Biology. 12 (6): 760–6. doi:10.1016/j.cbpa.2008.10.009. PMID 19058994.
- ↑ Dawson PE, Muir TW, Clarklewis I, Kent SBH (1994). "SYNTHESIS OF PROTEINS BY NATIVE CHEMICAL LIGATION". Science. 266 (5186): 776–779. Bibcode:1994Sci...266..776D. doi:10.1126/science.7973629. PMID 7973629.
- ↑ Torbeev VY, Kent SB (2007). "Convergent chemical synthesis and crystal structure of a 203 amino acid "covalent dimer" HIV-1 protease enzyme molecule". Angew. Chem. Int. Ed. Engl. 46 (10): 1667–70. doi:10.1002/anie.200604087. PMID 17397076.
- ↑ Durek T, Torbeev VY, Kent SB (March 2007). "Convergent chemical synthesis and high-resolution x-ray structure of human lysozyme". Proc. Natl. Acad. Sci. USA. 104 (12): 4846–51. Bibcode:2007PNAS..104.4846D. doi:10.1073/pnas.0610630104. PMC 1829227. PMID 17360367.
- ↑ McCaldon P, Argos P (1988). "Oligopeptide biases in protein sequences and their use in predicting protein coding regions in nucleotide sequences". Proteins. 4 (2): 99–122. doi:10.1002/prot.340040204. PMID 3227018.
- 1 2 Muir TW, Sondhi D, Cole PA (June 1998). "Expressed protein ligation: a general method for protein engineering". Proc. Natl. Acad. Sci. USA. 95 (12): 6705–10. Bibcode:1998PNAS...95.6705M. doi:10.1073/pnas.95.12.6705. PMC 22605. PMID 9618476.
- ↑ Wu B, Chen J, Warren JD, Chen G, Hua Z, Danishefsky SJ (June 2006). "Building complex glycopeptides: Development of a cysteine-free native chemical ligation protocol". Angew. Chem. Int. Ed. Engl. 45 (25): 4116–25. doi:10.1002/anie.200600538. PMID 16710874.
- ↑ Chatterjee C, McGinty RK, Pellois JP, Muir TW (2007). "Auxiliary-mediated site-specific peptide ubiquitylation". Angew. Chem. Int. Ed. Engl. 46 (16): 2814–8. doi:10.1002/anie.200605155. PMID 17366504.
- ↑ Soellner MB, Nilsson BL, Raines RT (July 2006). "Reaction mechanism and kinetics of the traceless Staudinger ligation". J. Am. Chem. Soc. 128 (27): 8820–8. doi:10.1021/ja060484k. PMID 16819875.
- ↑ Punna S, Kuzelka J, Wang Q, Finn MG (April 2005). "Head-to-tail peptide cyclodimerization by copper-catalyzed azide-alkyne cycloaddition". Angew. Chem. Int. Ed. Engl. 44 (15): 2215–20. doi:10.1002/anie.200461656. PMID 15693048.
- ↑ Dirksen A, Hackeng TM, Dawson PE (November 2006). "Nucleophilic catalysis of oxime ligation". Angew. Chem. Int. Ed. Engl. 45 (45): 7581–4. doi:10.1002/anie.200602877. PMID 17051631.
- ↑ Jäckel C, Kast P, Hilvert D (2008). "Protein design by directed evolution". Annu Rev Biophys. 37: 153–73. doi:10.1146/annurev.biophys.37.032807.125832. PMID 18573077.
- 1 2 Taylor SV, Walter KU, Kast P, Hilvert D (September 2001). "Searching sequence space for protein catalysts". Proc. Natl. Acad. Sci. USA. 98 (19): 10596–601. Bibcode:2001PNAS...9810596T. doi:10.1073/pnas.191159298. PMC 58511. PMID 11535813.
- ↑ Bittker JA, Le BV, Liu JM, Liu DR (May 2004). "Directed evolution of protein enzymes using nonhomologous random recombination". Proc. Natl. Acad. Sci. USA. 101 (18): 7011–6. Bibcode:2004PNAS..101.7011B. doi:10.1073/pnas.0402202101. PMC 406457. PMID 15118093.
