Overview
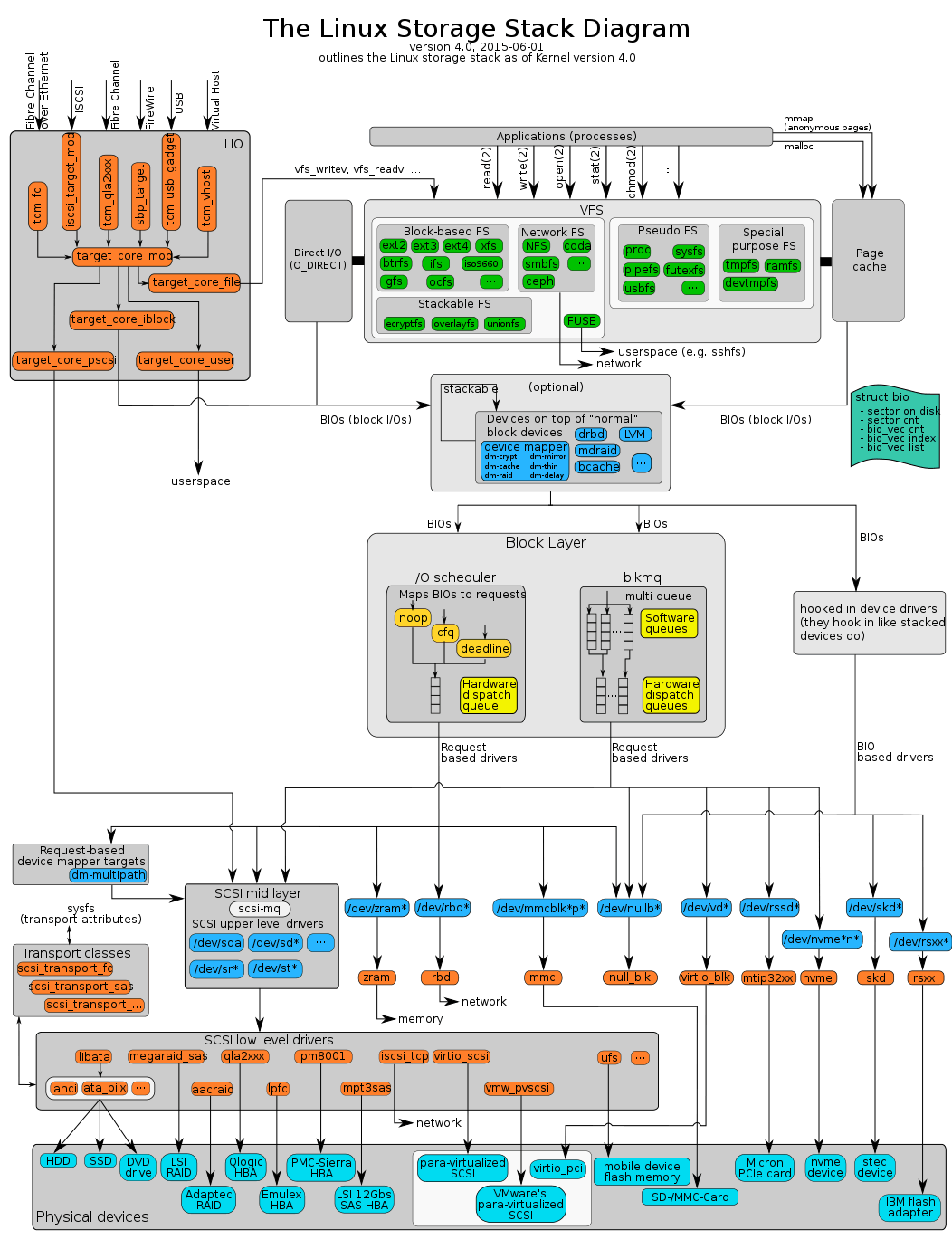
The two main areas of the Linux storage subsystem are the filesystems layer —including the virtual file system— and the storage devices support layer. Together, they implement how the kernel retrieves data from and stores data to secondary memory devices such as hard disks, magnetic tapes, optical discs or Flash memories.