- ↑ Aharoni A, Griffiths AD, Tawfik DS (April 2005). "High-throughput screens and selections of enzyme-encoding genes". Curr Opin Chem Biol. 9 (2): 210–6. doi:10.1016/j.cbpa.2005.02.002. PMID 15811807.
- ↑ Wilson DS, Keefe AD, Szostak JW (March 2001). "The use of mRNA display to select high-affinity protein-binding peptides". Proc. Natl. Acad. Sci. USA. 98 (7): 3750–5. Bibcode:2001PNAS...98.3750W. doi:10.1073/pnas.061028198. PMC 31124. PMID 11274392.
- ↑ Tawfik DS, Griffiths AD (1998). "Man-made cell-like compartments for molecular evolution". Nature Biotechnology. 16 (7): 652–6. doi:10.1038/nbt0798-652. PMID 9661199.
- ↑ Lo Surdo P, Walsh MA, Sollazzo M (April 2004). "A novel ADP- and zinc-binding fold from function-directed in vitro evolution". Nature Structural & Molecular Biology. 11 (4): 382–3. doi:10.1038/nsmb745. PMID 15024384.
- ↑ Kamtekar S, Schiffer JM, Xiong HY, Babik JM, Hecht MH (1993). "Protein Design by Binary Patterning of Polar and Nonpolar Amino-acids". Science. 262 (5140): 1680–1685. Bibcode:1993Sci...262.1680K. doi:10.1126/science.8259512. PMID 8259512.
- ↑ Wei Y, Kim S, Fela D, Baum J, Hecht MH (November 2003). "Solution structure of a de novo protein from a designed combinatorial library". Proc. Natl. Acad. Sci. USA. 100 (23): 13270–3. Bibcode:2003PNAS..10013270W. doi:10.1073/pnas.1835644100. PMC 263778. PMID 14593201.
- ↑ Vamvaca K, Butz M, Walter KU, Taylor SV, Hilvert D (2005). "Simultaneous optimization of enzyme activity and quaternary structure by directed evolution". Protein Science. 14 (8): 2103–14. doi:10.1110/ps.051431605. PMC 2279322. PMID 15987889.
- ↑ MacBeath G, Kast P, Hilvert D (1998). "Redesigning enzyme topology by directed evolution". Science. 279 (5358): 1958–1961. Bibcode:1998Sci...279.1958M. doi:10.1126/science.279.5358.1958. PMID 9506949.
- ↑ Yoshikuni Y, Ferrin TE, Keasling JD (2006). "Designed divergent evolution of enzyme function". Nature. 440 (7087): 1078–1082. Bibcode:2006Natur.440.1078Y. doi:10.1038/nature04607. PMID 16495946.
- ↑ Seelig B, Szostak JW (2007). "Selection and evolution of enzymes from a partially randomized non-catalytic scaffold". Nature. 448 (7155): 828–31. Bibcode:2007Natur.448..828S. doi:10.1038/nature06032. PMC 4476047. PMID 17700701.
- ↑ Harbury PB, Plecs JJ, Tidor B, Alber T, Kim PS (1998). "High-resolution protein design with backbone freedom". Science. 282 (5393): 1462–1467. doi:10.1126/science.282.5393.1462. PMID 9822371.
- ↑ Jewett JC, Bertozzi CR (2010). "Cu-free click cycloaddition reactions in chemical biology". Chemical Society Reviews. 39 (4): 1272–9. doi:10.1039/b901970g. PMC 2865253. PMID 20349533. .
- ↑ Sletten EM, Bertozzi CR (2009). "Bioorthogonal chemistry: fishing for selectivity in a sea of functionality". Angew. Chem. Int. Ed. Engl. 48 (38): 6974–98. doi:10.1002/anie.200900942. PMC 2864149. PMID 19714693.
- ↑ Kolb HC, Finn MG, Sharpless KB (June 2001). "Click Chemistry: Diverse Chemical Function from a Few Good Reactions". Angew. Chem. Int. Ed. Engl. 40 (11): 2004–2021. doi:10.1002/1521-3773(20010601)40:11<2004::AID-ANIE2004>3.0.CO;2-5. PMID 11433435.
- ↑ Rostovtsev VV, Green LG, Fokin VV, Sharpless KB (July 2002). "A stepwise huisgen cycloaddition process: copper(I)-catalyzed regioselective "ligation" of azides and terminal alkynes". Angew. Chem. Int. Ed. Engl. 41 (14): 2596–9. doi:10.1002/1521-3773(20020715)41:14<2596::AID-ANIE2596>3.0.CO;2-4. PMID 12203546.
- ↑ Hong V, Steinmetz NF, Manchester M, Finn MG (2010). "Labeling Live Cells by Copper-Catalyzed Alkyne−Azide Click Chemistry". Bioconjugate Chemistry. 21 (10): 1912–6. doi:10.1021/bc100272z. PMC 3014321. PMID 20886827.
- ↑ Agard NJ, Prescher JA, Bertozzi CR (November 2004). "A strain-promoted [3 + 2] azide-alkyne cycloaddition for covalent modification of biomolecules in living systems". J. Am. Chem. Soc. 126 (46): 15046–7. doi:10.1021/ja044996f. PMID 15547999.
- ↑ Baskin JM, Prescher JA, Laughlin ST, Agard NJ, Chang PV, Miller IA, Lo A, Codelli JA, Bertozzi CR (October 2007). "Copper-free click chemistry for dynamic in vivo imaging". Proc. Natl. Acad. Sci. USA. 104 (43): 16793–7. Bibcode:2007PNAS..10416793B. doi:10.1073/pnas.0707090104. PMC 2040404. PMID 17942682.
- ↑ Blackman ML, Royzen M, Fox JM (2008). "Tetrazine Ligation: Fast Bioconjugation Based on Inverse-Electron-Demand Diels−Alder Reactivity". Journal of the American Chemical Society. 130 (41): 13518–9. doi:10.1021/ja8053805. PMC 2653060. PMID 18798613.
- ↑ Devaraj NK, Weissleder R, Hilderbrand SA (2008). "Tetrazine-Based Cycloadditions: Application to Pretargeted Live Cell Imaging". Bioconjugate Chemistry. 19 (12): 2297–9. doi:10.1021/bc8004446. PMC 2677645. PMID 19053305.
- ↑ Pipkorn Rü, Waldeck W, Didinger B, Koch M, Mueller G, Wiessler M, Braun K (2009). "Inverse-electron-demand Diels-Alder reaction as a highly efficient chemoselective ligation procedure: Synthesis and function of a BioShuttle for temozolomide transport into prostate cancer cells". Journal of Peptide Science. 15 (3): 235–41. doi:10.1002/psc.1108. PMID 19177421.
- ↑ Hur GH, Meier JL, Baskin J, Codelli JA, Bertozzi CR, Marahiel MA, Burkart MD (April 2009). "Crosslinking studies of protein–protein interactions in nonribosomal peptide biosynthesis". Chem. Biol. 16 (4): 372–81. doi:10.1016/j.chembiol.2009.02.009. PMC 2743379. PMID 19345117.
- ↑ Neef AB, Schultz C (2009). "Selective fluorescence labeling of lipids in living cells". Angew. Chem. Int. Ed. Engl. 48 (8): 1498–500. doi:10.1002/anie.200805507. PMID 19145623.
- ↑ Keller M, Zengler K (February 2004). "Tapping into microbial diversity". Nature Reviews Microbiology. 2 (2): 141–50. doi:10.1038/nrmicro819. PMID 15040261.
- ↑ Handelsman J, Rondon MR, Brady SF, Clardy J, Goodman RM (October 1998). "Molecular biological access to the chemistry of unknown soil microbes: a new frontier for natural products". Chem. Biol. 5 (10): R245–9. doi:10.1016/S1074-5521(98)90108-9. PMID 9818143.