The file system provides an abstraction to organize the information into separate pieces of data (called files) identified by an unique name. Each file system type defines their own structures and logic rules used to manage these groups of information and their names. Linux supports a plethora or different file system types, local and remote, native and from other operating systems. To accommodate such disparity the kernel defines a common top layer, the virtual file system (VFS) layer.
File systems
A file system (or filesystem) is used to control how data is stored and retrieved. Without a file system, information placed in a storage area would be one large body of data with no way to tell where one piece of information stops and the next begins. By separating the data into individual pieces, and giving each piece a name, the information is easily separated and identified. Each group of data is called a "file". The structure and logic rules used to manage the groups of information and their names is called a "file system".
There are many different kinds of file systems. Each one has different structure and logic, properties of speed, flexibility, security, size and more. Some file systems have been designed to be used for specific applications. For example, the ISO 9660 file system is designed specifically for optical discs.
File systems can be used on many different kinds of storage devices. Each storage device uses a different kind of media. The most common storage device in use today is a hard drive. Other media that are used are magnetic tape, optical disc, and flash memory. In some cases, the computer's main memory (RAM) is used to create a temporary file system for short-term use.
Linux supports many different file systems, but common choices for the system disk on a block device include the ext* family (such as ext2, ext3 and ext4), XFS, JFS (JFS, ReiserFS and btrfs. For raw Flash without a flash translation layer (FTL) or Memory Technology Device (MTD), there is UBIFS, JFFS2, and YAFFS, among others. SquashFS is a common compressed read-only file system.
Virtual file system
functions
Page cache
A page cache or disk cache is a transparent cache for the memory pages originating from a secondary storage device such as a hard disk drive. The operating system keeps a page cache in otherwise unused portions of the main memory, resulting in quicker access to the contents of cached pages and overall performance improvements. The page cache is implemented by the kernel, and is mostly transparent to applications.
Usually, all physical memory not directly allocated to applications is used by the operating system for the page cache. Since the memory would otherwise be idle and is easily reclaimed when applications request it, there is generally no associated performance penalty and the operating system might even report such memory as "free" or "available".
The page cache also aids in writing to a disk. Pages in the main memory that have been modified during writing data to disk are marked as "dirty" and have to be flushed to disk before they can be freed. When a file write occurs, the page backing the particular block is looked up. If it is already found in the page cache, the write is done to that page in the main memory. Otherwise, when the write perfectly falls on page size boundaries, the page is not even read from disk, but allocated and immediately marked dirty. Otherwise, the page(s) are fetched from disk and requested modifications are done.
Not all cached pages can be written to as program code is often mapped as read-only or copy-on-write; in the latter case, modifications to code will only be visible to the process itself and will not be written to disk.
Block device layer
Linux storage is based on block devices.
Block devices provide buffered access to the hardware, always allowing to read or write any sized block (including single characters/bytes) and are not subject to alignment restrictions. They are commonly used to represent hardware like hard disks.
Device mapper
The device mapper is a framework provided by the kernel for mapping physical block devices onto higher-level "virtual block devices". It forms the foundation of LVM2, software RAIDs and dm-crypt disk encryption, and offers additional features such as file system snapshots.
Device mapper works by passing data from a virtual block device, which is provided by the device mapper itself, to another block device. Data can be also modified in transition, which is performed, for example, in the case of device mapper providing disk encryption.
User space applications that need to create new mapped devices talk to the device mapper via the libdevmapper.so shared library, which in turn issues ioctls to the /dev/mapper/control device node.
Functions provided by the device mapper include linear, striped and error mappings, as well as crypt and multipath targets. For example, two disks may be concatenated into one logical volume with a pair of linear mappings, one for each disk. As another example, crypt target encrypts the data passing through the specified device, by using the Linux kernel's Crypto API.