- 1 2 3 Banik JJ, Brady SF (2010). "Recent application of metagenomic approaches toward the discovery of antimicrobials and other bioactive small molecules". Current Opinion in Microbiology. 13 (5): 603–609. doi:10.1016/j.mib.2010.08.012. PMC 3111150. PMID 20884282.
- 1 2 3 Daniel R (2005). "The metagenomics of soil". Nature Reviews Microbiology. 3 (6): 470–478. doi:10.1038/nrmicro1160. PMID 15931165.
- ↑ Schipper C, Hornung C, Bijtenhoorn P, Quitschau M, Grond S, Streit WR (2009). "Metagenome-Derived Clones Encoding Two Novel Lactonase Family Proteins Involved in Biofilm Inhibition in Pseudomonas aeruginosa". Applied and Environmental Microbiology. 75 (1): 224–233. doi:10.1128/AEM.01389-08. PMC 2612230. PMID 18997026.
- ↑ Bunterngsook B, Kanokratana P, Thongaram T, Tanapongpipat S, Uengwetwanit T, Rachdawong S, Vichitsoonthonkul T, Eurwilaichitr L (2010). "Identification and characterization of lipolytic enzymes from a peat-swamp forest soil metagenome". Biosci. Biotechnol. Biochem. 74 (9): 1848–54. doi:10.1271/bbb.100249. PMID 20834152.
- ↑ Li B, Sher D, Kelly L, Shi YX, Huang K, Knerr PJ, Joewono I, Rusch D, Chisholm SW (2010). "Catalytic promiscuity in the biosynthesis of cyclic peptide secondary metabolites in planktonic marine cyanobacteria". Proceedings of the National Academy of Sciences of the United States of America. 107 (23): 10430–10435. Bibcode:2010PNAS..10710430L. doi:10.1073/pnas.0913677107. PMC 2890784. PMID 20479271.
- ↑ Gabor EM, Alkema WBL, Janssen DB (2004). "Quantifying the accessibility of the metagenome by random expression cloning techniques". Environmental Microbiology. 6 (9): 879–86. doi:10.1111/j.1462-2920.2004.00640.x. PMID 15305913.
- ↑ Tarrant MK, Cole PA (2009). "The Chemical Biology of Protein Phosphorylation". Annual Review of Biochemistry. 78: 797–825. doi:10.1146/annurev.biochem.78.070907.103047. PMC 3074175. PMID 19489734.
- ↑ Wilson KP, McCaffrey PG, Hsiao K, Pazhanisamy S, Galullo V, Bemis GW, Fitzgibbon MJ, Caron PR, Murcko MA, Su MS (June 1997). "The structural basis for the specificity of pyridinylimidazole inhibitors of p38 MAP kinase". Chemistry & Biology. 4 (6): 423–31. doi:10.1016/S1074-5521(97)90194-0. PMID 9224565.
- ↑ Pargellis C, Tong L, Churchill L, Cirillo PF, Gilmore T, Graham AG, Grob PM, Hickey ER, Moss N, Pav S, Regan J (April 2002). "Inhibition of p38 MAP kinase by utilizing a novel allosteric binding site". Nature Structural Biology. 9 (4): 268–72. doi:10.1038/nsb770. PMID 11896401.
- ↑ Schindler T, Bornmann W, Pellicena P, Miller WT, Clarkson B, Kuriyan J (September 2000). "Structural mechanism for STI-571 inhibition of abelson tyrosine kinase". Science. 289 (5486): 1938–42. Bibcode:2000Sci...289.1938S. doi:10.1126/science.289.5486.1938. PMID 10988075.
- ↑ Parang K, Till JH, Ablooglu AJ, Kohanski RA, Hubbard SR, Cole PA (January 2001). "Mechanism-based design of a protein kinase inhibitor". Nature Structural Biology. 8 (1): 37–41. doi:10.1038/83028. PMID 11135668.
- ↑ Fouda AE, Pflum MK (August 2015). "A Cell-Permeable ATP Analogue for Kinase-Catalyzed Biotinylation". Angewandte Chemie. 54 (33): 9618–21. doi:10.1002/anie.201503041. PMC 4551444. PMID 26119262.
- ↑ Senevirathne C, Embogama DM, Anthony TA, Fouda AE, Pflum MK (January 2016). "The generality of kinase-catalyzed biotinylation". Bioorganic & Medicinal Chemistry. 24 (1): 12–9. doi:10.1016/j.bmc.2015.11.029. PMC 4921744. PMID 26672511.
- ↑ Anthony TM, Dedigama-Arachchige PM, Embogama DM, Faner TR, Fouda AE, Pflum MK (2015). "ATP Analogs in Protein Kinase Research". In Kraatz H, Martic S. Kinomics: Approaches and Applications. pp. 137–68. doi:10.1002/9783527683031.ch6. ISBN 978-3-527-68303-1.
- ↑ Noren CJ, Anthony-Cahill SJ, Griffith MC, Schultz PG (1989). "A general method for site-specific incorporation of unnatural amino acids into proteins". Science. 244 (4901): 182–188. Bibcode:1989Sci...244..182N. doi:10.1126/science.2649980. PMID 2649980.
- ↑ Wang L, Xie J, Schultz PG (2006). "Expanding the genetic code". Annu Rev Biophys Biomol Struct. 35: 225–49. doi:10.1146/annurev.biophys.35.101105.121507. PMID 16689635.
- ↑ Sharma V, Wang Q, Lawrence DS (January 2008). "Peptide-based fluorescent sensors of protein kinase activity: design and applications". Biochim. Biophys. Acta. 1784 (1): 94–9. doi:10.1016/j.bbapap.2007.07.016. PMC 2684651. PMID 17881302.
- ↑ Violin JD, Zhang J, Tsein RY, Newton AC (2003). "A genetically encoded fluorescent reporter reveals oscillatory phosphorylation by protein kinase C". J. Cell Biol. 161 (5): 899–909. doi:10.1083/jcb.200302125. PMC 2172956. PMID 12782683.
- ↑ Verveer PJ, Wouters FS, Hansra G, Bornancin F, Bastiaens PI (2000). "Quantitative imaging of lateral ERbB1 receptor signal propagation in the plasma membrane". Science. 290 (5496): 1567–1570. Bibcode:2000Sci...290.1567V. doi:10.1126/science.290.5496.1567. PMID 11090353.
- ↑ Muller S, Demotz S, Bulliard C, Valitutti S (1999). "Kinetics and extent of protein tyrosine kinase activation in individual T cells upon antigenic stimulation". Immunology. 97 (2): 287–293. doi:10.1046/j.1365-2567.1999.00767.x. PMC 2326824. PMID 10447744.
- ↑ Emre N, Coleman R, Ding S (June 2007). "A chemical approach to stem cell biology". Curr Opin Chem Biol. 11 (3): 252–8. doi:10.1016/j.cbpa.2007.04.024. PMID 17493865.
- ↑ Vazin T, Freed WJ (2010). "Human embryonic stem cells: derivation, culture, and differentiation: a review". Restor. Neurol. Neurosci. 28 (4): 589–603. doi:10.3233/RNN-2010-0543. PMC 2973558. PMID 20714081.
- ↑ Chen S, Do JT, Zhang Q, Yao S, Yan F, Peters EC, Schöler HR, Schultz PG, Ding S (November 2006). "Self-renewal of embryonic stem cells by a small molecule". Proc. Natl. Acad. Sci. USA. 103 (46): 17266–71. Bibcode:2006PNAS..10317266C. doi:10.1073/pnas.0608156103. PMC 1859921. PMID 17088537.
- ↑ Warashina M, Min KH, Kuwabara T, Huynh A, Gage FH, Schultz PG, Ding S (January 2006). "A synthetic small molecule that induces neuronal differentiation of adult hippocampal neural progenitor cells". Angew. Chem. Int. Ed. Engl. 45 (4): 591–3. doi:10.1002/anie.200503089. PMID 16323231.
- ↑ Egli D, Rosains J, Birkhoff G, Eggan K (2007). "Developmental reprogramming after chromosome transfer into mitotic mouse zygotes". Nature. 447 (7145): 679–85. Bibcode:2007Natur.447..679E. doi:10.1038/nature05879. PMID 17554301.