The following mapping targets are available:
- cache - allows the creation of hybrid volumes, by using solid-state drives (SSDs) as caches for hard disk drives (HDDs)
- crypt - provides data encryption, by using the Linux kernel's Crypto API
- delay - delays reads and/or writes to different devices (used for testing)
- era - behaves in a way similar to the linear target, while it keeps track of blocks that were written to within a user-defined period of time
- error - simulates I/O errors for all mapped blocks (used for testing)
- flakey - simulates periodic unreliable behaviour (used for testing)
- linear - maps a continuous range of blocks onto another block device
- mirror - maps a mirrored logical device, while providing data redundancy
- multipath - supports the mapping of multipathed devices, through usage of their path groups
- raid - offers an interface to the Linux kernel's software RAID driver (md)
- snapshot and snapshot-origin - used for creation of LVM snapshots, as part of the underlining copy-on-write scheme
- striped - strips the data across physical devices, with the number of stripes and the striping chunk size as parameters
- zero - an equivalent of
/dev/zero, all reads return blocks of zeros, and writes are discarded
I/O scheduler
I/O scheduling (or disk scheduling) is the method chosen by the kernel to decide in which order the block I/O operations will be submitted to the storage volumes. I/O scheduling usually has to work with hard disk drives that have long access times for requests placed far away from the current position of the disk head (this operation is called a seek). To minimize the effect this has on system performance, most I/O schedulers implement a variant of the elevator algorithm that reorders the incoming randomly ordered requests so the associated data would be accessed with minimal arm/head movement.
From 2.6.x series onwards the Linux kernel supports 3 different I/O schedulers (also known as elevators): NOOP, deadline and CFQ, being the latter the default choice for every block device since version 2.6.18. The default I/O scheduler can be changed at compile time or using the elevator= boot parameter. The particular I/O scheduler used with certain block device can be switched at run time by modifying the corresponding /sys/block/<block_device>/queue/scheduler file in the sysfs filesystem. Some I/O schedulers also have tunable parameters that can be set through files in /sys/block/<block_device>/queue/iosched/.
NOOP scheduler
The NOOP scheduler is the simplest I/O scheduler for the Linux kernel. This scheduler inserts all incoming I/O requests into a simple FIFO queue and implements request merging. This scheduler is useful when it has been determined that the host should not attempt to re-order requests based on the sector numbers contained therein. In other words, the scheduler assumes that the host is definitionally unaware of how to productively re-order requests.
Deadline scheduler
The main goal of the deadline scheduler is to guarantee a start service time for a request. It does so by imposing a deadline on all I/O operations to prevent starvation of requests. It also maintains two deadline queues, in addition to the sorted queues (both read and write). Deadline queues are basically sorted by their deadline (the expiration time), while the sorted queues are sorted by the sector number.
Before serving the next request, the deadline scheduler decides which queue to use. Read queues are given a higher priority, because processes usually block on read operations. Next, the deadline scheduler checks if the first request in the deadline queue has expired. Otherwise, the scheduler serves a batch of requests from the sorted queue. In both cases, the scheduler also serves a batch of requests following the chosen request in the sorted queue.
By default, read requests have an expiration time of 500 ms, write requests expire in 5 seconds.
Completely Fair Queuing
Completely Fair Queuing (CFQ) I/O scheduler places synchronous requests submitted by processes into a number of per-process queues and then allocates timeslices for each of the queues to access the disk. The length of the time slice and the number of requests a queue is allowed to submit depends on the I/O priority of the given process. Asynchronous requests for all processes are batched together in fewer queues, one per priority. While CFQ does not do explicit anticipatory I/O scheduling, it achieves the same effect of having good aggregate throughput for the system as a whole, by allowing a process queue to idle at the end of synchronous I/O thereby "anticipating" further close I/O from that process. It can be considered a natural extension of granting I/O time slices to a process.
CQF implements ioprio_get() and ioprio_set() system calls, which allows an user to set per-process I/O priorities, usually using ionice command (although using nice also modifies I/O priorities somewhat).