- ↑ Takahashi K, Yamanaka S (2006). "Induction of Pluripotent Stem Cells from Mouse Embryonic and Adult Fibroblast Cultures by Defined Factors". Cell. 126 (4): 663–76. doi:10.1016/j.cell.2006.07.024. PMID 16904174.
- ↑ Anastasia L, Pelissero G, Venerando B, Tettamanti G (2010). "Cell reprogramming: Expectations and challenges for chemistry in stem cell biology and regenerative medicine". Cell Death and Differentiation. 17 (8): 1230–7. doi:10.1038/cdd.2010.14. PMID 20168332.
- ↑ Chen S, Zhang Q, Wu X, Schultz PG, Ding S (2004). "Dedifferentiation of Lineage-Committed Cells by a Small Molecule". Journal of the American Chemical Society. 126 (2): 410–1. doi:10.1021/ja037390k. PMID 14719906.
- ↑ Chen S, Takanashi S, Zhang Q, Xiong W, Zhu S, Peters EC, Ding S, Schultz PG (June 2007). "Reversine increases the plasticity of lineage-committed mammalian cells". Proc. Natl. Acad. Sci. USA. 104 (25): 10482–7. Bibcode:2007PNAS..10410482C. doi:10.1073/pnas.0704360104. PMC 1965539. PMID 17566101.
- 1 2 3 Giepmans BNG, Adams SR, Ellisman MH, Tsien RY (2006). "The Fluorescent Toolbox for Assessing Protein Location and Function". Science. 312 (5771): 217–224. Bibcode:2006Sci...312..217G. doi:10.1126/science.1124618. PMID 16614209.
- ↑ Michalet X, Pinaud FF, Bentolila LA, Tsay JM, Doose S, Li JJ, Sundaresan G, Wu AM, Gambhir SS (2005). "Quantum Dots for Live Cells, in Vivo Imaging, and Diagnostics". Science. 307 (5709): 538–544. Bibcode:2005Sci...307..538M. doi:10.1126/science.1104274. PMC 1201471. PMID 15681376.
- ↑ Dave SR, Gao X (2009). "Monodisperse magnetic nanoparticles for biodetection, imaging, and drug delivery: a versatile and evolving technology". Wiley Interdiscip Rev Nanomed Nanobiotechnol. 1 (6): 583–609. doi:10.1002/wnan.51. PMID 20049819.
- ↑ Zinchuk V, Grossenbacher-Zinchuk O (2009). "Recent advances in quantitative colocalization analysis: Focus on neuroscience". Progress in Histochemistry and Cytochemistry. 44 (3): 125–72. doi:10.1016/j.proghi.2009.03.001. PMID 19822255.
- ↑ Galperin E, Verkhusha VV, Sorkin A (2004). "Three-chromophore FRET microscopy to analyze multiprotein interactions in living cells". Nature Methods. 1 (3): 209–17. doi:10.1038/nmeth720. PMID 15782196.
- ↑ Gaietta G, Deerinck TJ, Adams SR, Bouwer J, Tour O, Laird DW, Sosinsky GE, Tsien RY, Ellisman MH (2002). "Multicolor and Electron Microscopic Imaging of Connexin Trafficking". Science. 296 (5567): 503–507. Bibcode:2002Sci...296..503G. doi:10.1126/science.1068793. PMID 11964472.
- ↑ Terai T, Nagano T (2008). "Fluorescent probes for bioimaging applications". Current Opinion in Chemical Biology. 12 (5): 515–21. doi:10.1016/j.cbpa.2008.08.007. PMID 18771748.
Further reading
- Dertinger SKW, Chiu DT, Jeon NL, Whitesides GM (2001). "Generation of gradients having complex shapes using microfluidic networks". Analytical Chemistry. 73: 1240–1246. doi:10.1021/ac001132d.
- Greif D, Pobigaylo N, Frage B, Becker A, Regtmeier J, Anselmetti D (2010). "Space- and time-resolved protein dynamics in single bacterial cells observed on a chip". Journal of Biotechnology. 149 (4): 280–288. doi:10.1016/j.jbiotec.2010.06.003. PMID 20599571.
- Li L, Ismagilov RF (2010). "Protein crystallization using microfluidic technologies based on valves, droplets, and SlipChip". Annu Rev Biophys. 39: 139–58. doi:10.1146/annurev.biophys.050708.133630. PMID 20192773.
- Lucchetta EM, Lee JH, Fu LA, Patel NH, Ismagilov RF (2005). "Dynamics of Drosophila embryonic patterning network perturbed in space and time using microfluidics". Nature. 434 (7037): 1134–1138. Bibcode:2005Natur.434.1134L. doi:10.1038/nature03509. PMC 2656922. PMID 15858575.
- Melin J, Quake SR (2007). "Microfluidic large-scale integration: The evolution of design rules for biological automation". Annual Review of Biophysics and Biomolecular Structure. 36: 213–231. doi:10.1146/annurev.biophys.36.040306.132646. PMID 17269901.
- Shen F, Du WB, Kreutz JE, Fok A, Ismagilov RF (2010). "Digital PCR on a SlipChip". Lab on a Chip. 10 (20): 2666–2672. doi:10.1039/c004521g. PMC 2948063. PMID 20596567.
- Song H, Chen DL, Ismagilov RF (2006). "Reactions in droplets in microflulidic channels". Angewandte Chemie International Edition. 45: 7336–7356. doi:10.1002/anie.200601554. PMC 1766322. PMID 17086584.
- Spiller DG, Wood CD, Rand DA, White MRH (2010). "Measurement of single-cell dynamics". Nature. 465 (7299): 736–745. Bibcode:2010Natur.465..736S. doi:10.1038/nature09232. PMID 20535203.
- Tice JD, Song H, Lyon AD, Ismagilov RF (2003). "Formation of droplets and mixing in multiphase microfluidics at low values of the Reynolds and the capillary numbers". Langmuir. 19 (22): 9127–9133. doi:10.1021/la030090w.
- Vincent ME, Liu WS, Haney EB, Ismagilov RF (2010). "Microfluidic stochastic confinement enhances analysis of rare cells by isolating cells and creating high density environments for control of diffusible signals". Chemical Society Reviews. 39 (3): 974–984. doi:10.1039/b917851a. PMC 2829723. PMID 20179819.
- Weibel DB, Whitesides GM (2006). "Applications of microfluidics in chemical biology". Current Opinion in Chemical Biology. 10 (6): 584–591. doi:10.1016/j.cbpa.2006.10.016. PMID 17056296.
- Whitesides GM (2006). "The origins and the future of microfluidics". Nature. 442 (7101): 368–373. Bibcode:2006Natur.442..368W. doi:10.1038/nature05058. PMID 16871203.
- Young EWK, Beebe DJ (2010). "Fundamentals of microfluidic cell culture in controlled microenvironments". Chemical Society Reviews. 39 (3): 1036–1048. doi:10.1039/b909900j. PMC 2967183. PMID 20179823.
Journals
- ACS Chemical Biology – The new Chemical Biology journal from the American Chemical Society.
- Bioorganic & Medicinal Chemistry – The Tetrahedron Journal for Research at the Interface of Chemistry and Biology
- ChemBioChem – A European Journal of Chemical Biology
- Chemical Biology – A point of access to chemical biology news and research from across RSC Publishing
- Cell Chemical Biology – An interdisciplinary journal that publishes papers of exceptional interest in all areas at the interface between chemistry and biology. chembiol.com
- Journal of Chemical Biology – A new journal publishing novel work and reviews at the interface between biology and the physical sciences, published by Springer. link
- Journal of the Royal Society Interface – A cross-disciplinary publication promoting research at the interface between the physical and life sciences
- Molecular BioSystems – Chemical biology journal with a particular focus on the interface between chemistry and the -omic sciences and systems biology.
- Nature Chemical Biology – A monthly multidisciplinary journal providing an international forum for the timely publication of significant new research at the interface between chemistry and biology.
- Wiley Encyclopedia of Chemical Biology link